
Fundamental algorithms such as sorting or hashing are used trillions of times on any given day. As demand for computation grows, it has become critical for these algorithms to be as performant as possible. Whereas remarkable progress has been achieved in the past, making further improvements on the efficiency of these routines has proved challenging for both human scientists and computational approaches. Here we show how artificial intelligence can go beyond the current state of the art by discovering hitherto unknown routines. To realize this, we formulated the task of finding a better sorting routine as a single-player game. We then trained a new deep reinforcement learning agent, AlphaDev, to play this game. AlphaDev discovered small sorting algorithms from scratch that outperformed previously known human benchmarks. These algorithms have been integrated into the LLVM standard C++ sort library. This change to this part of the sort library represents the replacement of a component with an algorithm that has been automatically discovered using reinforcement learning. We also present results in extra domains, showcasing the generality of the approach.
— Mankowitz et al., "Faster sorting algorithms discovered using deep reinforcement learning," *Nature* (2023)
Before We Begin
In algorithm textbooks, sorting is typically treated as a "solved problem." Hybrid algorithms like Timsort, pdqsort, and introsort have already been optimized over decades, and the code that makes it into standard libraries is the product of repeated review by experts.
In 2023, Google DeepMind's AlphaDev proved that assumption wrong. What it found was not a new algorithm.
It was an instruction sequence that removes a single instruction from the existing sort3 kernel, and that one line was incorporated into LLVM libc++.
This post explains why that discovery matters.
To do that, we need to start with Quicksort.
(Quicksort animation)
The Basic Structure of Quicksort
Quicksort is a divide and conquer algorithm. Its operating principle is simple.
1. Choose a pivot from the array.
2. Separate elements smaller than the pivot to the left and larger elements to the right. This step is called the partition.
3. Recursively repeat the same process on the left sub-array and the right sub-array.
In code, it looks like this.
void quicksort(int* arr, int lo, int hi) {
if (lo >= hi) return;
int pivot_idx = partition(arr, lo, hi);
quicksort(arr, lo, pivot_idx - 1);
quicksort(arr, pivot_idx + 1, hi);
}There are several implementations of the partition needed for Quicksort, but under the Lomuto scheme, the pivot is placed at the far right and you traverse from the left, pushing elements smaller than the pivot toward the front.
int partition(int* arr, int lo, int hi) {
int pivot = arr[hi];
int i = lo - 1;
for (int j = lo; j < hi; j++) {
if (arr[j] <= pivot) {
i++;
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i + 1], arr[hi]);
return i + 1;
}The average time complexity is O(n log n). If we assume each partition splits the array roughly in half, the recursion depth is log n, and each level does O(n) work.
The Worst Case and the Pivot Selection Problem
Quicksort's weakness lies in pivot selection. The more evenly the partition splits the two sub-arrays, the better the performance; the more skewed the split, the worse it gets.
The worst case occurs when the pivot is always chosen as the minimum or maximum value. In that situation, one sub-array always has size zero, the recursion depth becomes n, and the time complexity drops to O(n²).
There are well-known inputs that trigger this situation.
1. Choosing the first element as the pivot on an already-sorted array.
2. Choosing the last element as the pivot on a reverse-sorted array.
3. An array where all elements are identical.
It is counterintuitive that a sorted input is the slowest case in a naive Quicksort implementation.
That is exactly why this problem cannot be left unaddressed at the library level.
One of the early solutions was to select the pivot at random.
A random pivot probabilistically dilutes the worst case for specific inputs, but it carries the cost of random number generation and does not eliminate the worst case entirely.
The Median-of-Three Strategy
int median_of_3(int* arr, int lo, int hi) {
int mid = lo + (hi - lo) / 2;
if (arr[lo] > arr[mid]) std::swap(arr[lo], arr[mid]);
if (arr[lo] > arr[hi]) std::swap(arr[lo], arr[hi]);
if (arr[mid] > arr[hi]) std::swap(arr[mid], arr[hi]);
return mid;
}(Median-of-three)
(The reason lo + (hi - lo) / 2 is used instead of (lo + hi) / 2 is that lo + hi can overflow when it exceeds INT_MAX, and in C++ that difference actually leads to bugs.)
The practical alternative that emerged is median-of-three pivot selection: choosing the median of the first, middle, and last elements of the array as the pivot.
This approach mitigates the problem of always selecting the worst possible pivot on an already-sorted or reverse-sorted array.
That is because the median of three candidates is likely to be close to the true median of the entire array.
More importantly, there is a useful side effect. When the three elements are compared and repositioned during the median-of-three step, those three elements end up already sorted. Because this sub-array lands at the boundary after partitioning, those three elements do not need to be processed again in subsequent recursive calls. This effectively reduces the cost of the partition as well.
After Sedgewick systematized this approach in the 1970s, median-of-three became the standard strategy in practical Quicksort implementations.
To Eliminate the Worst Case Entirely: Introsort
Median-of-three cannot completely eliminate the worst case. With extreme or deliberately crafted inputs, O(n²) behavior can still occur.
Introsort solves this problem. Proposed by David Musser in 1997, it is a hybrid algorithm combining Quicksort and Heapsort.
It works as follows.
1. Track the recursion depth. The threshold is typically
2 * log2(n).2. While the recursion depth is below the threshold, use Quicksort (with a median-of-three pivot).
3. When the recursion depth exceeds the threshold, switch to Heapsort.
Because Heapsort always guarantees O(n log n), detecting the point at which Quicksort starts to degrade into worst-case behavior and switching to Heapsort makes it possible to guarantee the overall time complexity.
One more optimization is layered on top of this. When the sub-array size falls below a fixed threshold (typically 16 or fewer), the algorithm switches to Insertion sort. For small arrays, Insertion sort has a smaller constant factor than Quicksort, and it also has better cache locality.
static constexpr int THRESHOLD = 16;
void introsort(int* arr, int lo, int hi, int depth_limit) {
if (hi - lo < THRESHOLD) {
insertion_sort(arr, lo, hi);
return;
}
if (depth_limit == 0) {
heap_sort(arr, lo, hi);
return;
}
int pivot_idx = median_of_3(arr, lo, hi);
pivot_idx = partition(arr, lo, hi);
introsort(arr, lo, pivot_idx - 1, depth_limit - 1);
introsort(arr, pivot_idx + 1, hi, depth_limit - 1);
}
void sort(int* arr, int n) {
int depth_limit = 2 * static_cast<int>(std::log2(n));
introsort(arr, 0, n - 1, depth_limit);
}C++'s std::sort is based on Introsort. Both GCC libstdc++ and LLVM libc++ follow this structure.
So, why is the author writing about all this?
Because in 2023, after more than two decades, an AI found a new solution to this problem.
But first, let's build up the background knowledge needed to understand what exactly the AI discovered.
What Is a Kernel?
Kernel (core)
The word is usually translated as "core," and anyone with a computer background will immediately think of the OS kernel when they hear it,
but for the purposes of this discussion, "kernel" does not mean the operating system kernel. It refers to a very small unit of computation that is called from within a larger algorithm.
What AlphaDev improved in 2023 was precisely these fixed-size kernels.
The kernels named sort are small computational units primarily used for sorting,
and the specific targets were sort3, sort4, and sort5. For each of them, AlphaDev found an instruction sequence that operates with fewer instructions than the best human-written implementation.
In other words, it discovered a more efficient sequence with the fat trimmed out.
To summarize what these sort kernels do:
sort1 handles 1 element, sort2 handles 2 elements, and sort3 handles 3 elements.
sort1 performs no operation.
sort2 consists of a single comparison and a single conditional swap.
sort3 is a fixed-size kernel that sorts exactly 3 elements.
These kernels can be called independently, but they are most commonly used as building blocks inside larger sorting algorithms.
Why sort3?
sort3 is a fixed-size kernel that sorts exactly 3 elements;
it is a sorting routine with an input size fixed at exactly 3. Unlike a general-purpose sort, it does not handle arrays of arbitrary length. Because the length is determined at compile time, it is composed entirely of comparisons and conditional swaps, with no loops or recursion.
Such a kernel can be used on its own, but in practice it is more commonly used as a building block within a larger sorting algorithm like std::sort. For example, Introsort calls sort3 in the median-of-3 step for pivot selection, and as it descends into smaller intervals, it also repeatedly uses small sorting routines at the 2–4 element level during the transition to Insertion sort.
In other words, sort3 is not a "toy sorter for 3 elements"; it is a small core operation that large sorting algorithms depend on repeatedly. Although it is small, it is called very frequently, so an optimization that shaves off even one or two instructions can produce a significant cumulative effect at the system level.

(a. A C++ implementation of a variable sorting function that sorts an input sequence of at most two elements.
b. a's C++ implementation compiles to the following low-level assembly representation.)
Why does this relate to Quicksort?
Let's think about how Introsort is implemented.
There are two points in Introsort where small-array sorting is needed.
First, three elements are sorted in the median-of-three pivot selection step.
That is sort3.
Second, when transitioning to Insertion sort at the bottom of the recursion, Insertion sort itself internally repeats the work of comparing and sorting 2–4 elements.
It sounds complicated when described in words, but think of it simply as lining students up by height in a classroom.
You compare two students, move the shorter one forward and the taller one back, and keep repeating this kind of split.
So, how did we humans express this?
And to understand that, we need to know a little about assembly language.
Assembly Basics: Before Reading the Code
Assembly is a language at the instruction level that the CPU understands directly. There are no variables or function calls as in C or Python. Instead, it operates with registers and instructions.
A register is a small temporary storage space inside the CPU. It is similar to a variable, but the number of registers is fixed, and all operations must go through them. On x86-64, general-purpose registers include rax, rbx, rcx, and so on. For simplicity in this post, they are labeled P, Q, R, and S.
The four instructions used below are as follows.
Instruction | Meaning | Example |
|---|---|---|
| Copies the value of B into A |
|
| Compares A and B and records the result in flags. The values themselves are not changed. |
|
| If A > B in the preceding |
|
| If A < B in the preceding |
|
- Instruction
mov A, B- Meaning
Copies the value of B into A
- Example
mov R, S→ S = R
- Instruction
cmp A, B- Meaning
Compares A and B and records the result in flags. The values themselves are not changed.
- Example
cmp P, R→ compare P and R
- Instruction
cmovg A, B- Meaning
If A > B in the preceding
cmp, copies B into A. Otherwise does nothing.- Example
cmovg P, R→ if P > R, then P = R
- Instruction
cmovl A, B- Meaning
If A < B in the preceding
cmp, copies B into A. Otherwise does nothing.- Example
cmovl R, S→ if R < S, then R = S
cmovg and cmovl are conditional moves (cmov). They handle a branchless comparison and selection in a single instruction, without an if statement. Because there is no branch misprediction cost, they are advantageous for performance in code like sorting where comparisons repeat frequently.
Here is an example of how the flags work after a cmp.
cmp P, R ; compare P and R, store the result in flags
cmovg P, R ; if P > R, then P = R → P becomes min(P, R)
cmovl R, S ; if P < R, then R = S → R becomes max(P, R)What these two lines accomplish is, in effect, P = min(A, C) and R = max(A, C).
With this much background, you can follow the sort3 code below line by line.
The sort3 That Humans Write
On x86, the assembly flow for sorting three elements A, B, C is as follows, using registers P, Q, R, S.
; Initial state: P = A, Q = B, R = C
mov R, S ; S = C (preserve C)
cmp P, R ; compare A vs C
cmovg P, R ; P = min(A, C)
cmovl R, S ; R = max(A, C)
mov S, P ; S = min(A, C) ← key point
cmp S, Q ; compare min(A, C) vs B
cmovg Q, P ; P = min(A, B, C)
cmovg S, Q ; S = middle valueThe role of mov S P is clear. After the previous comparison put min(A, C) into P, this copies that value into S to keep it safe for use in the next comparison.
Humans explicitly settle intermediate state before moving to the next step.
This habit improves readability and ease of verification, and makes the code easier to understand locally.
This is hard to follow in the abstract, so let's use an example.
Example: Suppose you are lining up the entire class by height.
The teacher designates one student as the pivot.
The remaining students move left if they are shorter than the pivot and right if they are taller. Once a round of sorting is complete, the designated student's position is finalized.
Then the same process is repeated within the left group and the right group.
Until each group is down to one person.
This is Quicksort.
At each step, one student's position is finalized, and the rest are split into progressively smaller groups.
And within Quicksort,
when the teacher designates a pivot, there are three candidates.
The front, the middle, and the back. The student with the median height among these three is chosen as the pivot.
To do that, you first have to line up those three students in order of height.
The work of sorting those three students is sort3.
After lining up the three students, the teacher records the result on the board: "The middle student is the pivot, and the order of the three is already finalized." This record becomes the premise for the entire sort that follows.
When the group shrinks to three or fewer, sort3 is called again. sort3 runs at nearly every level of the recursion tree throughout the entire class-wide sort.
So what about AI?
The Code AlphaDev Found
AlphaDev's result is as follows.
; Initial state: P = A, Q = B, R = C
mov R, S ; S = C
cmp P, R ; compare A vs C
cmovg P, R ; P = min(A, C)
cmovl R, S ; R = max(A, C)
; mov S, P ← removed
cmp S, Q ; S = C, compare with B
cmovg Q, P ; conditional move
cmovg S, Q ; conditional movemov S P is gone. At this point, S still holds the original value of C, not min(A, C). Intuitively this looks wrong and is hard to follow.
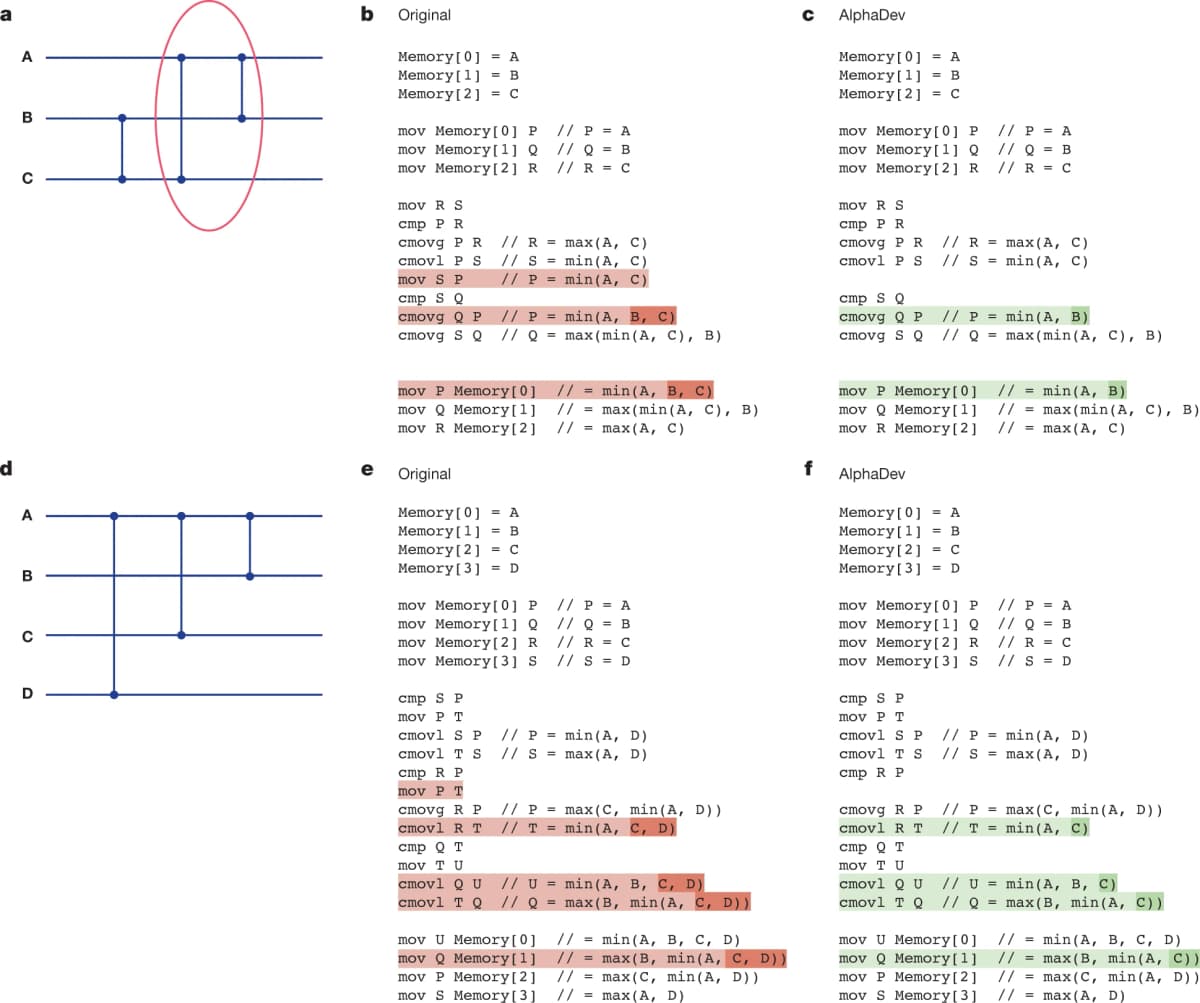
(Code and image from the original paper)
Why Is Removing It Still Correct?
This code is not a standalone routine. It is a partial piece of code within a sorting network.
A sorting network is a structure that performs sorting by connecting comparators in a fixed order. Each comparator takes two inputs and outputs the min and max. The key point is that the output of earlier comparators constrains the input conditions for later ones.
At the point where AlphaDev's code fragment executes, the preceding comparator has already guaranteed B ≤ C. With this precondition in place, the analysis changes.
With mov S P removed, S = C. Since B ≤ C holds, the result of cmp S Q, that is, the comparison between C and B, already has a determined direction. Under this condition, the final three outputs produced by the subsequent two cmovg instructions form the same sorted result as when mov S P is present.
Tracking the register state step by step looks like this.
Step | P | Q | R | S | Precondition |
|---|---|---|---|---|---|
Initial | A | B | C | - | B ≤ C |
mov R, S | A | B | C | C | |
cmovg P, R | min(A,C) | B | C | C | |
cmovl R, S | min(A,C) | B | max(A,C) | C | |
cmp S, Q (S=C, Q=B) | C ≥ B already holds | ||||
cmovg Q, P | min(A,C,B) | B | max(A,C) | C | |
cmovg S, Q | min(A,C,B) | median | max(A,C) | median |
- Step
Initial
- P
A
- Q
B
- R
C
- S
-
- Precondition
B ≤ C
- Step
mov R, S
- P
A
- Q
B
- R
C
- S
C
- Precondition
- Step
cmovg P, R
- P
min(A,C)
- Q
B
- R
C
- S
C
- Precondition
- Step
cmovl R, S
- P
min(A,C)
- Q
B
- R
max(A,C)
- S
C
- Precondition
- Step
cmp S, Q (S=C, Q=B)
- P
- Q
- R
- S
- Precondition
C ≥ B already holds
- Step
cmovg Q, P
- P
min(A,C,B)
- Q
B
- R
max(A,C)
- S
C
- Precondition
- Step
cmovg S, Q
- P
min(A,C,B)
- Q
median
- R
max(A,C)
- S
median
- Precondition
Looking only at the local code, it appears incorrect, but once you include the invariant guaranteed by the full network, it is correct. The Nature paper names this construct the AlphaDev swap move.
How should this be understood using the classroom analogy from earlier?
This time, we are lining up just three students: A, B, and C.
A human teacher would do it like this: first compare A and C to establish their order, then write the result on the board. "The one standing in front right now is min(A,C)."
Looking at that note, the teacher then compares with B to complete the final order.
The intermediate result is always written down before moving on.
But in this particular classroom, before the lesson even began, the heights of B and C were already measured, and the fact that "B is shorter than C" is already written on the board. A teacher who knows this fact does not need to write a new note. Right after comparing A and C, the teacher can use that existing fact as a given and move directly to the next comparison. The final lineup is identical.
The single line AlphaDev removed is that note on the board.
Humans habitually write down intermediate state without examining what the next step presupposes, but AlphaDev used what was already on the board, the invariant secured by the preceding step, as its premise, and eliminated the note itself.

The Nature paper states that these routines run trillions of times every day. That is not an exaggeration. C++ programs running on servers around the world, database engines, network stacks, and file systems all call std::sort.
That means every time std::sort is called, sort3 runs at nearly every internal node of the recursion tree. Sorting n elements produces O(n) internal nodes in the recursion tree, and since sort3 is called at each node, the total number of sort3 executions across the entire sort is also proportional to O(n).
Given that, the claim that it runs trillions of times is no exaggeration at all.
Why Couldn't Humans Find This?
Humans verify code locally.
"You need to make a comparison you haven't made yet before it's safe to proceed to the next one."
The thinking goes: "You need to explicitly settle the intermediate state once before moving on."
This habit improves readability and ease of verification, and makes the code easier to understand locally.
AlphaDev does not have that constraint.
It treats the entire register state transition as a search space and only judges whether the final three outputs satisfy the sorted condition. The deep reinforcement learning structure, which treats each assembly instruction as an action and designs sorting correctness and instruction count as the reward, is what made this search possible.
Using the invariant guaranteed by the full algorithm to eliminate a local bookkeeping copy was a natural discovery in that search process. The reason a single line that humans had left untouched for decades was finally removed comes down, in the end, to the difference in the unit of search.

(Columbus's egg)
Closing Thoughts...
The point of this discovery is not that AI is superior to humans.
What matters is the difference in the unit of search.
Humans understand code locally, organize intermediate state, and think in terms of safely verifying each step.
AlphaDev, by contrast, operates over the entire state space, looking only at whether the final output satisfies the condition and whether the instruction count is minimized.
Because of that difference, a single line that humans had taken for granted for decades was removed.
In other words, some of the code patterns we consider "obvious" may not reflect the essence of the problem at all. They may simply be habits that hardened around whatever form humans found easiest to understand and verify.
AlphaDev demonstrated that fact through a small example.
This is similar to Columbus's egg.
Once you see the answer, anyone can say it was simple.
But the truly hard part is being the first to break an assumption that nobody had ever questioned.
What AlphaDev showed is not better programming, but the possibility of looking at structures humans took for granted through a different mode of search.
We now have not only human cognitive habits, but also AI as a new search tool.
Whether to call that intelligence in the same sense as human intelligence is something I personally hesitate over.
But the fact that things we have taken completely for granted are being broken apart one by one in this way is, without question, intellectually exciting.
References: Mankowitz, D. J., Michi, A., Zhernov, A., Gelmi, M., Selvi, M., Paduraru, C., Leurent, E., Iqbal, S., Lespiau, J.-B., Ahern, A., Köppe, T., Millikin, K., Gaffney, S., Elster, S., Broshear, J., Tsing, A., Polosukhin, I., Pikhtin, A., Sifre, L., Singh, S., … Silver, D. (2023). Faster sorting algorithms discovered using deep reinforcement learning. Nature, 618(7964), 257–263. https://doi.org/10.1038/s41586-023-06004-9