GC (Garbage Collection) Fundamentals: An Introduction
What Exactly Is Garbage Collection?

Memory Management Approaches: Manual Management and Garbage Collection
In programming languages, memory management approaches are commonly divided into two categories.
Manual and GC.
Manual Memory Management and automatic memory management (Garbage Collection, GC).
What is Manual Memory Management?
It is an approach where the developer directly manages memory allocation and deallocation.
In representative languages such as C and C++, developers manually allocate and deallocate memory using malloc/free, new/delete, and similar constructs.
The advantages include the ability for the programmer to have complete control over the timing of memory allocation and deallocation through precise control, and because performance is predictable, there is no unnecessary GC overhead.
Additionally, memory that is no longer needed can be freed immediately, conserving resources.
However, the drawbacks are that Memory Leaks exist, Dangling Pointers exist, and development becomes more complex.
*Memory Leak: a phenomenon where allocated memory is never freed and accumulates until the program terminates; it can cause a crash by exhausting system memory.
**Dangling Pointer: when already-freed memory is referenced, unpredictable behavior occurs.
More recently, Rust manages memory safely through an Ownership System as an alternative to manual memory management; this is considered not so much a form of fully manual memory management as a new alternative to it.
The Origins of Garbage Collection (1960)

*Free-Storage List.* At any given time only a part of the memory reserved for list structures will actually be in use for storing S-expressions. The remaining registers (in our system the number, initially, is approximately 15,000) are arranged in a single list called the *free-storage list*. A certain register, FREE, in the program contains the location of the first register in this list. When a word is required to form some additional list structure, the first word on the *free-storage list* is taken and the number in register FREE is changed to become the location of the second word on the free-storage list. No provision need be made for the user to program the return of registers to the free-storage list.
— John McCarthy, *Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I*
The starting point of GC is John McCarthy's paper Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I (1960). In this paper, McCarthy introduces the concept of a Free-Storage List, which becomes the core idea of GC.
Why Was This Concept Necessary?

(John McCarthy)
LISP (LISt Processor) was a high-level language that supported symbolic processing and recursion. Because it was structured to continuously create objects at runtime, the accumulation of no-longer-needed objects (garbage) in memory was a serious problem.
Moreover, with the computer technology of that era, memory management for LISP was an extremely complex and difficult challenge.
It was practically impossible for programmers to perfectly track every memory allocation and deallocation, and this is the background that gave rise to automatic memory management technology.
The Free-Storage List was the foundational concept for implementing automatic memory management in early LISP systems.
At the time, LISP dynamically created list structures, and it was difficult for programmers to explicitly free memory.
To address this, the concept of a Free-Storage List that tracks unused memory blocks evolved into the concept of automatic memory management.
The approach stores the starting position of the available memory list in a specific register (FREE), retrieves it when needed, and returns it when it is no longer in use. This idea later became the foundation for the Mark-and-Sweep GC.
(A detailed explanation of GC implementation methods and ideas will be covered in the next section.)

An important property of the Newell Shaw-Simon scheme for computer storage of lists is that data having multiple occurrences need not be stored at more than one place in the computer. That is, lists may be "overlapped." Unfortunately, overlapping poses a problem for subsequent erasure. Given a list that is no longer needed, it is desired to erase just those parts that do not overlap other lists. In LISP, McCarthy employs an elegant but inefficient solution to the problem. The present paper describes a general method which enables efficient erasure.
— George E. Collins, "A Method for Overlapping and Erasure of Lists" (1963)
Although John McCarthy's paper laid the groundwork for the Mark-and-Sweep approach, it had the drawback of causing a Stop-the-World pause, where the program halts during GC execution.
To address this, Collins proposed Reference Counting. This approach stores a reference count in each object and reclaims memory immediately the moment the count reaches zero. However, it had the limitation of being unable to handle Circular Reference problems, and modern languages such as Python and Swift use it with supplementary techniques added.
(As an aside, calling something "elegant but inefficient" makes me think, as it always has, that programmers seem to have a particular professional gift for "elegantly" mocking one another. Perhaps it's because they spend so much time talking about abstract concepts with no physical form that the possibility of actual physical repercussions fades from mind. Back in Korea, an expression like that would typically have earned you a very tangible response in the form of a fist.)
GC in a Virtual Memory Environment — Fenichel & Yochelson (1969)


In this paper a garbage-collection algorithm for list-processing systems which operate within very large virtual memo.ies is described. The object of the algorithm is more the compaction of active storage than the discovery of free storage. Because free storage is never really exhausted, the decision to garbage collect is not easily made; therefore, various criteria of this decision are discussed.
— Robert R. Fenichel and Jerome C. Yochelson, *A LISP Garbage-Collector for Virtual-Memory Computer Systems* (1969)
(Virtual Memory: a technology for logically managing large amounts of memory that exceed the capacity of physical memory)
This paper improves upon Minsky's Copying GC and describes a method for operating efficiently in a virtual memory environment.
The paper is a practical implementation of Minsky's garbage collector that uses depth-first search (DFS) to copy reachable data to auxiliary storage, assigns it to new contiguous addresses, and then loads it back into memory. While there was some criticism regarding its completeness,
this paper is landmark as the first to apply Copying GC based on Minsky's approach to a modern virtual memory environment, and without it, the concept of Generational GC in Java and C# would likely never have emerged.
Nonrecursive Copying GC — Cheney (1970)

A simple nonrecursive list structure compacting scheme or garbage collector suitable for both compact and LISP-like list structures is presented. The algorithm avoids the need for recursion by using the partial structure as it is built up to keep track of those lists that have been copied.
— C. J. Cheney, 1970
Cheney proposed a nonrecursive GC that uses breadth-first search (BFS) instead of DFS. Designed to perform GC without a separate stack, this approach has the advantages of eliminating stack overflow issues at the source and providing a cache-friendly structure.
This research would later have a significant influence on the Copying GC approach used today in Java, C#, and Python.
Why BFS, unlike DFS, is implemented non-recursively
The key lies in the difference in data structures the two traversal methods use.
DFS is a backtracking approach that dives as deep as possible in one direction before turning back. It is like exploring a cave by following one passage all the way to its end and then retracing your steps when you hit a dead end. To backtrack, you must remember the path you came through, which requires a stack or recursive calls. Because a stack is a LIFO (Last In, First Out) structure, you can retrieve nodes in reverse order, starting from the most recently visited, to implement backtracking.
BFS works differently. Think of splitting a team across a cave entrance, sweeping through every branch at the current level before moving down to the next. Because branches must be explored in the order they are discovered, a queue fits naturally, since a queue is a FIFO (First In, First Out) structure that processes items in arrival order and can complete the traversal using only a loop, with no recursive calls.
Now, to summarize a bit more simply for the reader:
How DFS works with a stack
Save the current node onto the stack (or via a recursive call).
If there is a next node to visit, continue by using the stack (or recursive call).
If there is nowhere left to go, execute backtracking.
Queue-Based Operation of BFS
Add the starting node to the queue (Enqueue).
Dequeue nodes one at a time, mark them as visited, and add their adjacent nodes back to the queue.
Repeat until all nodes have been explored.
Because a queue is used, no separate recursive calls are needed.
Using the cave exploration analogy, the contrast looks like this.
DFS: Follow one path all the way to its end; if the path is blocked, backtrack and explore a new one. The return route must always be remembered (stored).
BFS: Station a team at the entrance and explore every fork simultaneously, checking all paths on the current level before moving down to the next. Forks that are reached first are staffed first.
Summary Timeline of GC Development
Year | Researcher | GC Algorithm | Improvements | Drawbacks |
|---|---|---|---|---|
1960 | John McCarthy | Mark-and-Sweep | First introduction of the GC concept | Stop-the-World, fragmentation issues |
1963 | Marvin L. Minsky | Copying GC (DFS-based) | Resolves Memory Fragmentation, cache optimization | Circular Reference issues, disk usage |
1969 | Fenichel & Yochelson | Copying GC (Virtual Memory applied) | Uses two semispaces | Performance degradation under low memory conditions |
1970 | C. J. Cheney | Nonrecursive Copying GC (BFS-based) | GC can be performed without a stack | Memory relocation optimization is insufficient due to BFS-based traversal |
- Year
1960
- Researcher
John McCarthy
- GC Algorithm
Mark-and-Sweep
- Improvements
First introduction of the GC concept
- Drawbacks
Stop-the-World, fragmentation issues
- Year
1963
- Researcher
Marvin L. Minsky
- GC Algorithm
Copying GC (DFS-based)
- Improvements
Resolves Memory Fragmentation, cache optimization
- Drawbacks
Circular Reference issues, disk usage
- Year
1969
- Researcher
Fenichel & Yochelson
- GC Algorithm
Copying GC (Virtual Memory applied)
- Improvements
Uses two semispaces
- Drawbacks
Performance degradation under low memory conditions
- Year
1970
- Researcher
C. J. Cheney
- GC Algorithm
Nonrecursive Copying GC (BFS-based)
- Improvements
GC can be performed without a stack
- Drawbacks
Memory relocation optimization is insufficient due to BFS-based traversal
The key thread running through this history is the gradual reduction of the Stop-the-World problem, leading toward the development of concurrent (real-time) GC.
Overview of GC Algorithms
Before diving into the details, let's review some foundational concepts.
Memory is generally divided into two pools: Stack Memory and Heap Memory.
Stack Memory is primarily used to store data with short lifespans and small sizes (typically value types).
Heap Memory is primarily used to store data with longer lifespans and larger sizes (typically reference types).
GC algorithms fall broadly into two categories.
1. Tracing GC
This is the most widely used approach.
The criterion for determining whether a particular object is garbage is Reachability. Starting from roots (global variables, stack variables, etc.), the collector identifies objects that are reachable and frees those that are not. Objects with no valid references are classified as unreachable and collected.
There are three representative algorithms, each covered in order below.
The code samples attached below are pseudo code intended to illustrate core concepts and do not guarantee actual execution.
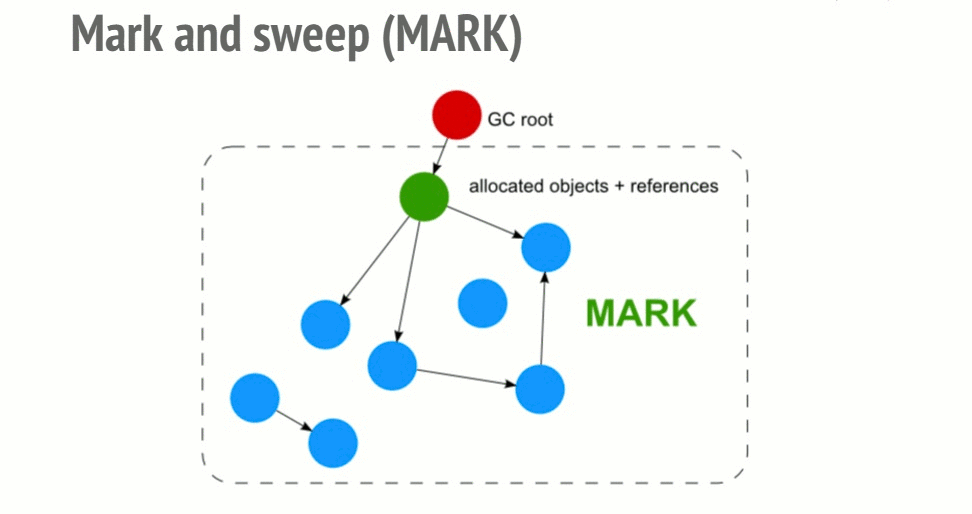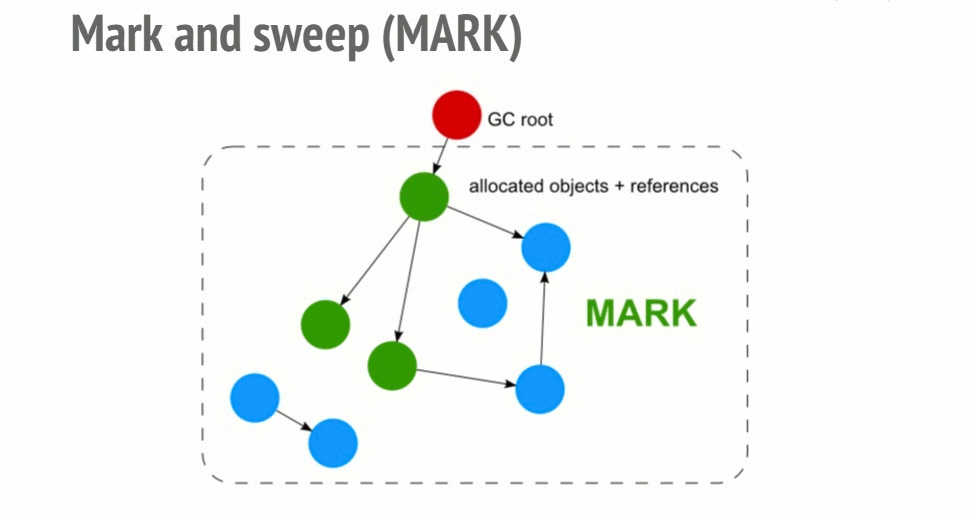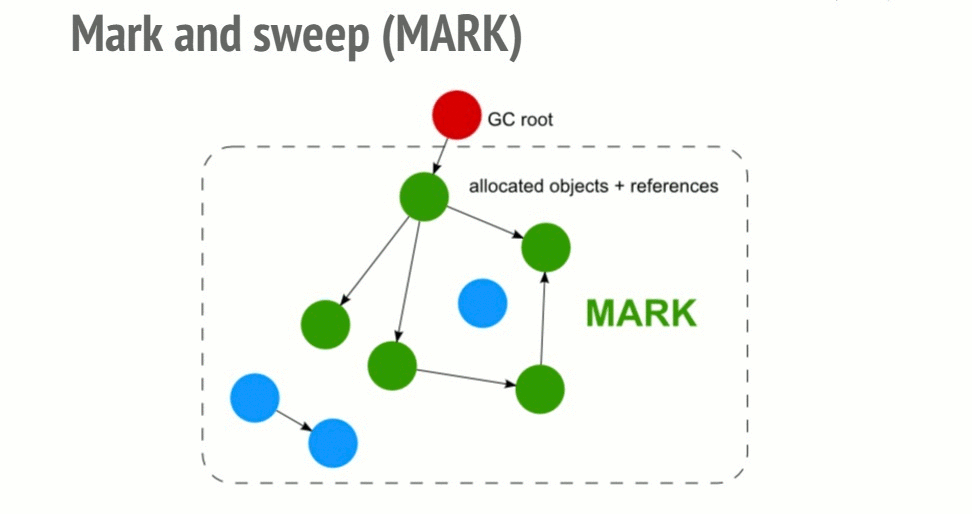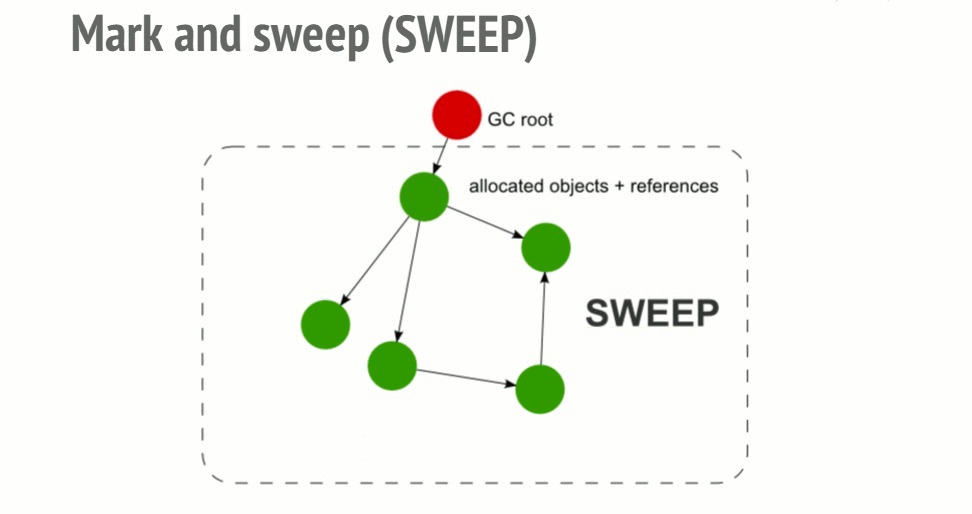
1-1. Mark-and-Sweep
(Image source: https://deepu.tech/memory-management-in-programming/)
When using shared_ptr in code following C++ RAII conventions, observing actual GC behavior is difficult, so raw pointers should be used instead.
#include <iostream>
#include <vector>
#include <algorithm>
// Mark-and-Sweep GC Implementation (Using Raw Pointers)
class Object {
public:
bool marked; // GC mark state
std::vector<Object*> children; // List of child objects
Object() : marked(false) {}
void addChild(Object* child) {
children.push_back(child);
}
// Destructor: prints a log when the object is deleted (for debugging)
~Object() {
std::cout << "Deleting Object at " << this << std::endl;
}
};
// Global heap and root object containers
std::vector<Object*> heap;
std::vector<Object*> roots;
// Recursively mark an object and its children
void mark(Object* obj) {
if (obj == nullptr || obj->marked) {
return;
}
obj->marked = true;
for (Object* child : obj->children) {
mark(child);
}
}
// Sweep phase: delete unmarked objects and remove them from the heap
void sweep() {
auto it = heap.begin();
while (it != heap.end()) {
Object* obj = *it;
if (!obj->marked) {
// Free unreachable objects
delete obj;
it = heap.erase(it);
} else {
// Reset marks for the next GC run
obj->marked = false;
++it;
}
}
// Update the root list: retain only objects still present in the heap
std::vector<Object*> newRoots;
for (Object* root : roots) {
if (std::find(heap.begin(), heap.end(), root) != heap.end()) {
newRoots.push_back(root);
}
}
roots = newRoots;
}
// Run GC: Mark then Sweep
void gc() {
for (Object* root : roots) {
mark(root);
}
sweep();
}
int main() {
// Create objects and register them in the heap
Object* a = new Object();
Object* b = new Object();
Object* c = new Object();
// Set up reference relationships between objects
a->addChild(b);
b->addChild(c);
heap.push_back(a);
heap.push_back(b);
heap.push_back(c);
// Set the root object (designate `a` as the root)
roots.push_back(a);
std::cout << "Heap size before GC: " << heap.size() << std::endl;
gc();
std::cout << "Heap size after GC: " << heap.size() << std::endl;
// Free remaining objects (in a real system, a final GC pass would handle this)
for (Object* obj : heap) {
delete obj;
}
heap.clear();
roots.clear();
return 0;
}Mark-and-Sweep is the foundational form of Tracing GC and has been the most widely used since McCarthy proposed it in 1960.
It operates in two phases.
1. Mark Phase
Starting from roots (global variables, stack variables, etc.), the collector follows references and sequentially marks all reachable objects. This process traverses the object graph recursively, and any object that is never visited remains unmarked.
2. Sweep Phase
The collector scans the entire heap, identifies objects that were not marked during the Mark phase (that is, objects unreachable from any root) as garbage, and frees their memory. Marked objects have their marks cleared in preparation for the next GC cycle and are retained.
The implementation is relatively straightforward, and because only objects that are actually referenced are preserved, memory can be managed without waste.
There are two drawbacks.
First, there is the Stop-the-World problem. To traverse the entire heap accurately during the Mark phase, object reference relationships must remain stable. As a result, all application threads must be completely halted while GC is running, and the larger the heap, the longer the pause.
Second, there is Memory Fragmentation. After objects are removed during the Sweep phase, the freed spaces are scattered throughout the heap. Even if the total size of these gaps is sufficient, a new object cannot be allocated if no single contiguous block of adequate size exists.
Memory fragmentation is divided into two types depending on where it occurs.
*Internal Fragmentation: This is unused space inside an allocated block. A representative example is when a 4 KB block is allocated but only 1 KB is actually used. It occurs frequently in allocation schemes that fix block sizes.
*External Fragmentation: This is a phenomenon in which available memory is scattered into small pieces, making it impossible to secure a contiguous block even though the total free space is sufficient. It worsens as objects are repeatedly created and freed.
1-2. Mark-Compact
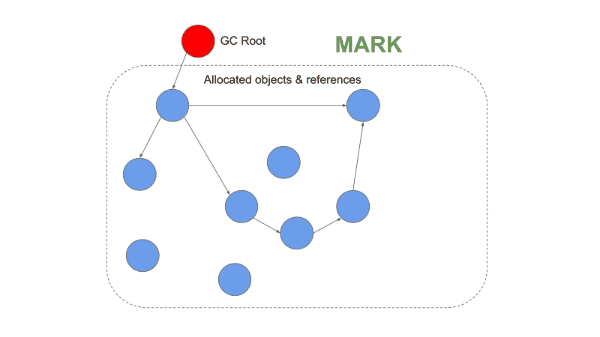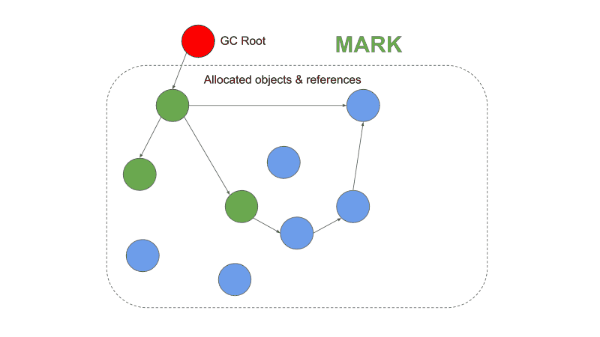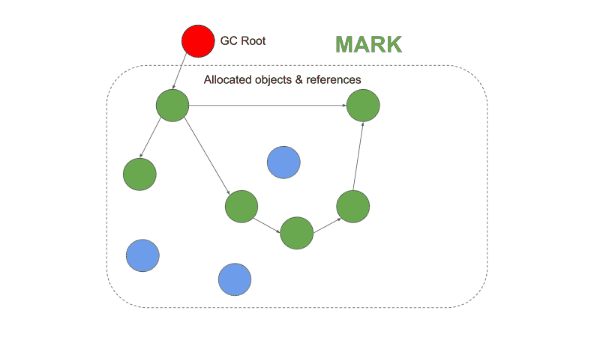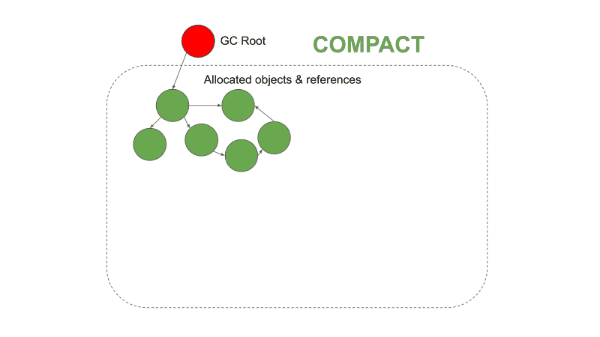
This approach was introduced to solve the fragmentation problem of Mark-and-Sweep. It operates identically up through the Mark phase, but differs in that it performs a Compaction phase instead of a Sweep.
It operates in three phases.
1. Mark Phase
Starting from the roots, reachable objects are marked, exactly as in Mark-and-Sweep.
2. Compact Phase
Surviving objects are packed in order toward one end of the heap. After each object is moved to its new address, all reference pointers that previously pointed to that object are updated.
3. Result
Objects are densely packed into a contiguous region of memory, and the remaining area is completely cleared. New objects can then be allocated sequentially starting from the beginning of the empty region, so fragmentation does not occur structurally.
The drawback is the cost of the Compaction process itself. Because objects must be physically moved, copy operations occur, and the reference pointers of every moved object must be updated one by one. The more live objects there are in the heap, the more objects need to be moved, causing GC pause times to grow longer than with Mark-and-Sweep.
1-3. Copying GC
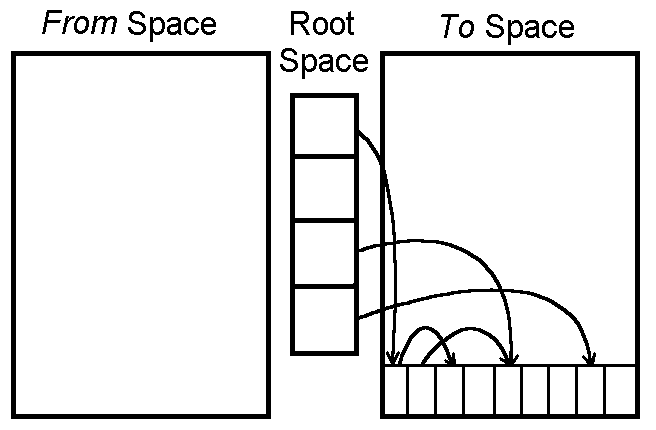
This approach manages the heap by dividing it into two equally sized regions, referred to as From Space and To Space. Under normal operation, objects are allocated only in From Space; when GC runs, only the reachable objects in From Space are copied to To Space. Once copying is complete, the roles of the two spaces are swapped, and the entire old From Space is cleared at once.
Unlike Mark-and-Sweep, which traverses the entire heap to find and remove garbage, Copying GC works by selecting only the live objects and moving them. Rather than handling garbage directly, it copies only what is alive, and everything else disappears automatically.
Because objects are placed compactly in To Space in sequential order, a contiguous block of free space is available after copying, with no fragmentation. Since allocating a new object requires nothing more than advancing a pointer, allocation is also fast.
The downside is that only half of the total heap can actually be used. The other half must always be kept empty as To Space, so memory utilization is structurally capped at 50%.
The code below uses placement new to manage the two semispaces directly. Because observing copy behavior is difficult when using shared_ptr, the implementation uses raw pointers instead.
#include <iostream>
#include <vector>
#include <algorithm>
#include <cstring>
constexpr std::size_t HEAP_SIZE = 1024;
// Object class (simple linked-list structure)
class Object {
public:
int value;
Object* next;
explicit Object(int val) : value(val), next(nullptr) {}
// Destructor (for debugging)
~Object() {
std::cout << "Deleting Object with value "
<< value << " at " << this << std::endl;
}
};
// Memory management with two semispaces
std::vector<char> fromSpace(HEAP_SIZE);
std::vector<char> toSpace(HEAP_SIZE);
std::size_t fromIndex = 0;
std::size_t toIndex = 0;
// Allocate object in the specified space (using placement new)
Object* allocate(int val, std::vector<char>& space, std::size_t& idx) {
if (idx + sizeof(Object) > space.size()) {
return nullptr; // Out of space
}
Object* obj = new (&space[idx]) Object(val);
idx += sizeof(Object);
return obj;
}
// Recursively copy the object and its connected objects
Object* copy(Object* obj, std::vector<char>& targetSpace, std::size_t& targetIdx) {
if (obj == nullptr) {
return nullptr;
}
Object* newObj = allocate(obj->value, targetSpace, targetIdx);
if (newObj == nullptr) {
return nullptr;
}
newObj->next = copy(obj->next, targetSpace, targetIdx);
return newObj;
}
// Run Copying GC: copy reachable objects to the new space
void gc(Object*& root) {
toIndex = 0;
Object* newRoot = copy(root, toSpace, toIndex);
// Swap spaces: use the copied space as the new heap
std::swap(fromSpace, toSpace);
fromIndex = toIndex;
root = newRoot;
}
int main() {
// Allocate objects in fromSpace
Object* a = allocate(10, fromSpace, fromIndex);
if (a == nullptr) {
std::cerr << "Allocation failed for object a." << std::endl;
return 1;
}
Object* b = allocate(20, fromSpace, fromIndex);
if (b == nullptr) {
std::cerr << "Allocation failed for object b." << std::endl;
return 1;
}
a->next = b;
std::cout << "Before GC, root object value: " << a->value << std::endl;
gc(a);
std::cout << "After GC, copied root object value: " << a->value << std::endl;
return 0;
}2. Reference Counting GC
If the Tracing GC family discussed earlier works by "finding reachable objects," Reference Counting takes the opposite approach: it tracks in real time how many places currently hold a reference to each object. The count is incremented each time an object is referenced and decremented each time a reference is dropped. The moment the count reaches zero, the object is considered no longer in use and its memory is freed immediately.
A reference count is stored in each object, and the moment that count reaches zero its memory is freed immediately. Because objects can be reclaimed right away, Stop-the-World pauses do not occur, and there is the added benefit of being able to see explicitly how many references each object has at any given time.
There are two drawbacks. In a Circular Reference situation where two objects reference each other, the count never reaches zero, so the memory is never reclaimed. In addition, as the number of objects grows, the accumulated overhead of updating reference counts degrades performance.
Swift addresses these issues with ARC (Automatic Reference Counting).
The code below uses a global reference table unordered_map to initialize the reference count to 1 when an object is created, adjusts the count through addRef and releaseRef, and calls delete when the count reaches zero.
#include <iostream>
#include <unordered_map>
// A simple object class that holds a value
class Object {
public:
int value;
explicit Object(int val) : value(val) {}
// Destructor: called when the object is freed
~Object() {
std::cout << "Deleting Object with value "
<< value << " at " << this << std::endl;
}
};
// Global reference count table: maps object pointers to reference counts
std::unordered_map<Object*, int> refTable;
// Object creation: initializes the reference count to 1 and returns the object
Object* createObject(int val) {
Object* obj = new Object(val);
refTable[obj] = 1;
return obj;
}
// Increment reference: increases the reference count in `refTable`
void addRef(Object* obj) {
if (obj != nullptr) {
auto it = refTable.find(obj);
if (it != refTable.end()) {
++it->second;
}
}
}
// Release reference: decrements the reference count, and frees memory when it reaches 0
void releaseRef(Object* obj) {
if (obj != nullptr) {
auto it = refTable.find(obj);
if (it != refTable.end()) {
if (--(it->second) == 0) {
refTable.erase(it);
delete obj;
}
}
}
}
int main() {
// Object creation (each initialized with a reference count of 1)
Object* a = createObject(10);
Object* b = createObject(20);
// Increment reference to `b` (assuming `b` is referenced from multiple places)
addRef(b);
// Release reference to `b`: called twice so the reference count reaches 0 and memory is freed
releaseRef(b);
releaseRef(b);
// Release reference to `a`: memory is freed
releaseRef(a);
std::cout << "Remaining objects in refTable: "
<< refTable.size() << std::endl;
return 0;
}Comparing Tracing GC and Reference Counting GC
Category | Tracing GC | Reference Counting GC |
|---|---|---|
Core Concept | Traces reachable objects starting from roots and frees the rest | Memory is freed immediately when the reference count drops to 0 |
Circular Reference | Handled automatically by GC | Count never reaches 0, causing Memory Leak |
GC Execution Cost | Proportional to the number of objects and the size of the reference graph | The more objects there are, the greater the overhead of updating counts |
Stop-the-World | Program pauses during GC execution | Immediate release, no pauses |
Representative Languages | C#, Java, Python | Objective-C (ARC), Swift |
- Category
Core Concept
- Tracing GC
Traces reachable objects starting from roots and frees the rest
- Reference Counting GC
Memory is freed immediately when the reference count drops to 0
- Category
Circular Reference
- Tracing GC
Handled automatically by GC
- Reference Counting GC
Count never reaches 0, causing Memory Leak
- Category
GC Execution Cost
- Tracing GC
Proportional to the number of objects and the size of the reference graph
- Reference Counting GC
The more objects there are, the greater the overhead of updating counts
- Category
Stop-the-World
- Tracing GC
Program pauses during GC execution
- Reference Counting GC
Immediate release, no pauses
- Category
Representative Languages
- Tracing GC
C#, Java, Python
- Reference Counting GC
Objective-C (ARC), Swift
With this, we have covered both families of fundamental GC algorithms. The following sections discuss optimization strategies built on top of these algorithms.
Optimization Strategies
1. Generational GC
This is the most widely known GC optimization strategy.
GC is performed by dividing objects into the Young Generation and the Old Generation based on their survival duration. Newly created objects (Young) are collected quickly, while long-lived objects (Old) are collected relatively less frequently. The premise of this strategy is straightforward: the empirical observation that most objects die shortly after creation, known as the Weak Generational Hypothesis.
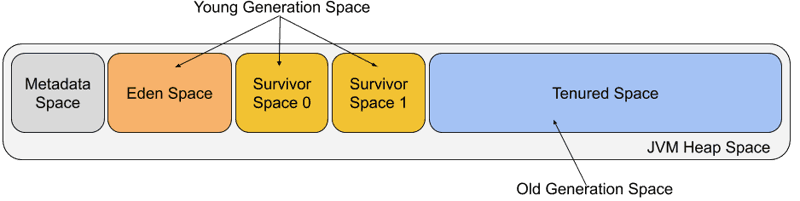
Young Generation (Eden + Survivor Space)
Eden Space
This is where newly created objects are first allocated. Because most objects are created and then quickly discarded in this area, GC occurs frequently here.
Survivor Space
This is the space where objects that survive GC in the Eden area are moved. The Survivor space is generally divided into two regions, applying the same From Space / To Space structure of the Copying GC described earlier. Survivor 0 acts as the From Space and Survivor 1 acts as the To Space. Objects that have passed through GC multiple times are promoted to the Old Generation.
When objects are collected from the Young Generation, it is called a Minor GC. Because Copying GC is used, it is processed quickly.
Old Generation (Tenured Space)
This is the space where objects that have repeatedly survived GC in the Young Generation are moved. GC occurs less frequently here, but when it does occur, the number of target objects is large and the processing cost is high. The space is reclaimed using Mark-and-Sweep or Mark-Compact, and a Stop-the-World pause may accompany a GC event.
When objects are collected from the Old Generation, it is called a Major GC (or Full GC).
The Old generation is generally allocated a larger size than the Young generation. Because the region is larger, it takes longer to fill up, resulting in less frequent GC.
An Analogy to Human Life
This structure can be compared to the stages of a human life as follows.
1. Dwelling in Eden as a soul,
2. one is called into the world and born.
3. One endures the trials of the world and survives (Survivor), making it through without incident,
4. growing old and earning the respect of society (Promotion).
5. When that elder passes away, far more people mourn than they would for the death of a young person. This illustrates why the GC cost for the Old Generation is greater.
2. Parallel GC
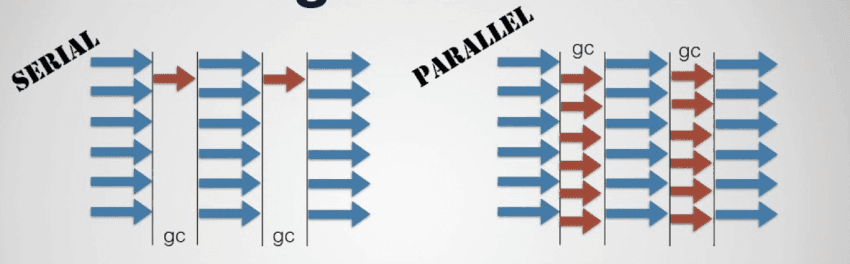
Parallel GC improves throughput by using multiple threads simultaneously to perform garbage collection in parallel. When GC is performed on a single thread, pause time grows linearly as the heap grows larger; by having multiple threads partition the heap and process it concurrently, that time can be reduced. This approach is especially effective for large-scale applications that manage large heaps.
The downside is synchronization overhead between threads. Because multiple threads traversing the heap and collecting objects simultaneously must be coordinated to avoid overlapping work areas, synchronization costs increase as the number of threads grows.
Generational GC and Parallel GC are not mutually exclusive. Dividing memory into generations and performing GC in parallel are independent strategies that can be applied together, and in practice both the Java HotSpot JVM and the .NET runtime combine the two.
Beyond these, the field has evolved into the Concurrent GC family aimed at minimizing Stop-the-World pauses, with Java's G1 GC and ZGC being prominent examples.
How Is GC Executed?

1. Stop-the-World GC
This is the traditional approach in which all application threads are completely halted when GC runs. Because the entire heap is traversed in a paused state, the implementation is straightforward and precise memory reclamation is possible. The downside is that the application becomes unresponsive while GC is running, and the larger the heap, the longer the pause, degrading the user experience.
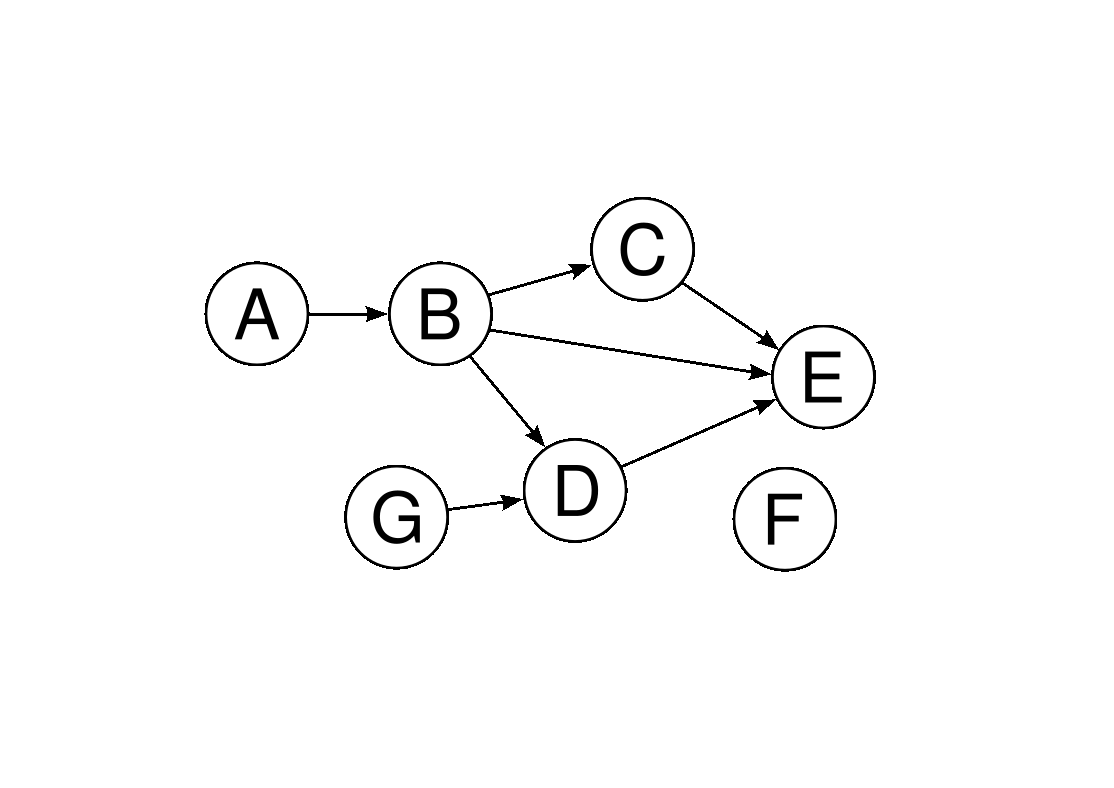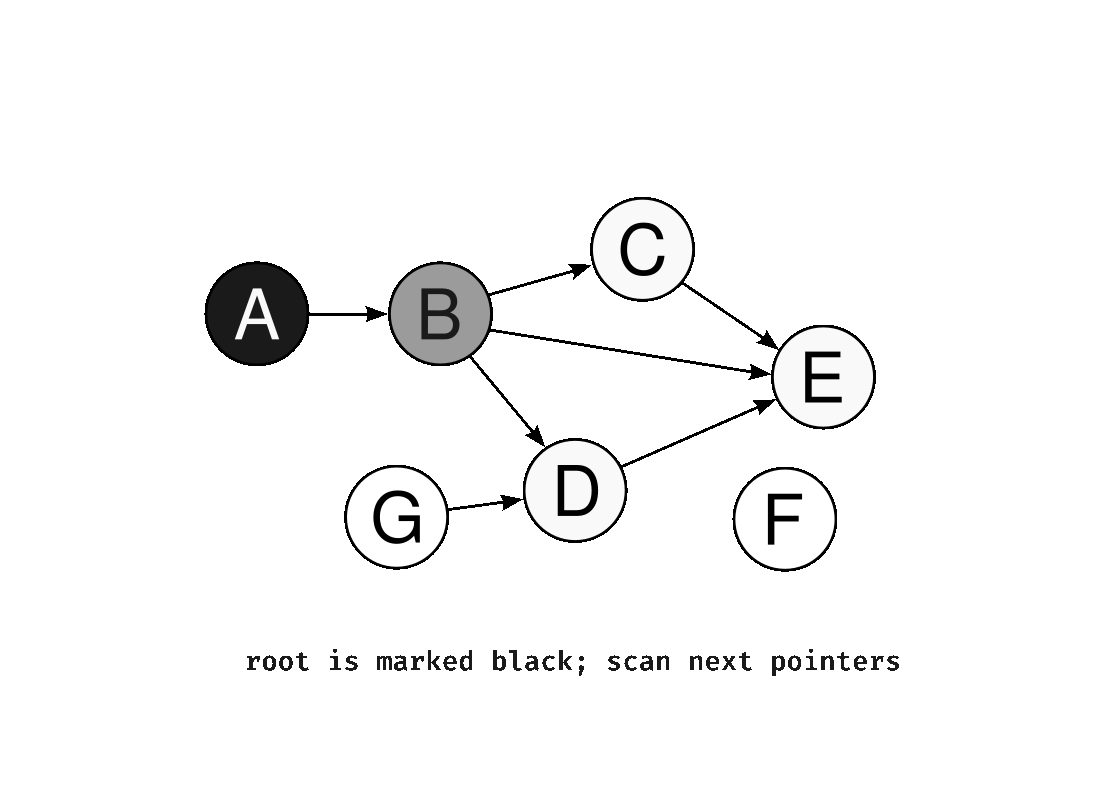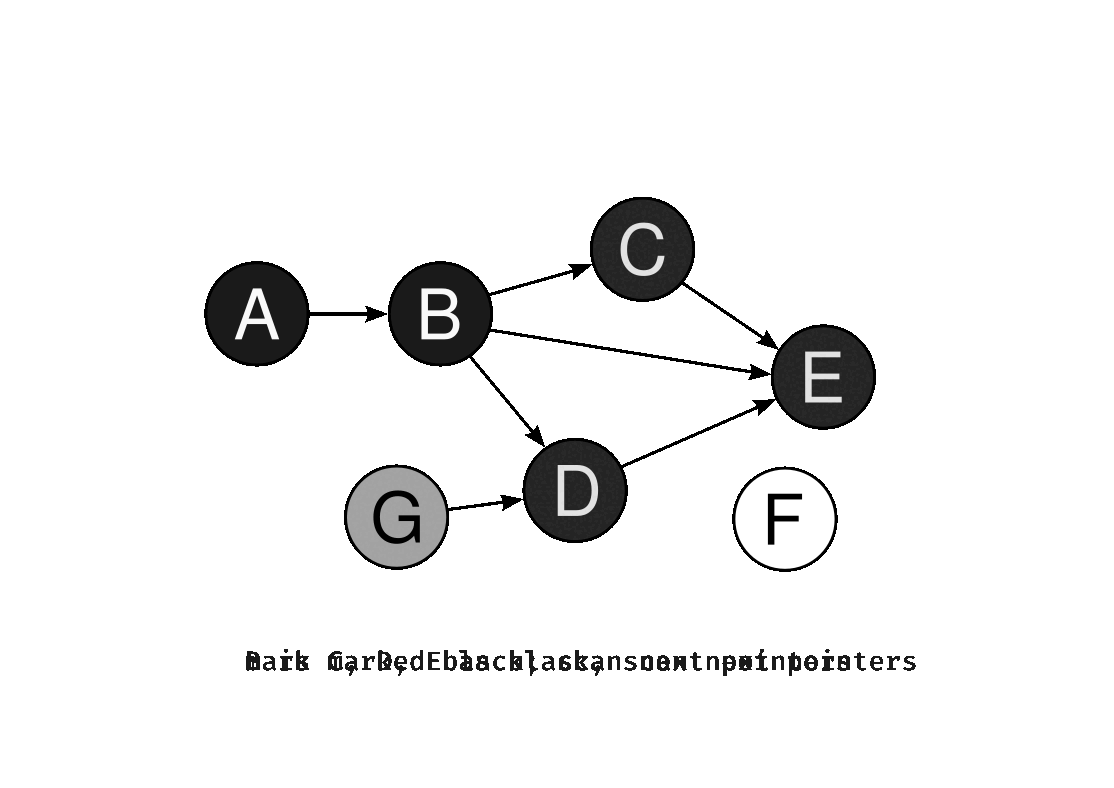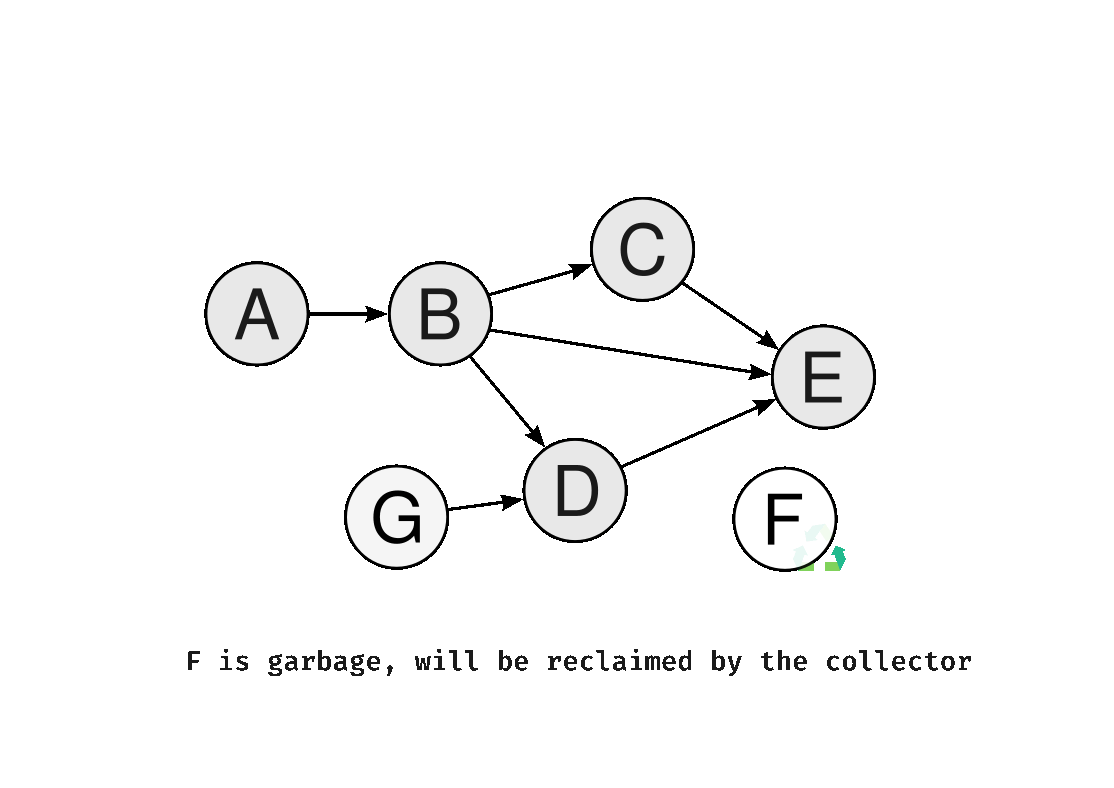
2. Incremental GC
Rather than completing GC in a single pass, Incremental GC divides the work into many small steps and executes them in turns. Because GC and the application alternate execution, each individual pause is kept short.
It is implemented based on Dijkstra's Tri-Color Marking Algorithm. This algorithm classifies all objects into three states to track the progress of processing.
White: Objects that have not yet been visited. Any object that remains white after GC completes is unreachable garbage.
Gray: Objects that have been visited but whose child objects have not yet been processed. This indicates that work still remains.
Black: Objects whose visit is complete and whose child objects have all been processed. These are confirmed to be alive.
The sequence of operations is as follows.
1. Initialize all objects to white.
2. Mark objects referenced from roots as gray and add them to the queue.
3. Take gray objects out one by one, mark their child objects gray, then change the current object to black.
4. Repeat until there are no more gray objects. Collect any remaining white objects.
The key invariant here is that a black object never directly references a white object. Because black represents a completed state, if a black object directly points to a white object, that white object can never pass through the gray state and risks being incorrectly collected as garbage. As long as this invariant is maintained, correctness is guaranteed even when GC is divided into multiple steps.
3. Concurrent GC
In this approach, GC threads and application threads run simultaneously to minimize Stop-the-World pauses. A dedicated GC thread operates separately, performing tasks such as marking or copying even while the application is running. Because it can take advantage of multiple cores, it is well suited for large-scale applications.
The downside is that memory management becomes complex because object reference relationships keep changing while the application is running. To address this, a Write Barrier is added on top of the Tri-Color algorithm described above, so that whenever a reference relationship changes, any violation of the color invariant is corrected. Java's G1 GC, ZGC, and .NET's Background GC all adopt this approach.
(A playground for visualizing garbage collection)
Closing Thoughts

Premature optimization is the root of all evil.
— Donald Knuth
This post covered the history of GC, the GC algorithms in use today, optimization strategies, and execution models. There are also approaches that avoid GC altogether, such as ZoC (Zero Allocation), but
Since this post is aimed at beginners, some topics that would be difficult for beginners to grasp have been omitted, along with certain optimization strategies.
Those who enjoy working directly with memory may regard GC as an evil and argue that it adds uncertainty to programming,
but as Donald Knuth pointed out, rather than getting bogged down in "premature optimization" concerns like memory management, GC allows developers to focus on "solving the actual problem."
A programmer's role is not simply to master techniques, but to solve the problems at hand. GC is an important tool that relieves many programmers of the burden of "memory management."
What matters is not "is GC good or bad" but rather taking the time to ask "which tool is best suited to solving my problem."