for(int i = 0; i < rows; i++)
{
for(int j = 0; j < cols; j++)
{
process(arr[i][j]);
}
}(Row-major)
for(int j = 0; j < cols; j++)
{
for(int i = 0; i < rows; i++)
{
process(arr[i][j]);
}
}(Col-major)
Before We Begin
When learning to write nested for loops in code, many people never stop to ask why the row (horizontal) comes first and the column (vertical) comes second.
Yet in fields outside of software engineering, such as pure science or data science,
there are languages that use Col-major order.
So why did the major languages end up with Row-major as the default?

The answer is laid out in detail in one of the greatest books on computer systems ever written: Computer Systems: A Programmer's Perspective.
First, we need to understand what a CPU cache is.
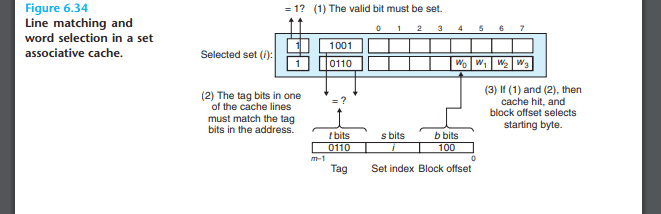
What is a Cache?
A cache stores memory data in units called blocks,
where each block is generally between 32 and 128 bytes in size,
and each block is composed of a tag, an index, and an offset.
Tag: The upper bits of the memory address, used to identify which memory address a cache block is storing.
Index: Specifies the position of a block within the cache.
Offset: Selects a specific byte within the block.
When a memory access request comes in, the cache checks whether the data at that address is already present. If the data is found, it is called a cache hit; if it is not found, it is called a cache miss.
In general, when a cache miss occurs (meaning the requested data is not in the cache), the entire cache block containing that data is loaded from memory into the cache.
A larger cache block size allows better exploitation of spatial locality, but it also increases the miss penalty because more data must be loaded on each miss.

Memory Layout of C Arrays
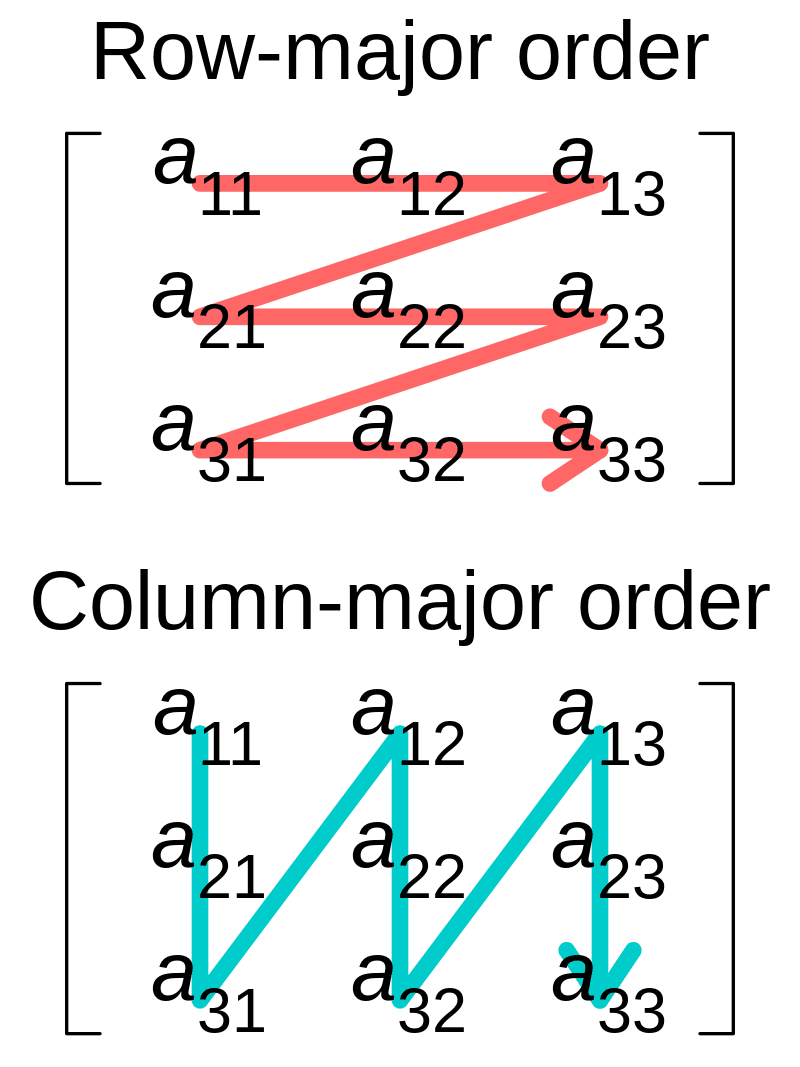
As covered in Chapter 3 of the book, in C, all elements of an array are allocated contiguously in memory. The address of each element is spaced apart from the base address by multiples of the data type size (L). For multidimensional arrays, this contiguous allocation happens row by row, which is known as Row-major order.
That is, a[0][0], a[0][1], a[0][2], ... are stored side by side in memory.
Combining These Two Facts
A cache block fetches an entire contiguous range of memory addresses at once, and an array is stored contiguously row by row. Therefore, a single cache block will contain some (or all) of the consecutive elements from the same row.
This is why row-major access is cache-friendly.
Cache Behavior of Row-major Access a[i][j]
for(int i = 0; i < rows; i++)
{
for(int j = 0; j < cols; j++)
{
process(arr[i][j]);
}
}(Cache-friendly row-major code)
The moment you access a[0][0], the cache loads the entire block containing that address. If the block size is 16 bytes and each element is a 4-byte int, then the four elements from a[0][0] through a[0][3] are brought in at once.
Subsequent accesses to a[0][1], a[0][2], and a[0][3] are all hits because those elements are already in the cache. A cache miss occurs only once per block, and the miss rate converges to 1/B (where B is the number of elements per block).
Cache Behavior of Column-major Access a[j][i]
for(int j = 0; j < cols; j++)
{
for(int i = 0; i < rows; i++)
{
process(arr[i][j]);
}
}(Column-major code)
After accessing a[0][0], the next access is a[1][0]. These two elements belong to different rows, so they are far apart in memory. Because they fall in different cache blocks, a miss occurs on every single access.
If the array size exceeds the cache capacity, by the time the loop returns to the row containing a[0][0], that data will have already been evicted, causing another miss. In the worst case, the miss rate approaches 100%.
(A simplified visualization of the examples above)
So What About Col-major Languages?
If arrays in C-family languages are stored in Row-major order, making a[i][j] access patterns cache-friendly, then why do Fortran and MATLAB access arrays in the a[j][i] order?
Because Fortran and MATLAB store arrays in column-major order.
The cache memory itself simply reads contiguous blocks of memory (cache lines). The cache has no knowledge of whether the storage is Row-major or Col-major. What matters is only the contiguity in memory, that is, the order in which the array's elements are stored.
Therefore, depending on how each language stores its arrays, the key to cache efficiency lies in choosing whether the outer loop of a nested for loop iterates over rows or columns.
Why the Split? Engineering vs. Science
The reason C adopted Row-major order comes down to its natural fit with pointer arithmetic. When computing the address of a[i][j] as base + (i * cols + j) * sizeof(element), Row-major order aligns naturally with both the notation and the arithmetic.
The reason Fortran and MATLAB adopted Col-major order is rooted in the conventions of linear algebra. In mathematics, vectors are overwhelmingly written as column vectors, and matrix operations frequently involve column-wise access. Storing arrays in column-major order means the mathematical notation and the memory layout correspond directly.
To summarize: languages closer to engineering (C, C++, C#, Java, Python NumPy by default) tend to use Row-major, while languages closer to science (Fortran, MATLAB, Julia, R) tend to use Col-major.
Going Further: Beyond Passive Caches, the CPU's Active Role (Hardware Prefetcher)
Everything discussed so far describes older CPUs. The real reason modern CPUs achieve overwhelming speed in row-major traversal is that the cache is no longer just a passive storage unit.
Inside the CPU lives a hardware prefetcher that monitors and predicts memory access patterns in real time. As soon as code begins accessing memory sequentially row by row (Stride-1 Access), the prefetcher immediately recognizes the pattern: "this code is scanning memory in a straight line." Before the CPU even requests a[0][4], the prefetcher reaches through the memory controller and pulls the next cache block into the L1 cache ahead of time (prefetching).
This is no coincidence.
Modern CPU hardware prefetchers are designed from the ground up to treat Stride-1, that is, sequential memory access, as their top optimization target. The vast majority of code in the world is written in C, C++, or Java, and all of these languages use Row-major arrays. This means the prefetcher's priorities are themselves tuned to Row-major access patterns.
In other words, row-major traversal goes beyond mere spatial locality; it fits perfectly into the CPU's predictive pipeline.
If modern CPU prefetchers are that smart, couldn't they predict column-major traversal as well, since the stride is a fixed, regular pattern?
That's a fair point. The latest Intel and AMD architectures include a dedicated unit called the Stride Prefetcher, which can detect that the gap between memory accesses is constant after just a few loop iterations and precompute the next addresses. A pattern like arr[0][0] → arr[1][0] → arr[2][0], repeating at intervals of rows * sizeof(int), is absolutely detectable by the prefetcher.
Even so, column-major traversal cannot beat row-major traversal, due to two physical limitations.
1. The 4 KB Page Boundary Wall
The prefetcher is hardwired to avoid crossing virtual memory page boundaries (typically 4 KB). If it blindly prefetched data from the next page without authorization, the resulting page fault or TLB miss would trigger OS intervention and stall the entire CPU pipeline.
The larger the array, the wider the stride in column-major access, and the prefetcher hits this boundary after only a few predictions, forcing it to stop.
2. Bandwidth Waste and Cache Pollution
Suppose the prefetcher predicts perfectly and delivers data right on time. Inside the loop, the CPU actually needs just one 4-byte integer: arr[1][0]. However, the cache controller always operates in units of 64 bytes (one cache line).
Actual required data: 4 bytes
Data loaded due to cache line size: 64 bytes
→ 93.75% of the bandwidth is wasted fetching unused (garbage) dataThose wasted 60 bytes get loaded into the cache and immediately evict useful data that was already there. This is cache pollution. No matter how diligently the prefetcher ferries data in, it inevitably hits the physical limit where the memory bus itself becomes saturated.
So Does That Mean Row-major Is Always the Right Choice?
No.
The prefetcher can only identify regularity in addresses; it cannot compensate for the bandwidth waste that such regularity causes.
The core principle is this: to consume all 64 bytes of a cache line without waste, the access order must match the storage order. C stores arrays in row-major order, so you must access them row by row; Fortran and MATLAB store arrays in column-major order, so you must access them column by column. The storage order differs, but when you access data according to your language's array layout, both approaches exploit the prefetcher 100% and consume cache lines without waste.
Column-major order is not inherently bad.
What is bad is accessing data in column-major order in C.
And likewise, accessing data in row-major order in MATLAB is also bad.
Closing Thoughts...
When writing a nested for loop, having i on the outside and j on the inside is not merely a convention. That ordering comes from how the language stores its arrays, and the storage order is directly tied to how the cache hardware operates.
The next time you write a nested for loop, why not pause for a moment and ask: "In what order does this language store its arrays?".