
기본 알고리즘인 정렬이나 해싱은 어느 하루를 기준으로 해도 수조 번 사용된다. 계산 수요가 증가함에 따라, 이러한 알고리즘이 가능한 한 높은 성능을 갖추는 것은 점점 더 중요해졌다. 과거에 괄목할 만한 진전이 있었음에도 불구하고, 이러한 루틴의 효율을 더 개선하는 일은 인간 연구자에게도, 계산적 접근법에게도 어려운 과제로 남아 있었다. 본 연구에서는 인공지능이 지금까지의 최첨단 수준을 넘어, 기존에 알려지지 않았던 새로운 루틴을 발견할 수 있음을 보인다. 이를 위해 더 나은 정렬 루틴을 찾는 문제를 단일 플레이어 게임으로 정식화하였다. 그리고 이 게임을 수행하도록 새로운 심층 강화학습 에이전트인 AlphaDev를 학습시켰다. AlphaDev는 처음부터 작은 정렬 알고리즘들을 발견했으며, 이들은 기존에 인간이 만든 기준 구현보다 더 우수한 성능을 보였다. 이 알고리즘들은 LLVM 표준 C++ 정렬 라이브러리에 통합되었다. 정렬 라이브러리의 이 부분이 변경되었다는 것은, 강화학습을 통해 자동으로 발견된 알고리즘으로 기존 구성 요소 하나가 대체되었음을 의미한다. 또한 본 연구는 추가적인 영역들에서의 결과도 제시하며, 이 접근법이 일반적으로 적용 가능함을 보여준다. -Faster sorting algorithms discovered using deep reinforcement learning. Nature(2023)
시작하기에 앞서
알고리즘 교과서에서 정렬은 보통 "해결된 문제"로 취급된다. Timsort, pdqsort, introsort 같은 하이브리드 알고리즘들이 이미 수십 년간 최적화되어 있고, 표준 라이브러리에 들어간 코드는 전문가들이 반복 검토한 결과물이다.
2023년 구글 딥마인드의 AlphaDev는 그 전제를 틀렸다고 증명했다. 발견한 것은 새로운 알고리즘이 아니다.
기존 sort3 커널에서 명령 하나를 제거하는 instruction sequence다. 그리고 그 한 줄이 LLVM libc++에 반영되었다.
이 글은 그 발견이 왜 의미 있는지를 설명한다.
그러려면 퀵소트(퀵정렬)부터 시작해야 한다.
(퀵 정렬 애니메이션)
퀵소트(퀵 정렬)의 기본 구조
퀵소트는 분할 정복(divide and conquer) 알고리즘이다. 동작 원리는 단순하다.
1.배열에서 pivot을 하나 고른다.
2.pivot보다 작은 원소는 왼쪽, 큰 원소는 오른쪽으로 분리한다. 이 단계를 partition이라 한다.
3.왼쪽 부분 배열과 오른쪽 부분 배열에 대해 재귀적으로 같은 과정을 반복한다.
코드로 보면 다음과 같다.
void quicksort(int* arr, int lo, int hi) {
if (lo >= hi) return;
int pivot_idx = partition(arr, lo, hi);
quicksort(arr, lo, pivot_idx - 1);
quicksort(arr, pivot_idx + 1, hi);
}퀵소트에 필요한(partition)의 구현은 여러가지 있지만, Lomuto Scheme 기준으로는 pivot을 맨 오른쪽에 두고 왼쪽에서부터 순회하며 pivot보다 작은 원소를 앞으로 밀어낸다.
int partition(int* arr, int lo, int hi) {
int pivot = arr[hi];
int i = lo - 1;
for (int j = lo; j < hi; j++) {
if (arr[j] <= pivot) {
i++;
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i + 1], arr[hi]);
return i + 1;
}평균 시간복잡도는 O(n log n)이다. 분할(partition)이 매번 배열을 절반 근처로 나눈다고 가정하면, 재귀 깊이는 log n이고 각 단계에서 O(n) 작업이 발생하기 때문이다.
최악 케이스와 pivot 선택 문제
퀵소트의 약점은 pivot 선택에 있다. partition 이후 두 부분 배열의 크기가 균등할수록 성능이 좋고, 한쪽으로 치우칠수록 나빠진다.
최악의 경우는 매번 pivot이 최솟값이나 최댓값으로 선택될 때다. 이러면 한쪽 부분 배열의 크기가 항상 0이 되고, 재귀 깊이가 n이 된다. 시간복잡도는 O(n²)로 떨어진다.
이 상황이 발생하는 대표적인 입력이 있다.
1.이미 정렬된 배열에 첫 번째 원소를 pivot으로 선택하는 경우
2.역순으로 정렬된 배열에 마지막 원소를 pivot으로 선택하는 경우
모든 원소가 동일한 경우
단순한 퀵소트 구현에서 정렬된 입력이 가장 느리다는 것은 직관에 반한다.
라이브러리 수준에서 이 문제를 방치할 수 없는 이유다.
초기 해결책 중 하나는 pivot을 무작위로 선택하는 것이었다.
랜덤 pivot은 특정 입력에 대한 최악 케이스를 확률적으로 희석시킨다. 하지만 난수 생성 비용이 있고, 최악 케이스 자체를 제거하지는 못한다.
median-of-3 전략
int median_of_3(int* arr, int lo, int hi) {
int mid = lo + (hi - lo) / 2;
if (arr[lo] > arr[mid]) std::swap(arr[lo], arr[mid]);
if (arr[lo] > arr[hi]) std::swap(arr[lo], arr[hi]);
if (arr[mid] > arr[hi]) std::swap(arr[mid], arr[hi]);
return mid;
}(median-of-3)
((lo + hi) / 2 대신 lo + (hi - lo) / 2를 쓴 이유는 lo + hi가 INT_MAX를 넘을 때 오버플로가 발생하기때문이고, C++에서 이 차이가 실제로 버그로 이어진다)
실용적인 대안으로 등장한 것이 median-of-3 pivot 선택이다. 배열의 첫 번째, 중간, 마지막 원소 중 중앙값을 pivot으로 선택하는 방식이다.
이 방식은 이미 정렬된 배열이나 역순 배열에서 항상 최악의 pivot이 선택되는 문제를 완화한다.
세 후보 중 중앙값은 전체 배열의 실제 중앙값에 가까울 가능성이 높기 때문이다.
더 중요한 점은 부수효과(Side effect)다. median-of-3 과정에서 세 원소를 비교하고 위치를 조정하면, 그 세 원소는 이미 정렬된 상태가 된다. 이 부분 배열이 partition 이후 경계에 위치하게 되므로, 이후 재귀 호출에서 이 세 원소를 다시 처리할 필요가 없다. 실질적으로 partition 비용도 줄어든다.
Sedgewick이 1970년대에 이 방식을 체계화한 이후, median-of-3는 실용적인 퀵소트 구현의 표준 전략이 되었다.
최악 케이스를 완전히 제거하려면 - introsort
median-of-3로도 최악 케이스를 완전히 없앨 수는 없다. 극단적인 입력이 반복되거나, 의도적으로 구성된 입력에 대해서는 여전히 O(n²)가 발생할 수 있다.
이 문제를 해결한 것이 introsort다. 1997년 David Musser가 제안했으며, 퀵소트와 힙소트를 결합한 하이브리드 알고리즘이다.
동작 방식은 다음과 같다.
1.재귀 깊이를 추적한다. 임계값은 보통
2 * log2(n)이다.2.재귀 깊이가 임계값 이하이면 퀵소트(median-of-3 pivot)를 사용한다.
3.재귀 깊이가 임계값을 초과하면 힙소트로 전환한다.
힙소트는 O(n log n)이 항상 보장되므로, 퀵소트가 최악 케이스로 빠지기 시작하는 시점을 감지해 힙소트로 전환하면 전체 시간복잡도 보장이 가능하다.
여기에 한 가지 최적화가 더 붙는다. 부분 배열의 크기가 일정 임계값(보통 16 이하) 이하가 되면 삽입 정렬로 전환한다. 소규모 배열에서는 삽입 정렬의 상수 인자가 퀵소트보다 작기 때문이다. 캐시 친화성도 삽입 정렬이 유리하다.
static constexpr int THRESHOLD = 16;
void introsort(int* arr, int lo, int hi, int depth_limit) {
if (hi - lo < THRESHOLD) {
insertion_sort(arr, lo, hi);
return;
}
if (depth_limit == 0) {
heap_sort(arr, lo, hi);
return;
}
int pivot_idx = median_of_3(arr, lo, hi);
pivot_idx = partition(arr, lo, hi);
introsort(arr, lo, pivot_idx - 1, depth_limit - 1);
introsort(arr, pivot_idx + 1, hi, depth_limit - 1);
}
void sort(int* arr, int n) {
int depth_limit = 2 * static_cast<int>(std::log2(n));
introsort(arr, 0, n - 1, depth_limit);
}C++ STL의 std::sort는 introsort 기반이다. GCC libstdc++, LLVM libc++ 모두 이 구조를 따른다.
자, 근데 이걸 왜 글쓴이는 쓴걸까?
20여년간 이어진 이 문제에 대해서 AI가 새로운 해법을 23년도에 발견해냈기 때문이다.
우선 그전에 AI가 대체 무엇을 발견했는가에 대해서 알기 위해 필요한 기초지식을 쌓아보자.
커널이란 무엇인가?
Kernel (핵심)
보통 핵심이라고하는데, 컴퓨터 좀 한다하는 사람들은 다 커널하면 OS를 말한다 생각하지만,
참고로 여기서 커널이란 일반적 운영체제를 뜻하는 Kernel이라기보다는 더 큰 알고리즘 내부에서 호출되는 아주 작은 연산 단위를 뜻한다.
23년도에 AI, AlphaDev가 개선한 것은 이 고정 크기 커널들이다.
sort라는 이름의 커널들은 정렬에 주로 쓰이는 작은 연산 단위였는데,
구체적으로는 sort3, sort4, sort5가 대상이었고, 각각에서 기존 인간이 작성한 최적 구현보다 더 적은 명령어로 동작하는 명령 시퀀스를 찾아냈다.
즉 군더더기를 뺀 더 효율적인 시퀀스 발견한 것이다.
이제 sort들의 연산을 정리하면
sort1은 원소 1개, sort2는 원소 2개, sort3는 원소 3개를 처리하는 코드 블록이다.
sort1은 아무 작업이 없는 연산이다.
sort2는 비교 한 번과 조건부 교환 한 번으로 끝난다.
sort3는 정확히 3개 원소를 정렬하는 고정 크기 커널이다.
이 커널들은 독립적으로 호출되기도 하지만, 주로 더 큰 정렬 알고리즘의 내부 구성 요소로 사용된다.
왜 sort3?
sort3는 정확히 3개 원소를 정렬하는 고정 크기 커널이며,
입력 크기가 정확히 3개로 고정된 정렬 루틴이다.
일반 정렬처럼 임의 길이 배열을 처리하지 않으며, 길이가 컴파일 시점에 확정되어 있으므로 루프나 재귀 없이 비교(compare) 와 조건부 교환(conditional swap) 만으로 구성된다.
이런 커널은 단독으로도 사용할 수 있지만, 실제로는 std::sort 같은 더 큰 정렬 알고리즘 안에서 알고리즘을 구성하는 코드 블록으로 더 자주 쓰인다.
예를 들어 introsort는 pivot 선택을 위한 median-of-3 단계에서 sort3를 호출하고, 작은 구간으로 내려가면 삽입 정렬 전환 구간에서도 2~4개 원소 수준의 소규모 정렬 루틴을 반복적으로 사용한다.
즉 sort3는 “3개짜리 장난감 정렬”이 아니라,
대형 정렬 알고리즘이 반복적으로 의존하는 작은 핵심 연산이다.
크기는 작지만 호출 빈도가 매우 높기 때문에, 여기서 명령어 한두 개를 줄이는 최적화도 전체 시스템 수준에서는 큰 누적 효과를 낼 수 있다.

(a . 최대 두 개의 요소로 이루어진 입력 시퀀스를 정렬하는 변수 정렬 함수의 C++ 구현.
b . a 의 C++ 구현은 다음과 같은 저수준 어셈블리 표현으로 컴파일된다.)
이것이 왜 퀵정렬과 관련이 있는가?
우선 퀵정렬의 구현방식을 생각해보자.
introsort의 두 지점에서 소규모 배열 정렬이 필요하다.
첫째, median-of-3 pivot 선택 단계에서 세 원소를 정렬한다.
이것이 sort3다.
둘째, 재귀 하단에서 삽입 정렬로 전환할 때, 삽입 정렬 자체가 내부적으로 2~4개 원소를 비교하고 정렬하는 작업을 반복한다.
말로 설명하면 어렵지만 간단히 생각하면 학급에서 줄 세우기와 같다.
둘을 비교해서 키가 작으면 앞으로, 키가 크면 뒤로, 이런식으로 반복해서 나누는 것이다.
자, 그럼 이걸 우리 인간은 어떻게 표기했을까?
그리고 그걸 알기 위해서 우리는 어셈블리어에 대해서 조금 알아야한다.
어셈블리 기초 - 코드를 읽기 전에
어셈블리는 CPU가 직접 이해하는 명령어 수준의 언어다. C나 Python처럼 변수나 함수 호출이 없다. 대신 레지스터와 명령어로 동작한다.
레지스터는 CPU 안에 있는 작은 임시 저장공간이다. 변수와 비슷하지만 개수가 정해져 있고, 연산은 반드시 레지스터를 거쳐야 한다. x86-64 기준으로 범용 레지스터는 rax, rbx, rcx 등이 있고, 이 글에서는 설명을 단순화하기 위해 P, Q, R, S로 표기한다.
아래에서 사용하는 명령어는 네 가지다.
명령어 | 의미 | 예시 |
|---|---|---|
| B의 값을 A에 복사한다 |
|
| A와 B를 비교해 결과를 플래그에 기록한다. 값 자체는 바뀌지 않는다 |
|
| 직전 |
|
| 직전 |
|
cmovg와 cmovl은 조건부 이동(conditional move)이다. if문 없이 분기 없는 비교와 선택을 한 줄로 처리한다. 분기 예측 실패(branch misprediction) 비용이 없어서 정렬처럼 비교가 반복되는 코드에서 성능상 유리하다.
cmp 이후 플래그가 어떻게 작동하는지 예를 들면 다음과 같다.
cmp P, R ; P와 R을 비교, 결과를 플래그에 기록
cmovg P, R ; P > R이었으면 P = R, 즉 P는 min(P, R)이 된다
cmovl R, S ; P < R이었으면 R = S, 즉 R은 max(P, R)이 된다이 두 줄이 하는 일은 결국 P = min(A, C), R = max(A, C)를 만드는 것이다.
이 정도면 아래 sort3 코드를 한 줄씩 따라갈 수 있다.
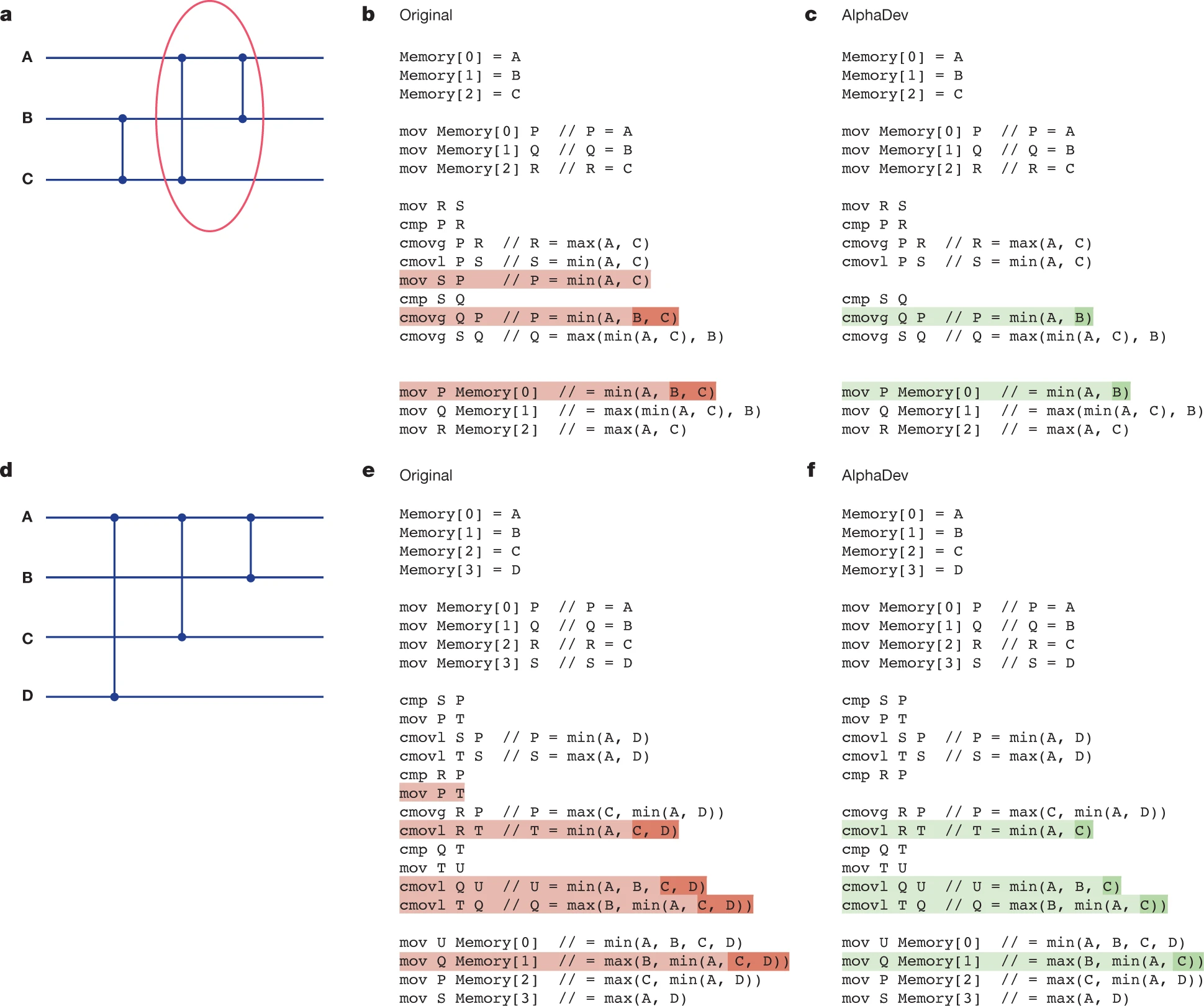
인간이 짜는 sort3
x86 기준으로 3개 원소 A, B, C를 정렬하는 assembly 흐름은 다음과 같다. 레지스터 P, Q, R, S를 사용한다.
; 초기 상태: P=A, Q=B, R=C
mov R, S ; S = C (C 보존)
cmp P, R ; A vs C
cmovg P, R ; P = min(A, C)
cmovl R, S ; R = max(A, C)
mov S, P ; S = min(A, C) <- 핵심 지점
cmp S, Q ; min(A,C) vs B
cmovg Q, P ; P = min(A, B, C)
cmovg S, Q ; S = 중간값mov S P의 역할은 명확하다. 이전 비교에서 P에 min(A, C)를 담았는데, 다음 비교에서 이 값을 안전하게 쓰기 위해 S에 복사해 두는 것이다.
인간은 중간 상태를 명시적으로 정리하고 다음 단계로 넘어간다.
이 습관은 가독성과 검증 용이성을 높이고, 코드를 지역적으로 이해하기 쉽게 만든다.
이렇게 보면 이해가 어려우니 예시를 들겠다.
예시: 반 전체를 키 순서로 줄 세운다고 하자.
선생님이 한 명을 기준(pivot)으로 지목한다.
나머지 학생들은 그 기준보다 키가 작으면 왼쪽, 크면 오른쪽으로 이동한다. 한 번의 정렬이 끝나면 기준으로 지목된 학생은 자기 자리가 확정된다.
그리고 이제 왼쪽 무리와 오른쪽 무리에서 같은 과정을 반복한다.
무리가 한 명이 될 때까지.
이것이 퀵소트다.
매 단계마다 한 명씩 자리가 확정되고, 나머지는 점점 작은 무리로 쪼개진다.
그리고 퀵소트 안에서
선생님이 기준(pivot)을 지목할 때, 후보가 세 명이다.
맨 앞, 가운데, 맨 뒤. 이 세 명 중 중간 키를 가진 학생을 기준으로 삼는다.
그러려면 세 명을 먼저 키 순서대로 세워야 한다.
이 세 명을 정렬하는 작업이 sort3다.
선생님은 세 명을 줄 세우고 나서, 그 결과를 칠판에 기록한다. "가운데 학생이 pivot이다. 그리고 세 명의 순서는 이미 확정되었다." 이 기록이 이후 전체 정렬의 전제가 된다.
무리가 줄어들어 세 명 이하가 남으면 다시 sort3가 호출된다. 반 전체를 정렬하는 동안 sort3는 재귀 트리의 거의 모든 단계에서 실행된다.
그럼 AI는 어떤가?
AlphaDev가 찾은 코드
AlphaDev의 결과는 다음과 같다.
; 초기 상태: P=A, Q=B, R=C
mov R, S ; S = C
cmp P, R ; A vs C
cmovg P, R ; P = min(A, C)
cmovl R, S ; R = max(A, C)
; mov S P <- 제거됨
cmp S, Q ; S = C, B와 비교
cmovg Q, P ; 조건부 이동
cmovg S, Q ; 조건부 이동mov S P가 사라졌다. 이 시점에서 S는 원래의 C 값을 그대로 들고 있다. min(A, C)가 아니다. 직관적으로 잘 못되보이고 이해가 어려워보인다.
(원본 논문에 나온 코드와 이미지)
왜 제거해도 되는가?
이 코드는 독립 실행 코드가 아니다. sorting network 안의 부분 코드다.
sorting network는 비교기(comparator)를 고정된 순서로 연결해 정렬을 수행하는 구조다. 각 비교기는 두 입력을 받아 min과 max를 출력한다. 중요한 점은 앞선 비교기의 출력이 뒤 비교기의 입력 조건을 제약한다는 것이다.
AlphaDev의 코드 조각이 실행되는 시점에는 앞선 비교기가 이미 B ≤ C를 보장해 놓은 상태다. 이 전제가 있으면 분석이 달라진다.
mov S P를 제거한 상태에서 S = C다. B ≤ C가 성립하므로 cmp S Q, 즉 C와 B의 비교 결과는 이미 방향이 정해져 있다. 이 조건 아래에서 이후 cmovg 두 개가 만드는 최종 출력 3개는 mov S P가 있을 때와 동일한 정렬 결과를 형성한다.
단계별 레지스터 상태를 추적하면 다음과 같다.
단계 | P | Q | R | S | 전제 |
|---|---|---|---|---|---|
초기 | A | B | C | - | B ≤ C |
mov R, S | A | B | C | C | |
cmovg P, R | min(A,C) | B | C | C | |
cmovl R, S | min(A,C) | B | max(A,C) | C | |
cmp S, Q (S=C, Q=B) | C ≥ B 이미 성립 | ||||
cmovg Q, P | min(A,C,B) | B | max(A,C) | C | |
cmovg S, Q | min(A,C,B) | 중간값 | max(A,C) | 중간값 |
로컬 코드만 보면 틀린 것처럼 보이지만, 전체 네트워크의 불변식을 포함하면 맞다. Nature 논문은 이 구조를 AlphaDev swap move라고 명명한다.
이걸 앞 선 학급 비유로하면 어떻게 이해해야할까?
이번엔 세 명만 줄을 세운다. A, B, C.
인간은 이렇게 한다. A와 C를 먼저 비교해 순서를 잡고, 그 결과를 칠판에 메모한다. "지금 앞에 선 애가 min(A,C)다."
그 메모를 보고 B와 비교해 최종 순서를 완성한다.
중간 결과를 반드시 적어두고 넘어간다.
그런데 이 반에서는 수업 시작 전에 이미 B와 C의 키를 재서 "B가 C보다 작다"는 사실이 칠판에 적혀 있다. 이 사실을 알고 있는 교사라면 굳이 칠판에 메모할 필요가 없다. A와 C를 비교한 직후, 칠판의 그 사실을 전제로 삼아 바로 다음 비교로 넘어갈 수 있다. 최종 줄 세우기 결과는 동일하다.
AlphaDev가 제거한 한 줄은 그 칠판 메모다.
인간은 다음 단계가 무엇을 전제하는지 따지지 않고 습관적으로 중간 상태를 적어두지만, AlphaDev는 칠판에 이미 적힌 사실, 즉 앞 단계가 확보한 불변식을 전제로 삼아 그 메모 자체를 없앴다.

Nature 논문은 이 루틴들이 매일 수조 번(trillions of times) 실행된다고 적고 있다. 과장이 아니다. 전 세계 서버에서 실행되는 C++ 프로그램, 데이터베이스 엔진, 네트워크 스택, 파일 시스템이 모두 std::sort를 호출한다.
즉, std::sort를 호출할 때마다 sort3는 재귀 트리의 거의 모든 내부 노드에서 실행된다. n개 원소를 정렬하면 재귀 트리의 내부 노드 수는 O(n)이고, 각 노드에서 sort3가 호출되므로 전체 정렬 과정에서 sort3의 실행 횟수도 O(n)에 비례한다.
그렇다면 정말 몇 조번이 실행되고 있다는 것이 과장이 아니었을 것이다.
왜 인간은 이걸 못 찾았나
인간은 코드를 지역적으로 검증한다.
"하지 않은 비교를 하고 넘어가야, 다음 비교가 안전하다"
“중간 상태를 한 번 명확히 정리하고 넘어가야 한다”는 식으로 사고한다.
이 습관은 가독성과 검증 용이성을 높이고, 코드를 지역적으로 이해하기 쉽게 만든다.
AlphaDev는 그 제약이 없다.
레지스터 상태 전이 전체를 탐색 공간으로 보고, 최종 출력 3개가 정렬 상태를 만족하는지만 판단한다. 각 어셈블리 명령을 하나의 행동(action)으로 보고, 정렬 정확성과 명령 수를 보상(reward)으로 설계한 강화학습 구조가 이 탐색을 가능하게 했다.
전체 알고리즘이 보장하는 불변식을 이용해 로컬 정리용 복사를 제거하는 것은, 그 탐색 과정에서 자연스럽게 발견될 수 있는 수순이었다. 인간이 수십 년간 당연하게 두었던 한 줄이 사라진 이유는 결국 탐색 단위의 차이에 있다.

(콜럼버스의 달걀)
마치며...
이 발견의 핵심은 AI가 인간보다 더 우월하다는 데 있지 않다.
중요한 것은 탐색 단위의 차이다.
인간은 코드를 지역적으로 이해하고, 중간 상태를 정리하며, 각 단계를 안전하게 검증하는 방식으로 사고한다.
반면 AlphaDev는 전체 상태 공간을 대상으로, 최종 출력이 조건을 만족하는지와 명령 수가 최소화되는지만 본다.
그 차이 때문에 인간이 수십 년간 당연하게 유지해온 한 줄이 사라졌다.
즉 우리가 ‘당연하다’고 믿는 코드 패턴 중 일부는 문제의 본질이라기보다, 인간이 이해하고 검증하기 쉬운 형태에 맞추어 굳어진 습관일 수 있다.
AlphaDev는 그 사실을 작은 예제로 증명했다.
이것은 콜럼버스의 달걀과 비슷하다.
정답을 본 뒤에는 누구나 단순하다고 말할 수 있다.
하지만 진짜 어려운 것은, 아무도 의심하지 않던 전제를 처음으로 깨는 일이다.
AlphaDev가 보여준 것은 더 나은 프로그래밍이 아니라, 인간이 당연하게 여긴 구조를 다른 탐색 방식으로 다시 볼 수 있다는 가능성이다.
이제 인간의 인지적 습관만이 아니라, AI라는 새로운 탐색 도구도 갖게 되었다.
그것을 인간과 같은 의미의 지능이라고 부를지는 내 개인적으로는 망설여진다.
하지만 우리가 너무도 당연하게 여겨 온 것들이 이런 방식으로 하나씩 깨져 나간다는 사실은, 분명 지적인 흥분을 준다.
참고문헌:Mankowitz, D. J., Michi, A., Zhernov, A., Gelmi, M., Selvi, M., Paduraru, C., Leurent, E., Iqbal, S., Lespiau, J.-B., Ahern, A., Köppe, T., Millikin, K., Gaffney, S., Elster, S., Broshear, J., Tsing, A., Polosukhin, I., Pikhtin, A., Sifre, L., Singh, S., … Silver, D. (2023). Faster sorting algorithms discovered using deep reinforcement learning. Nature, 618(7964), 257–263. https://doi.org/10.1038/s41586-023-06004-9