
(PATRIOT MISSILE DEFENSE: Software Problem Led to System Failure at Dhahran, Saudi Arabia)
Before we begin...
On February 25, 1991, at a U.S. Army barracks in Dhahran, Saudi Arabia, an Iraqi Scud missile struck the facility, killing 28 American soldiers. The U.S. Patriot missile defense system was operational at the time, yet it failed to intercept the Scud.
The U.S. Government Accountability Office (GAO) post-incident report summarizes the cause as follows.

Time is kept continuously by the system's internal clock in tenths of seconds but is expressed as an integer or whole number (e.g., 32, 33, 34...).
The Patriot system tracked internal time as an integer count of ticks, where each tick represented 1/10 of a second.
For example, 1 second equals 10 ticks, and 100 seconds equals 1,000 ticks. The problem was that converting these integer tick values into actual elapsed time in seconds required multiplying by 0.1.
time = tick × 0.1
The trouble is that 0.1 cannot be represented exactly in binary. Just as 1/3 in decimal never terminates (0.333333...), the decimal value 0.1 in binary also never terminates:
0.1₁₀ = 0.0001100110011001100110011...₂
The pattern 0011 repeats indefinitely.
Because a computer cannot store infinitely many bits, it must truncate this value at some point. The Patriot's weapons control computer performed this time conversion within a limited 24-bit register precision. As a result, 0.1 was not computed as the exact value 0.1, but as a truncated binary approximation.
The exact value is of the following form.
0.0001100110011001100110011...₂
The approximation truncated to 24-bit precision takes the following form.
0.00011001100110011001100₂
This approximation is approximately 0.0999999046 in decimal, which is ever so slightly less than the exact value of 0.1.
A single error is nearly invisible. But the Patriot system had been running continuously for over 100 hours at the time of the incident. 100 hours is 360,000 seconds, or 3,600,000 ticks at a 1/10-second tick interval.
In other words, a very small time-conversion error grew larger as it accumulated over a long uptime. Appendix II of the GAO report states that after 100 hours of continuous operation, the calculated time error was 0.3433 seconds, with a range gate shift of 687 meters.
A Scud travels at roughly 1,700 to 2,000 meters per second. Consequently, a time error of 0.34 seconds translates into a position prediction error of several hundred meters.
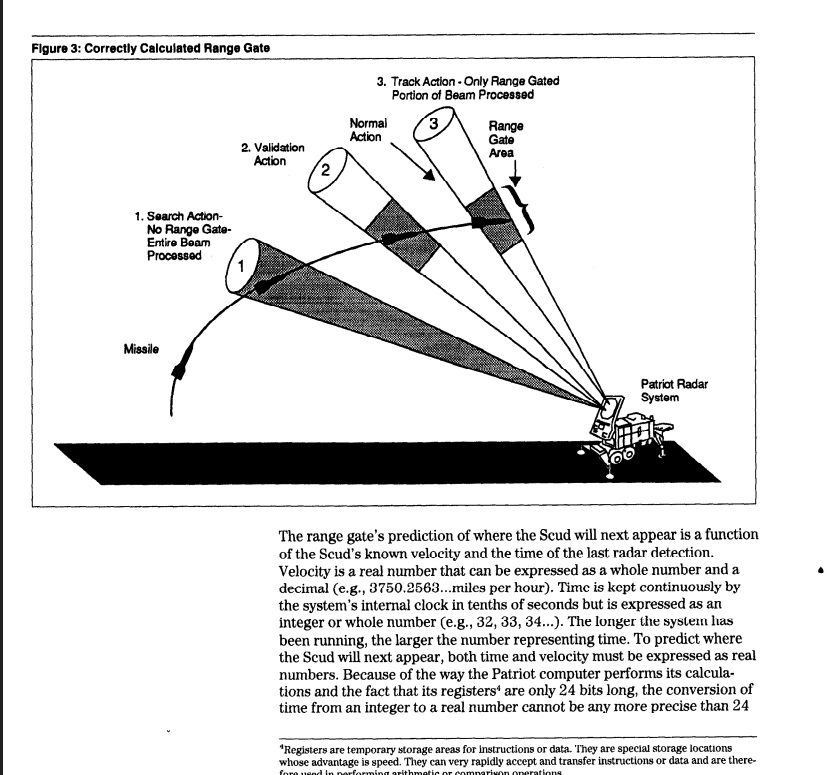
(Diagram from the GAO report illustrating the range gate. Under normal conditions, the radar begins with a wide search beam and then processes only the narrow range gate around the predicted position. In the Dhahran incident, the time error caused this predicted position to deviate from the actual Scud location.)
As a result, the Patriot system was looking at the position it had incorrectly predicted the Scud missile would be, not where the actual Scud was. The range gate had drifted off-center from the target, and the system failed to properly track the incoming Scud missile. The interceptor missile was never launched.
This post begins with why that small value 0.1 becomes an infinitely repeating fraction in binary. It then turns to why IEEE 754, standardized in 1985, still dominates floating-point arithmetic on most computers today, and how the ML era is beginning to challenge the assumptions underlying that standard.
Background knowledge needed to read this post
You don't need to know IEEE 754 in advance to read this post. It does help, however, to have an intuitive grasp of four things.
First, computers store real numbers not as decimal digits but as binary bit patterns, so even a seemingly simple decimal like 0.1 can become a non-terminating sequence like 0.000110011... in binary.
Second, float and double are not types that store real numbers exactly; they store the nearest representable value within a finite number of bits. float typically uses 32 bits and double typically uses 64 bits. double is more precise, but both are approximations.
Third, notations like 1e20 and 1e-7 are scientific notation: 1e20 means 1 × 10²⁰, the number 1 followed by 20 zeros, and 1e-7 means 1 × 10⁻⁷, or 0.0000001. Programming languages use this notation frequently to write very large or very small numbers concisely. For example, 1e3 is 1000, 1e6 is 1,000,000, and 1e-3 is 0.001.
Fourth, in deep learning there are situations where throughput matters more than computing every number at high precision, which is why lower-precision formats such as bfloat16, fp8, and fp4 have emerged. This post builds on these four foundations to explain the Patriot missile failure, IEEE 754, and the shift in numeric formats in the ML era.
The true nature of 0.1
Let's start with a familiar example.
#include <iostream>
#include <iomanip>
int main() {
double a = 0.1;
double b = 0.2;
std::cout << std::setprecision(20) << (a + b) << std::endl;//`std::setprecision` increases the number of output digits, making the internal rounding error visible.
return 0;
}
Result:
0.30000000000000004441Some will call it a bug.
But this is neither a C++ compiler defect nor a CPU flaw. It is the natural result of a typical implementation using IEEE 754 binary64 (double) with the default rounding mode (round to nearest, ties to even).1
Why is that? Converting the decimal 0.1 to binary gives the following.
0.1 (decimal) = 0.0001100110011001100... (binary, infinitely repeating)
This is the same phenomenon as 1/3 being represented as 0.333... in decimal. More precisely, when a rational number is reduced to its lowest terms, if the denominator is a power of 2, it terminates in binary, while if the denominator has any factor other than 2, it repeats in binary.
0.5 = 1/2 -> 0.1₂ exactly representable
0.25 = 1/4 -> 0.01₂ exactly representable
0.1 = 1/10 -> 1/(2×5) factor of 5 remains in denominator -> infinite repeating
0.2 = 1/5 -> factor of 5 remains in denominator -> infinite repeatingFloating-point arithmetic truncates an infinite decimal to fit into a finite number of bits. Because double preserves approximately 15 to 17 significant decimal digits, the moment you store 0.1, an error on the order of 1e-17 is already introduced.2
0.1 and 0.2 are each stored by rounding to the nearest binary64 value. Adding those two approximations and then rounding the result back to binary64 yields a value near 0.30000000000000004. Saying simply that "errors accumulated" is half right; more precisely, both the input conversions and the addition result are rounded to the nearest representable grid point.
This is not a defect in the standard but an inherent limitation of approximating real numbers with finite bits. The Patriot system simply let that limitation accumulate over 100 hours.
The real question is why we standardized this limitation in 1985 and have been living with it for over 40 years.
Pre-IEEE 754: an era of chaos
Floating-point hardware in the 1960s and 70s varied from one manufacturer to the next.
Manufacturer | Format |
|---|---|
IBM System/360 | Hexadecimal floating-point (base 16) |
DEC PDP-11/VAX | F-floating, D-floating |
CDC 6600 | 60-bit floating-point |
Cray-1 | 64-bit proprietary format |
Burroughs | 48-bit or 96-bit |
It was routine for the same C code to print 1.234 on an IBM machine and 1.235 on a VAX. Numerical libraries had to be rewritten for each machine, and an algorithm that converged correctly on one machine could diverge on another.
Floating-point hardware in the 1970s was like home appliances where every manufacturer shipped a different instruction manual for handling numbers. They all looked like the same outlet, but plugging into IBM spun a fan while plugging into DEC ran a blender. You were lucky if you got any reasonable number at all; 1 + 1 came out as 1.999999 on one machine and 2.000001 on another.
IBM System/360 pushed forward with something it called hexadecimal floating-point, a self-styled philosophy of "we organize things in 4-bit chunks; let's not carve every number into 0.1-sized pieces." The result was that 0.5 was represented with impressive precision, while 0.499 got the "somewhere in that ballpark, probably" treatment, a phenomenon known as Wobbling Precision.
DEC came in with a double standard called F-floating and D-floating. One was "use this for everyday work," and the other was "for those who paid extra, here's more precision." DEC was a pioneer of the business model where precision is sold as paid DLC.
CDC 6600 armed itself with the oddly specific number of 60 bits. The philosophy was essentially a fashion statement: "64 bits is too common; we go with 60 bits to be distinctive." Cray-1 layered speed on top of that with the attitude that being wrong fast was good enough. (To put it in programmer terms, the hardware omitted Guard Digits, the extra storage needed during rounding calculations.) Burroughs brought both 48-bit and 96-bit formats and declared, "small things small, big things big, everything is different here," making it a comprehensive variety pack.
In this chaos, programmers carrying the same C code from one machine to another had to watch their numbers convert to a different religion every time, much like a recruit reporting to basic training every week. What printed as 1.234 on IBM would become 1.235 on a DEC VAX.3
Each manufacturer's machine sang its own gospel with the program's computed results. A numerical algorithm that converged faithfully on one machine would, on another,
just blow up with a "never seen math like this before lol" attitude. Missile trajectories, bridge safety factors, and bank interest calculations varied depending on what mood the mainframe happened to be in that week.
The attempt to end this chaos began at Intel in 1976. While designing the floating-point arithmetic for the i432 and the 8086/8088 family, Intel brought in external consultant William Kahan.
Kahan was a mathematician and numerical analysis expert at UC Berkeley. He played a central role in designing the arithmetic for the Intel 8087 and in shaping the initial IEEE 754 draft. It would be inaccurate, however, to say that "Kahan created the committee." The IEEE p754 meetings were a standardization process involving many companies and researchers; Kahan's decisive influence came from obtaining Intel's permission to share the 8087's arithmetic specification and its rationale with the committee.45
In 1989, Kahan received the Turing Award. The ACM's official citation recognized "fundamental contributions to numerical analysis," and IEEE 754 is frequently cited as a central example of that contribution.6 He later left behind essays and lecture notes documenting the design intent and limitations of the standard, and much of this post owes a debt to those notes.
One point worth noting here: IEEE 754 is a compromise forged within the hardware constraints of the 1980s. It reflects the best balance achievable given the transistor counts, circuit complexity, and memory costs of that era. Whether that balance still represents the best option in 2026 is a separate question.
Bit layout: what gets stored
The core idea behind IEEE 754 is binary-based scientific notation.1
Just as we express $123.456$ in everyday notation as $1.23456 times 10^2$,
IEEE 754 translates that concept into a binary memory architecture.

(IEEE 754-2019 Standard, Section 3.4)
Note that the formula below applies only to Normal numbers as defined in the IEEE 754-2019 standard (Section 3.4). Zero, Subnormal numbers, Infinity, and NaN follow entirely different hardware interpretation rules for the sake of memory efficiency.
$$v = (-1)^{S} \times (1 + \text{Fraction}) \times 2^{E - \text{bias}}$$
(The bias is 127 for 32-bit and 1023 for 64-bit.)
Logical structure of a 32-bit float (Single precision):
1 bit | 8 bits | 23 bits |
Sign ($S$) | Exponent ($E$) | Fraction ($T$) |
Logical structure of 64-bit double (Double precision):
1 bit | 11 bits | 52 bits |
Sign ($S$) | Exponent ($E$) | Fraction ($T$) |
Bit layout as a 'tag' for classifying value types
The IEEE 754 bit layout is not merely a space for compressing real numbers. This structure also serves as a hardware tag that controls the lifecycle and state of a value. Depending on the bit pattern in the Exponent field, the lens through which the Fraction is interpreted changes entirely.
When all Exponent bits are 0 (0x00):
If the Fraction is 0: $pm0$ (signed zero)
If the Fraction is non-zero: a Subnormal number. This is a special range in which the implicit leading bit transitions from $1$ to $0$, providing a gradual defense against Underflow.
When the Exponent bits are between 1 and 254 (for 32-bit):
Normal number. This is the general real-number range to which the basic formula mentioned earlier applies.
When the Exponent bits are all 1 (0xFF):
If the Fraction is zero: $pminfty$ (Infinity). This is the result of operations such as $1.0 / 0.0$.
If the Fraction is non-zero: NaN (Not a Number). This signals a mathematically undefined computation failure, such as $0.0 / 0.0$.
In other words, the IEEE 754 format is not merely a container for storing a single real number. It is the crystallization of an architectural decision that elegantly packs everything from normal numbers and zero to infinitesimally small subnormal values, Infinity, and even exception-handling signals into a single bit layout.
That description, however, tends to be difficult to grasp on its own.
The IEEE 754 Bit Layout: A Shipping Box and Its 32-Bit Label
Imagine a 32-bit label (Invoice) affixed to the outside of a shipping box.
The delivery driver known as the CPU never tears open the box to inspect its contents. It simply scans this 32-bit label and mechanically decides, "Ah, this one needs to be handled this way."
This label is divided into three main sections.
Section | Name | Role |
1 bit | Sign | Arrow on top/bottom of the box (↑ positive / ↓ negative) |
8 bits | Exponent | Shipping class and handling tags that say "what's in this box?" |
23 bits | Fraction (Mantissa) | The actual contents (cargo) |
The key here is the Exponent tag. Depending on the state of the exponent tag, this box meets one of five completely different fates.
1. Standard cargo (Normal number) — Exponent tag: between 1 and 254
These are ordinary numbers: regular cargo like 3.14, -42.0, and 1.0.
But what if the sender is broke, like the author? To save space, they apply an anti-overpackaging rule: "the leading digit of the value (1) is always assumed to be there, so we don't write it on the label." This is the implicit leading bit.
📦 Delivery driver: "Standard cargo. Nothing fragile. Ship via normal route."
2. Empty box (±0) — Exponent tag: 0, Fraction: 0
A perfectly empty box with absolutely nothing inside.
Yet the label still carefully notes whether it's "top-side up (↑)" or "bottom-side up (↓)." The reason a sign exists even for an empty box is so the delivery driver can remember "whether this box was coming from the positive side and got emptied, or from the negative side and got emptied" (the inertia of convergence).
📦 Delivery driver: "Empty. But noted in the logbook that the box arrived upside-down."
3. Dust on the Verge of Vanishing (Subnormal numbers) — Exponent tag: 0, Fraction: nonzero
The box is almost empty, but a few cargo crumbs remain at the bottom.
These are numbers too tiny to fit into the normal invoice notation. In this case, the convention of "there's always a 1 at the front" is abandoned, and the system enters emergency mode, starting with 0.xxx. This is a buffer zone designed to prevent numbers from abruptly vanishing to zero (Underflow).
📦 Delivery driver: "Too small to call normal, too precious to throw away. Slowly falling toward zero."
4. The Box Launched into Outer Space (Infinity) — Exponent tag: 255 (MAX), Fraction: 0
The invoice reads: "Unmeasurable: Infinite."
When an undeliverable order like $1.0 / 0.0$ comes in, the CPU shrugs with "No idea. No answer. But keep going in this direction" and flings the box away. Thanks to the sign bit, it cleanly distinguishes between +∞ and -∞.
📦 Delivery driver: "Size unmeasurable. Thrown to the ends of the earth in that direction."
5. The Anarchist's Mail Bomb (NaN) — Exponent tag: 255 (MAX), Fraction: nonzero
The invoice bears a crooked red scrawl: "Mathematics is dead (Not a Number)."
This is a kind of "Unabomber mail bomb" that the system produces when a criminally absurd input violating the first principles of mathematics arrives, such as $0.0 / 0.0$ or $sqrt{-1}$. Inside this box, instead of cargo, sits a lengthy anarchist manifesto expressing pure contempt for the existing arithmetic order.
The most terrifying thing about this box is its merciless explosive power. The moment the delivery driver (CPU) carelessly bundles this box with any ordinary number box and places them on the addition or multiplication conveyor belt (ALU), it detonates. No matter what good cargo is attached to it, the result is guaranteed to be ash (NaN). A single NaN box flows through the entire calculation pipeline, triggering a chain reaction of mail-bomb attacks. Whatever it is, the safest move is to discard anything dangerous.
📦 Delivery driver: "Not cargo. Contains subversive literature seething with hatred for the world. The moment it brushes against any other cargo, everything explodes together. Please, just throw it away."
Sign bit ($S$)
The most significant bit (MSB). A value of 0 indicates a positive number; 1 indicates a negative number. Because this uses the Sign-Magnitude representation rather than Two's complement, $+0$ and $-0$ exist as physically distinct bit patterns.
Exponent and Bias
The 8-bit Exponent physically stores an integer from 0 to 255. However, floating-point numbers also need negative exponents (such as $2^{-3}$) to represent very small values like $0.001$. To achieve this, IEEE 754 introduces a technique called Bias rather than using Two's complement.
For a 32-bit float, the Bias is 127. You subtract 127 from the integer $E$ stored in memory to obtain the actual mathematical exponent.
Stored bits:
10000000($= 128$) $rightarrow$ actual exponent: $128 - 127 = 1$Stored bits:
01111110($= 126$) $rightarrow$ actual exponent: $126 - 127 = -1$
Why introduce Bias and abandon Two's complement, which handles negative numbers so elegantly?
This is the product of relentless optimization by hardware engineers in the 1980s. With Bias applied, comparing two positive floating-point numbers requires no trip through a complex floating-point unit (FPU); simply feeding the bits into a plain Integer Comparator perfectly preserves their lexicographical ordering.
Of course, the moment negative numbers are introduced, this integer comparison inverts and breaks down.
Yet, the rationale for abandoning Two's Complement—the universal standard for integer representation—in favor of this Sign-Magnitude approach was clear. The penalty of adding minor exception-handling logic for magnitude comparisons was vastly outweighed by the extreme simplification of floating-point multiplication and division hardware achieved by completely decoupling the sign. In terms of the silicon area constraints of the time, this provided an overwhelming advantage.
It was a calculated compromise: sacrificing perfect, universal elegance for the sake of overall system throughput
Fraction and Implicit Leading Bit
Commonly called the Mantissa, but the official IEEE 754 term is Fraction.
A normalized binary floating-point number always takes the form $1.xxxdots times 2^n$. The $1$ before the binary point is guaranteed to exist by mathematical definition, so there is no reason to waste memory transistors storing it. In hardware design terminology, this omitted bit is called the Implicit Leading Bit.
A 32-bit float therefore physically holds a 23-bit Fraction, but including the implicit bit it logically provides 24-bit Significand precision. This is the mathematical basis for the common statement that a float has "approximately 7 significant decimal digits."
($log_{10}(2^{24}) approx 7.22$)
A Closer Look at 0.1
Let's examine the bit pattern of 0.1 directly in C++.
#include <iostream>
#include <bit>
#include <bitset>
#include <cstdint>
int main() {
float f = 0.1f;
uint32_t bits = std::bit_cast<uint32_t>(f);
std::bitset<32> b(bits);
std::cout << b << std::endl;
return 0;
}
Output:
00111101110011001100110011001101
Breaking it down:
sign: 0
exponent: 01111011 (= 123, actual exponent = 123 - 127 = -4)
mantissa: 10011001100110011001101
In the mantissa's 10011001100110011001101 portion, you can see the repeating 1001 pattern. This is the result of truncating the infinitely repeating binary fraction of 0.1 to 23 bits. The last bit is rounded up to 1.
The actual value this bit pattern represents is approximately 0.10000000149011612. The moment you store 0.1 in a float, you haven't stored the exact value 0.1; you've stored 0.10000000149....
Special Values: Exceptions Defined by the Standard
Beyond ordinary floating-point values, IEEE 754 defines several special values.[fn:fn-000001] This is another point where "things that seem obvious break down."
±0
Having a sign bit means there are two zeros: +0 and -0 exist as distinct values.
double pos_zero = 0.0;
double neg_zero = -0.0;
std::cout << (pos_zero == neg_zero) << std::endl; // 1
std::cout << (1.0 / pos_zero) << std::endl; // inf
std::cout << (1.0 / neg_zero) << std::endl; // -inf
A == comparison treats them as equal, but division produces different results. The sign survives.
Mathematically, 0 and -0 are the same. However, IEEE 754 keeps them separate to preserve "which direction did we underflow toward zero from," information that numerical algorithm designers in the 1980s wanted to retain.
±∞
In the default rounding mode (round to nearest), overflow typically results in infinity.
double large = 1e308;
std::cout << large * 10 << std::endl; // inf
std::cout << -large * 10 << std::endl; // -inf
Older floating-point implementations behaved inconsistently on overflow, either triggering a trap (raising an exception) or producing a large arbitrary number. IEEE 754 defines ±∞ as an explicit value so that computation can continue without halting.
That said, you shouldn't memorize "overflow always gives infinity." IEEE 754 supports multiple rounding modes, and with directional rounding, overflow can saturate to the largest finite value instead. In practice, the key points are as follows.
Default round-to-nearest:
Too large positive → +∞
Too large negative → -∞
Directed rounding:
Depending on the rounding direction, the result may saturate to the maximum finite value.NaN: The Only Value Not Equal to Itself
NaN stands for Not a Number. It is assigned to indeterminate results such as 0/0, ∞-∞, and sqrt(-1).
double nan = 0.0 / 0.0;
std::cout << (nan == nan) << std::endl; // 0 (false)
NaN is not equal to itself. IEEE 754 explicitly defines it this way. The key point is that NaN does not correspond to any value on the number line. As a result, ordinary comparisons like x < y, x > y, and x == y become "unordered comparisons" the moment NaN is involved.
NaN == NaN -> false
NaN < 1.0 -> false
NaN > 1.0 -> false
NaN != NaN -> true
Because of this, NaN propagates silently through a computation and serves as a signal that "something numerically undefined happened somewhere along the way." The upside is that computation does not halt immediately; the downside is that when NaN surfaces much later, tracing it back to the original cause can be difficult.
Thanks to this definition, the canonical way to detect NaN is as follows.
bool is_nan(double x) {
return x != x;
}
If a value is not equal to itself, it is NaN. In IEEE 754, there is exactly one value that is not equal to itself, and that value is NaN.
Subnormal numbers: between 0 and the minimum normal number
A normalized floating-point number takes the form 1.xxx × 2^n. The minimum exponent for a float is -126, so the smallest representable normal number is approximately 1.18 × 10^-38.
What about numbers smaller than that? One option is to flush them to zero (flush to zero), but IEEE 754 chose a more elegant approach: the subnormal (or denormal) range.
When the exponent bits are all zero, the mantissa is interpreted in the form 0.xxx × 2^-126 without normalization. This reduces precision but fills the gap down to zero more smoothly. This is called gradual underflow.
The problem is performance. On some CPUs and GPUs, subnormal arithmetic falls off the normal floating-point fast path and can become significantly slower. In domains where small values accumulate, such as audio processing, DSP, and neural network forward passes, this performance cliff is a real concern. For that reason, many high-performance domains enable the FPU's FTZ (flush-to-zero) or DAZ (denormals-are-zero) mode, trading accurate gradual underflow for speed.
What IEEE 754 Actually Standardized
IEEE 754 is not merely a standard that defines a bit format specifying "a float is stored as sign/exponent/mantissa." More importantly, it standardizes the semantics of operations.
The goals the standard aimed to satisfy are as follows.
1. Given the same inputs, produce the same results for basic operations.
2. Round addition, subtraction, multiplication, division, and `sqrt` correctly.
3. Define exception states such as overflow, underflow, division by zero, invalid, and inexact.
4. Establish NaN, infinity, signed zero, and subnormal as a common language.
5. Specify rounding modes explicitly.
Among these, the one beginners overlook most often is inexact. Most floating-point operations cannot be represented exactly. Rather than hiding this fact, IEEE 754 allows the result of a rounding to be recorded via an exception flag.
invalid operation : 0/0, sqrt(-1), ∞ - ∞
division by zero : 1/0
overflow : exceeds the representable range
underflow : too small to be represented as a normal number
inexact : rounded because the exact mathematical result cannot be represented
Here, "exception" does not always mean throwing a language-level exception. In the IEEE 754 context, it is fundamentally a status flag. Computation continues, and only programs that care can read the flag afterward and respond accordingly. This design allows numerical code to preserve error information without halting after every operation.
ULP: A Unit for Measuring Floating-Point Error
When talking about floating-point "error being small," looking at the absolute value alone is not enough. 1e-7 near 1 and 1e-7 near 1e30 have completely different meanings.
This is why numerical computing uses the term ULP (unit in the last place): the gap between two adjacent floating-point values at the current magnitude.
Near small numbers:
Representable values are densely packed.
Near large numbers:
The gaps between representable values grow wider.
This is the cause of the following behavior.
#include <iomanip>
#include <iostream>
int main() {
double x = 1e20;
std::cout << std::setprecision(20) << (x + 1.0) << std::endl;
}
Mathematically the result should be 100000000000000000001, but in double precision, the 1.0 disappears. That's because near 1e20, the spacing between adjacent double values is already far larger than 1.
A note written through tears: Floating-point is not a box that holds all real numbers; it is a ruler whose tick spacing varies by interval. The further you go toward large numbers, the more sparsely spaced the tick marks become, like a middle-aged manager's thinning hair. Forget this, and you'll run into ghost bugs like "why didn't adding 1 change anything?"
Assumptions That Break Down
When we use IEEE 754 day to day, we unconsciously make several mathematical assumptions. Those assumptions do not hold under IEEE 754.2
The Associative Law Does Not Hold
In mathematics, (a + b) + c = a + (b + c). In floating-point, it does not.
double a = 1e20;
double b = -1e20;
double c = 1.0;
std::cout << (a + b) + c << std::endl; // 1
std::cout << a + (b + c) << std::endl; // 0
Computing a + b first gives 1e20 - 1e20 = 0, and adding 1 yields 1. Computing b + c first gives -1e20 + 1 = -1e20 (the 1 vanishes within the precision of 1e20), and adding 1e20 yields 0.
This is why the -ffast-math compiler option is dangerous. It assumes the associative law holds and freely reorders multiplication and addition. In code that requires precise numerical computation, the results can differ.
Adding 0.1 a Hundred Times Does Not Equal 10
double sum = 0.0;
for (int i = 0; i < 100; i++) {
sum += 0.1;
}
std::cout << sum << std::endl; // 9.99999999999998
The rounding error introduced when storing 0.1 accumulates over 100 additions, producing an error on the order of 1e-13. The Patriot missile's accumulated error of 0.34 seconds after 100 hours of tracking in 0.1-second increments is exactly this principle at work.
One mitigation is a compensated summation algorithm such as Kahan summation. This algorithm, however, is not a patch that emerged after IEEE 754; it belongs to a family of truncation/roundoff error reduction techniques that Kahan had been working on since the 1960s.7
#include <vector>
double kahan_sum(const std::vector<double>& xs) {
double sum = 0.0;
double c = 0.0; // The Compensating Value for a Small Lost Term
for (double x : xs) {
double y = x - c;
double t = sum + y;
c = (t - sum) - y;
sum = t;
}
return sum;
}
The key idea is to store the "lost fragment" in a separate variable c and use it to correct the next addition. This method is not magic either, but it is far more stable than naive accumulation in many cases.
Integers, too, eventually lose precision
double approximates real numbers, but it represents small integers exactly. Because binary64 has a significand with 53 bits of precision, every integer whose absolute value is at most 2^53 can be represented exactly.
The problem starts beyond that point.
#include <iomanip>
#include <iostream>
int main() {
double x = 9007199254740992.0; // 2^53
std::cout << std::setprecision(17) << x << std::endl;
std::cout << std::setprecision(17) << (x + 1.0) << std::endl;
std::cout << std::setprecision(17) << (x + 2.0) << std::endl;
}
A typical result:
9007199254740992
9007199254740992
9007199254740994
Near 2^53, the gap between representable double values becomes 2. So +1 falls between grid points and vanishes, while +2 lands on the next grid point. This is precisely why JavaScript's Number.MAX_SAFE_INTEGER is 2^53 - 1.
Catastrophic cancellation
When you subtract two numbers of similar magnitude, significant digits disappear rapidly.
double a = 1000000000.1;
double b = 1000000000.0;
double diff = a - b; // 0.10000002384185791
By the time a and b are stored, they have already hit the precision limit of large numbers. The difference between the two values should be 0.1, but that precision is not guaranteed.
This is why you cannot naively code the quadratic formula directly. In -b + sqrt(b² - 4ac), if b is large and 4ac is small, then sqrt(b² - 4ac) ≈ b, turning the computation into the difference of two nearly equal numbers and causing significant digits to vanish. It is the first example covered in every numerical analysis textbook.
Common mistakes in everyday practice
Why -ffast-math is dangerous
GCC and Clang's -ffast-math sounds innocuous by its name, but its implications are quite significant. For GCC, -ffast-math enables a bundle of options including -funsafe-math-optimizations, -ffinite-math-only, -fno-rounding-math, -fno-signaling-nans, and -fexcess-precision=fast.8
As a result, the compiler operates under assumptions closer to the following world of expressions.
You may assume NaN and ±∞ are absent.
You may assume the current rounding mode does not change.
You do not need to worry about signaling NaN.
You may weaken the `errno`/exception semantics of certain math functions.
You may combine multiplication and addition into an FMA or reorder operations.
Performance may improve, but in exchange the semantics of NaN, infinity, rounding modes, exception states, and operation ordering that IEEE 754 was designed to guarantee are weakened. In domains like game engines and graphics, where errors in the last digit are inconsequential, this flag can be used; but in domains like scientific computing, finance, and medical imaging, where reproducibility of results matters, it must not be enabled without careful validation.
In particular, when -ffast-math is enabled globally during linking with other libraries, the IEEE 754 behavior those libraries assume can break. Numerical libraries such as Boost and Eigen warn about this explicitly.
Money is not handled with floating-point
double price = 0.10;
double total = 0.0;
for (int i = 0; i < 1000; i++) {
total += price;
}
std::cout << total << std::endl; // 99.999999999998593
Accumulating transaction amounts in floating-point can cause rounding errors and inconsistent rounding policies to leak into accounting results. That is why the settlement and ledger layers of financial systems use BigDecimal (Java), decimal (C#, Python), or integer-based cent units (common in fintech).
The trade-off between GPUs and fast math
Depending on the workload, GPUs may either strictly observe IEEE 754 semantics or permit relaxed/approximate operations for performance. Saying "GPUs don't follow IEEE 754 by default" is an oversimplification.
In CUDA, enabling --use_fast_math also turns on --ftz=true, --prec-div=false, --prec-sqrt=false, and --fmad=true together.9
--ftz=true:
Flushes single precision denormals to zero.
--prec-div=false:
Allows fast approximation in single precision division/reciprocal.
--prec-sqrt=false:
Allows fast approximation in single precision sqrt.
--fmad=true:
Multiply-add operations can be fused into FMA.
A pixel or two rendering with a color difference of about 1/255 may be imperceptible to the human eye. The same difference in a physics simulation, financial risk model, or medical image reconstruction carries an entirely different meaning. That is why GPU numerical computation always comes down to a choice between "accuracy mode" and "throughput mode."
Cracks in the machine learning era
This is where the core subject of this post begins.
The trade-off IEEE 754 defined in 1985 was "accuracy vs. hardware cost." The dominant numerical computing workloads of that era were scientific simulation, engineering analysis, and financial calculation, all of which depended on accuracy for the reliability of their results.
From the mid-2010s onward, the rise of machine learning shifted that trade-off.
In neural network training, the precision of any individual weight does not matter much. It is sufficient for hundreds of millions of parameters to be updated in the right direction on average. What actually determines result quality is throughput. The ability to process more data in the same amount of time enables larger models and longer training runs, and that translates directly into performance.
This shift in understanding began to crack the foundation of IEEE 754.
bfloat16: Google's rebellion
The beginning of this movement was bfloat16 (brain floating point), introduced by Google in 2017 alongside the public release of the TPU v2.10
IEEE 754's float16 (half precision) is sign 1 + exponent 5 + mantissa 10. Within 16 bits, more is allocated to the mantissa to preserve precision.
bfloat16 is sign 1 + exponent 8 + mantissa 7. It sacrifices mantissa bits to keep the exponent identical to float32. The result is lower precision, but the representable range (dynamic range) matches float32. On Google TPUs, it is used by accumulating bfloat16 multiplication results in FP32.5
Why this choice? In neural network training, gradients can be extremely small or extremely large, and insufficient range causes underflow or overflow that breaks training. The mantissa's lower precision, on the other hand, is partially compensated by the averaging effect of stochastic gradient descent.
Google TPUs, NVIDIA Ampere (A100), and certain Intel Xeon generations support bfloat16 natively. Although it differs from the binary16 format defined by IEEE 754, it has become the de facto standard mixed-precision option in ML.
fp8 and smaller formats
In 2022, NVIDIA, Arm, and Intel jointly published FP8 Formats for Deep Learning, and that same year NVIDIA Hopper (H100) began supporting fp8 natively.11
fp8 comes in two variants: E4M3 (exp 4 + mantissa 3) and E5M2 (exp 5 + mantissa 2). In practice, different formats are mixed depending on the workload, for example using E4M3 for the forward pass and E5M2 for the backward pass.
In 2024, NVIDIA Blackwell (B200) went down to fp4: a 4-bit floating-point format where exponent and mantissa together occupy just 4 bits. More precisely, fp4 can represent only 16 distinct values, making it closer to a lookup table in practice.12
These formats are the result of prioritizing ML workload throughput and memory efficiency over the general-purpose numerical stability that was the traditional goal of IEEE 754. Rather than saying "precision has been abandoned entirely," it is more accurate to say that the locations where precision is needed and where it is not are separated.
Weight/activation storage:
Lower precision allowed
Matrix multiplication:
Lower precision inputs used
Accumulation:
FP32 or wider accumulator used
loss scaling / quantization scale:
Metadata used to compensate for the limited range of small formats
In other words, numeric formats in the ML era move away from the model of "one number type bears all responsibility for accuracy." Precision is instead a collective product of format, scale, accumulator, and optimizer working together.
What is ending, and what is beginning
To be clear, IEEE 754 has not ended entirely.
Scientific computing, engineering simulation, CAD, rendering, and statistical modeling still rely on float32 and float64. Finance also makes heavy use of float64 for risk models, options pricing, and simulation, although accounting, settlement, and ledger amounts are typically handled with decimal or integer fixed-point representations.
As ML training and inference claim an ever-larger share of computing resources, however, the transistors inside GPUs and TPUs are increasingly allocated to formats other than IEEE 754. The NVIDIA H100's floating-point throughput is overwhelmingly concentrated in bfloat16 and fp8, while float64 performance is comparatively modest.
For the first time, the assumption that a standard set in stone in 1985 would dominate all of computing for 40-plus years is beginning to waver.
In Closing...

Floating point numbers are like sandpiles: every time you move one you lose a little sand and you pick up a little dirt.
— Brian Kernighan & P.J. Plauger (The Elements of Programming Style, 1974) P.117
We often forget the enormous inertia of technology.
IEEE 754 was born in 1985 from a compromise between the brutal hardware cost constraints of the era and the dominant workload of scientific computation. From the perspective of that time, it was a rational decision that bordered on miraculous. Yet once the concrete of a "standard" sets, inconveniences get ignored. Every CPU, compiler, numerical library, and network protocol stacks itself on top of that foundation. Technical standards survive not through ideal elegance but through the sunk costs of already-laid infrastructure and the momentum of their ecosystems.
A standard is a fortress. Inside its walls we calculate in safety, while outside them new barbarians begin building different worlds with different numbers. What makes this interesting is that the inertia of this seemingly impregnable fortress, rock-solid for 40 years, has started to shatter as we enter the AI/ML era. Deep learning, as a vast new workload, demands explosive computational speed and bandwidth rather than precision below the decimal point. That enormous market pressure has spawned exotic new formats like BF16, FP8, and NF4, cracking the old standard and opening a second age of barbarianism where vendors once again carve up bits however they please.
The fact that 0.1 + 0.2 does not equal 0.3 is not strange in the slightest. What is truly strange is that the machines we work with leap precariously across a sparse, coarse, finite grid, yet we keep mistaking that grid for an infinite, perfectly continuous number line. The human mind dreams of a smooth number line, while the machine's hand steps across a scattered lattice. We walk over this crack every day and yet rarely think to look down at our feet.
Sand slides down through the lattice and dust accumulates on top. With every transfer, every addition and multiplication, the grains we could not quite hold onto quietly slip through our fingers, and the world's dust settles into the spaces they leave behind. Floating-point arithmetic wears away a little at a time, growing a little dirtier with each operation. We have never once held a perfect number in our hands, and yet we scoop up that worn-down pile of sand and cup it between our palms again.
Even inside that lattice world, we add 0.1 and 0.2 every morning and carry on. Atop the accumulated total of sand that has slipped away and dust that has settled in, we still expect the bridge to hold, the missile to fly, and the bank ledger to balance. The reason all of this holds together is that people who know how much sand is sliding and can gauge how fast the dust mixes in are still out there, holding this world up.
Floating-point arithmetic is like a pile of sand. Every time it is moved from one container to another, a little sand slips out, and a little dust mixes in to take its place. We build castles from that dust-laced sand, trust those castles, and fall asleep inside them every night.
Footnotes
- IEEE 754-2019, IEEE Standard for Floating-Point Arithmetic (current standard, successor to the 1985 original) ↩
- David Goldberg, What Every Computer Scientist Should Know About Floating-Point Arithmetic, ACM Computing Surveys 23(1), 5-48 (1991) ↩
- South Korean men in their twenties undergo mandatory military training, and every weekend they attend religious services. During these events, religious facilities on base distribute snacks to trainees as comfort items, but since each religion provides different menus (Choco Pie, hamburgers, etc.), so-called 'subsistence-motivated religious conversion' is commonplace, with trainees switching faiths weekly depending on the offerings. One week they convert to Buddhism, which hands out two Choco Pies; the next week they switch to Christianity, which offers McDonald's hamburgers; the week after that they receive Catholic baptism for cola. It is thoroughgoing mercenary faith and migratory behavior dictated by the menu board. ↩
- William Kahan, Lecture Notes on the Status of IEEE Standard 754 for Binary Floating-Point Arithmetic (1996) ↩
- William Kahan, An Interview with the Old Man of Floating-Point, IEEE Computer condensed version (1998). Kahan's retrospective on the formation of the Intel 8087 and IEEE p754. ↩
- ACM A. M. Turing Award - William Kahan, Association for Computing Machinery (1989). The official citation reads: "For his fundamental contributions to numerical analysis." ↩
- William Kahan, "Further remarks on reducing truncation errors", Communications of the ACM, 8(1), 1965. The original source for the Kahan summation family. ↩
- GCC Manual, Optimize Options: -ffast-math, GCC documentation. ↩
- NVIDIA CUDA Compiler Driver, `--use_fast_math`, NVIDIA CUDA documentation. ↩
- Shibo Wang & Pankaj Kanwar, BFloat16: The secret to high performance on Cloud TPUs, Google Cloud Blog (2019) ↩
- Paulius Micikevicius et al., FP8 Formats for Deep Learning, arXiv:2209.05433 (2022) ↩
- NVIDIA Blackwell Architecture, NVIDIA, GTC (2024). Second-generation Transformer Engine with FP4 support based on micro-tensor scaling. ↩