for(int i = 0; i < rows; i++)
{
for(int j = 0; j < cols; j++)
{
process(arr[i][j]);
}
}(행 우선,Row-major)
for(int j = 0; j < cols; j++)
{
for(int i = 0; i < rows; i++)
{
process(arr[i][j]);
}
}(열 우선,Col-major)
들어가기에 앞서
사실 코딩을 하다보면 이중 for문을 하고, 나서 왜 행(row,가로) 먼저 하고, 열(col,세로)을 하는지 의문을 가지지 않고 배우는 경우가 많다.
하지만 실제로 프로그래밍쪽이 아닌 순수 과학이나 데이터 사이언스의 할 경우
Col-major을 쓰는 언어가 있다.
그럼 왜 메이저 언어들은 row-major가 메인이 됐을까?

그 답은 컴퓨터 시스템의 책의 명저중의 명저 Computer Systems: A Programmer's Perspective에 자세히 나와있다.
우선 우리는 컴퓨터의 캐시에 대해서 알아야한다.
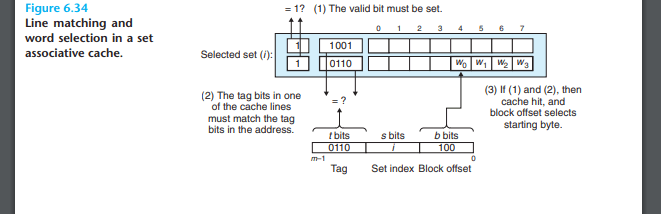
캐시란?
캐시는 메모리 데이터를 블록 단위로 저장하는데
각 블록은 일반적으로 32바이트에서 128 바이트 사이의 크기를 가지고
이 블록은 태그,인덱스, 오프셋으로 구성된다
태그: 메모리 주소 상위 비트로, 캐시 블록이 어떤 메모리 주소를 저장하고 있는지 식별
인덱스:캐시 내에서 블록의 위치를 지정
오프셋:블록 내에서 특정 바이트를 선택
캐시 블록은 메모리 접근 요청이 들어오면 해당 주소의 데이터가 캐시에 있는지 확인하는데, 데이터가 있을 경우 히트(hit)했다고 하고, 없을 경우 미스(miss)했다고 한다.
일반적으로 캐시 미스(데이터가 캐시에 없으면) 해당 데이터를 포함한 캐시 블록 전체를 메모리에서 캐시로 로드한다.
캐시 블록 크기가 클수록 공간적 지역성(spatial locality)을 더 잘 활용할 수 있지만, 미스 한 번당 로드해야 하는 데이터가 커지므로 미스 패널티도 함께 증가한다.

C 배열의 메모리 배치
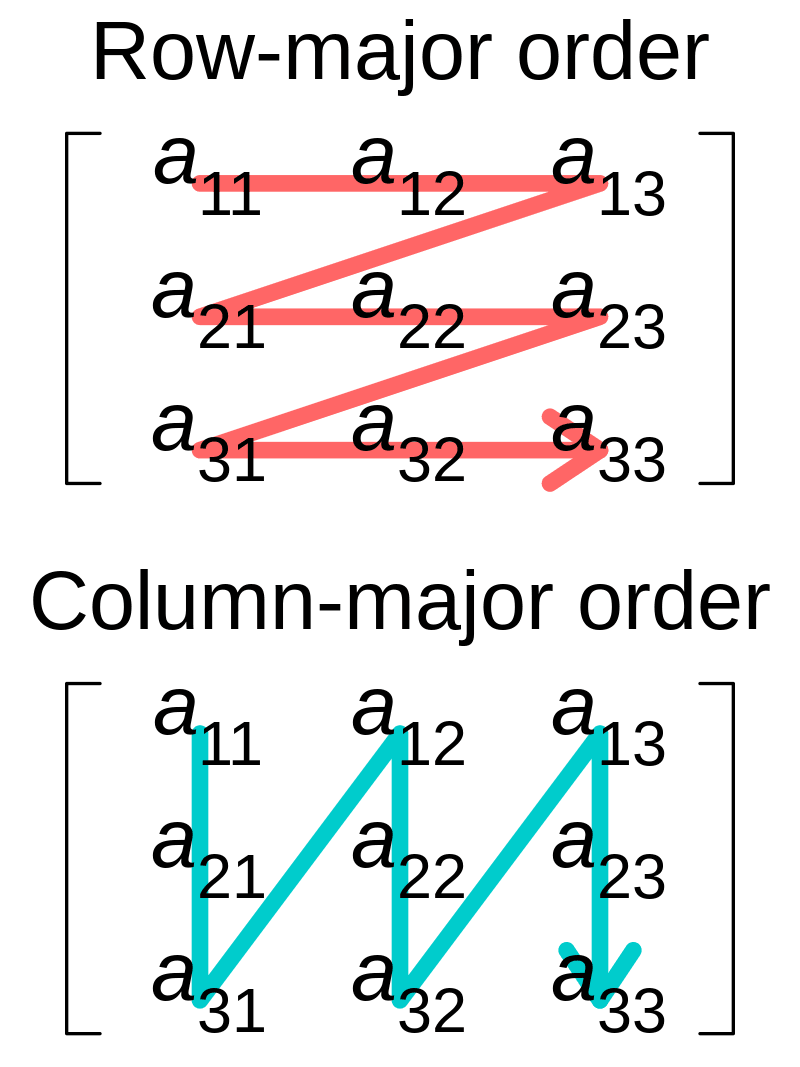
책의 3장에서 다루듯, C에서 배열은 모든 요소가 메모리에 연속적으로 할당된다. 각 요소의 주소는 기본 주소로부터 데이터 타입 크기(L)만큼의 간격으로 나열된다. 다차원 배열의 경우 이 연속 배치가 행 단위로 일어나는데, 이를 Row-major order라고 한다.
즉 a[0][0], a[0][1], a[0][2], ...가 메모리상에서 바로 옆에 붙어 있다.
두 사실을 결합하면
캐시 블록은 연속된 메모리 주소를 통째로 가져오고, 배열은 행 단위로 연속 저장되어 있다. 따라서 하나의 캐시 블록에는 같은 행의 연속된 요소 일부(또는 전체)가 함께 포함된다.
이것이 행 우선 접근이 캐시 친화적인 이유다.
행 우선 접근 a[i][j]의 캐시 동작
for(int i = 0; i < rows; i++)
{
for(int j = 0; j < cols; j++)
{
process(arr[i][j]);
}
}(행 우선 친화적인 코드)
a[0][0]에 접근하는 순간, 캐시는 해당 주소를 포함하는 블록 전체를 로드한다. 블록 크기가 16바이트이고 요소가 4바이트 int라면, a[0][0]부터 a[0][3]까지 네 개의 요소가 한 번에 올라온다.
이후 a[0][1], a[0][2], a[0][3]에 접근할 때는 이미 캐시에 있으므로 전부 히트다. 캐시 미스는 블록당 한 번만 발생하고, 미스율은 1/B(B = 블록 내 요소 수)로 수렴한다.
열 우선 접근 a[j][i]의 캐시 동작
for(int j = 0; j < cols; j++)
{
for(int i = 0; i < rows; i++)
{
process(arr[i][j]);
}
}(열 우선 코드)
a[0][0] 다음에 a[1][0]을 접근하면, 이 두 요소는 서로 다른 행에 속하므로 메모리상 멀리 떨어져 있다. 캐시 블록이 다르기 때문에 매 접근마다 미스가 발생한다.
배열 크기가 캐시 용량을 초과하면, 다시 a[0][0]의 행으로 돌아왔을 때 이미 퇴거(evict)된 상태이므로 또 미스다. 최악의 경우 미스율이 100%에 근접한다.
(앞서 예제를 간단하게 시각화한 예제)
그렇다면 Col-major 언어는?
C 계열 언어에서 배열이 Row-major로 저장되므로 a[i][j] 순서로 접근하는 것이 캐시 친화적이라면, Fortran과 MATLAB에서는 왜 a[j][i] 순서로 접근하는가?
Fortran과 MATLAB은 배열을 열(column)-major로 저장하기 때문이다.
캐시 메모리 자체는 단순히 연속된 메모리 블록(캐시 라인)을 읽어올 뿐이다. 캐시는 Row-major인지 Col-major인지 알지 못한다. 중요한 것은 오직 메모리상의 연속성, 즉 배열이 어떤 순서로 저장되어 있는가이다.
따라서 각 언어의 배열 저장 방식에 따라, 이중 for문의 바깥 루프를 행으로 할지 열로 할지를 선택하는 것이 캐시 효율의 핵심이다.
왜 갈라졌는가 - 공학 vs 과학
C가 Row-major order를 채택한 이유는 포인터 산술과의 궁합이다. a[i][j]의 주소를 base + (i * cols + j) * sizeof(element)로 계산할 때, Row-major가 표기와 연산 모두에서 자연스럽다.
Fortran과 MATLAB이 Col-major order를 채택한 이유는 선형대수의 관습이다. 수학에서 벡터는 열벡터로 표기하는 경우가 압도적으로 많고, 행렬 연산도 열 단위 접근이 빈번하다. 배열 저장 순서를 열 우선으로 맞추면 수학적 표기와 메모리 레이아웃이 일치한다.
정리하면 이렇다. 공학에 가까운 언어(C, C++, C#, Java, Python NumPy 기본값)는 Row-major를, 과학에 가까운 언어(Fortran, MATLAB, Julia, R)는 Col-major를 쓰는 경향이 있다.
더 나아가: 수동적 캐시를 넘어선 기계의 능동성 (Hardware Prefetcher)
여기까지는 과거의 CPU고, 현대 CPU는 행 우선 탐색에서 압도적인 속도를 내는 진짜 이유는 캐시가 단순히 수동적인 저장소에 머물지 않기 때문이다.
CPU 내부에는 메모리 접근 패턴을 실시간으로 감시하고 예측하는 하드웨어 프리페처(Hardware Prefetcher)가 존재한다. 행 단위로 메모리를 순차 접근(Stride-1 Access)하기 시작하면, 프리페처는 "이 코드는 메모리를 일렬로 긁고 있군"이라고 즉각 패턴을 파악한다. 그리고 CPU가 a[0][4]를 미처 요구하기도 전에, 메모리 컨트롤러를 통해 다음 캐시 블록을 미리 L1 캐시로 당겨온다(Prefetching).
이는 우연이 아니다.
현대 CPU의 하드웨어 프리페처는 설계 단계부터 Stride-1, 즉 순차적 메모리 접근을 1순위 최적화 대상으로 삼는다. 세상의 대부분의 코드가 C, C++, Java 계열이고, 이 언어들은 전부 Row-major 배열을 사용하기 때문이다. 프리페처의 우선순위 자체가 Row-major 접근 패턴에 맞춰 설계되어 있다는 뜻이다.
즉, 행 우선 탐색은 단순한 '공간 지역성'을 넘어 CPU의 예측 파이프라인에 완벽하게 올라타는 행위다.
그렇다면 현대 CPU의 프리페처가 그렇게 똑똑하다면, 열 우선 탐색은 stride가 일정한 패턴이니 프리페처가 예측해낼 수 있지 않을까?
맞다. 인텔과 AMD의 최신 아키텍처에는 Stride Prefetcher라는 전용 유닛이 있고, 이 유닛은 메모리 접근 간격이 일정하다는 것을 단 몇 번의 루프 만에 파악해 다음 주소를 미리 계산한다. 즉, arr[0][0] → arr[1][0] → arr[2][0]처럼 rows * sizeof(int) 간격으로 반복되는 패턴은 프리페처가 충분히 감지할 수 있다.
그럼에도 열 우선 탐색이 행 우선을 이길 수 없는 이유는 두 가지 물리적 한계 때문이다.
1. 4KB 페이지 경계의 벽
프리페처는 가상 메모리의 페이지 경계(보통 4KB)를 넘어서 함부로 데이터를 당겨오지 못하도록 하드와이어링되어 있다. 권한 없는 다음 페이지를 무턱대고 프리페치했다가 페이지 폴트나 TLB 미스가 발생하면 운영체제 개입으로 CPU 파이프라인 전체가 멈추기 때문이다.
배열이 클수록 열 우선 접근의 stride가 커지고, 프리페처는 예측을 몇 번 하기도 전에 이 경계에 부딪혀 강제로 동작을 멈춘다.
2. 대역폭 낭비와 캐시 오염
프리페처가 완벽하게 예측해서 데이터를 제때 가져왔다고 가정하자. 루프 안에서 CPU가 실제로 필요한 건 arr[1][0]이라는 4바이트짜리 정수 하나다. 하지만 캐시 컨트롤러는 무조건 64바이트(캐시 라인) 단위로만 움직인다.
실제 필요한 데이터: 4바이트
강제로 로드되는 양: 64바이트
→ 대역폭의 93.75%를 쓰레기 값 페치에 낭비이 60바이트의 쓸모없는 데이터는 캐시에 올라오는 순간 기존에 있던 유용한 데이터를 밀어낸다. 이것이 캐시 오염(Cache Pollution)이다. 프리페처가 아무리 부지런히 데이터를 퍼 날라도 메모리 버스 자체가 포화 상태가 되는 물리적 한계에 봉착한다.
그렇다면 무조건 행 우선이 옳을까?
아니다.
프리페처는 주소의 규칙성을 파악할 뿐, 그 규칙성이 초래하는 대역폭 낭비까지 교정해 주지는 못한다.
핵심은 이것이다. 캐시 라인 64바이트를 낭비 없이 전부 소비하려면, 접근 순서가 메모리 저장 순서와 일치해야 한다. C는 행 우선으로 저장하므로 행 단위로 접근해야 하고, Fortran과 MATLAB은 열 우선으로 저장하므로 열 단위로 접근해야 한다. 저장 방식이 다를 뿐, 자신의 언어 배열 레이아웃에 맞게 접근하면 둘 다 동일하게 프리페처를 100% 활용하고 캐시 라인을 낭비 없이 소비한다.
열 우선이 나쁜 것이 아니다.
C에서 열 우선으로 접근하는 것이 나쁜 것이다.
그리고 Matlab에서 행 우선으로 접근 하는 것 또한 나쁜 것이고.
마치며...
이중 for문을 작성할 때 i가 바깥이고 j가 안쪽인 것은 단순한 관습이 아니다. 그 순서는 사용하는 언어의 배열 저장 방식에서 비롯된 것이고, 그 저장 방식은 캐시 하드웨어의 동작 원리와 직결된다.
다음에 이중 for문을 작성할 때, "이 언어는 배열을 어떤 순서로 저장하지?"라고 한 번 생각해 보는 것은 어떨까.