
빠른 코어 메모리(약 32,000 단어)를 더 큰 느린 코어 메모리(약 1,000,000 단어)의 슬레이브(slave) 로 사용하는 방법을 논의한다.
이를 통해 실제 사용 사례에서 유효한 접근 시간(effective access time)이 느린 메모리보다 빠른 메모리에 더 가까워지도록 설계할 수 있다.
-Slave Memories and Dynamic Storage Allocation" (1965, Maurice Wilkes)
들어가기 앞서서...
우리는 항상 캐시 친화적인 프로그래밍을 하길 강요받는다.
현대 프로세서는 CPU 성능 뿐만 아니라 메모리 대역폭과 캐시 효율성이 성능의 핵심 요소가 되고 있다.
같은 연산을 수행하더라도 메모리 접근 방식에 따라 성능 차이가 극단적으로 벌어지고, 이를 이해하고 최적화 하는 것이 캐시 최적화 프로그래밍이다.
그렇다면 캐시란 무엇인가에 대해서 이해해 보자
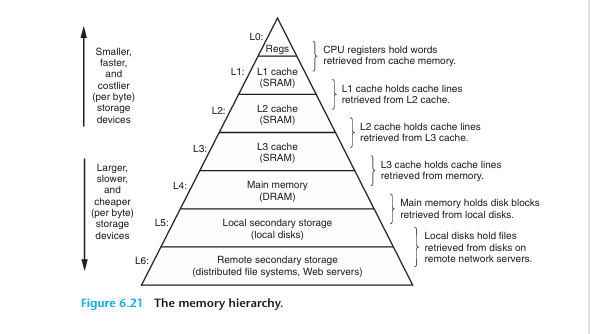
(캐시 계층구조)
캐시란 무엇인가?
캐시는 CPU와 메모리(RAM)사이의 속도 격차를 해결하기 위한 고속 메모리이다.
CPU가 데이터를 처리할때마다 RAM에 직접 접근하면 성능이 크게 저하되므로, 자주 사용하는 데이터를 캐시에 접근해 접근시간을 단축한다.
캐시는 계층 구조를 가지고 있고, 현대의 캐시는 보통 L1,L2,L3의 3계층을 가진다. (드물게는 L4까지 있다)
L1은 가장 작고 빠르며, L3로 갈수록 크기가 커지지만 속도는 느려진다.
그렇다면, 이 역사는 어떻게 시작됐을까?

캐시의 역사
캐시 메모리 필요성 자체는 폰 노이만의 기념비적인 논문이자, 폰 노이만 구조를 확립하는데 결정적인 역할을 한 논문
"Preliminary Discussion of the Logical Design of an Electronic Computing Instrument(1946)
에서도 인지되어있다.
이 논문에서는 고속 연산 장치와 메모리 속도를 불균형을 인지하고 있었고, 이를 폰 노이만 구조의 한계로 인해 캐시 메모리와 같은 해결책의 필요성을 간접적으로 시사했다.
캐시 메모리의 정확한 첫 시작은
모리스 윌크스 교수의 Slave Memories and Dynamic Storage Allocation (1965, Maurice Wilkes)이다.
그리고 여기서 캐시메모리는 종속 메모리(Slave Memory) 라는 명칭으로 확인 할 수 있다.
종속 메모리(Slave Memory)는 주 메모리에 종속되어 작동하는 계층적 구조임을 암시하고, 캐시 메모리가 주 메모리(Core Memory)에 데이터를 일부 복사하며 사용한다는 것을 의미한다.
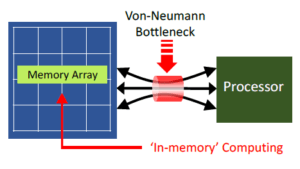
(폰 노이만 병목 이미지)
이 당시 1960년 중반 컴퓨터 기술은 급격히 발전하고 있었지만,메모리 시스템은 노이만 병목(Von Neumann bottleneck) 현상이 심했다.
이유는 당시 주 메모리(Core Memory)는 자기 코어 메모리(Magnetic Core Memory)가 주로 사용되었는데,당시 주 메모리로 사용된 자기 코어 메모리는 안정적이지만 읽기/쓰기 속도가 마이크로초 단위로 느려 CPU의 빠른 연산 속도를 따라가지 못했다. 이때문에 전체 시스템 성능이 저하된다.
따라서 CPU와 메모리 사이의 데이터 전송 속도 차이로 인해 발생하는 노이만 병목 문제가 심각했다.

(모리스 윌크스)
윌크스 교수는 이러한 과정에서 1965년 Slave Memories and Dynamic Storage Allocation에서 SlaveMemory라는 개념을 제시한다
Slave Memories (종속 메모리)는 CPU와 주 메모리 사이에 고속의 소규모 메모리 계층을 두어 자주 사용되는 데이터에 대한 접근 속도를 높여
전체 시스템 성능을 향상시키는 개념인데, 오늘날의 캐시 메모리의 원형에 해당하는 아이디어이다.

이후에 IBM System/360 Model 85는 모리스 윌크스 교수의 슬레이브 메모리 개념을 바탕으로 기술적 난관을 극복하고, 상용 시스템에 최초로 도입한 후,
cache 라는 용어를 정착 시킨다.
이 cache 라는 용어는 프랑스어인 'cache(은닉처)'에서 유래했고, 자주 사용하는 데이터를 숨겨두었다가 빠르게 접근 할 수 있다는 메모리라는 의미를 내포한다.
지금으로 보기엔 kb 수준이라 매우 작은 수준이지만 CPU 성능 향상에 도움이 되었고,
이것이 L1(Level1) 캐시 메모리의 원형으로 보고 있다. 다만 당시에는 '캐시'라는 이름만 사용되었을뿐, L1이라는 이름이 사용되지 않았다.
이후에 다층 구조로 정리되어감에 따라 L1과 L2로 분류한 것이다.
어쨌건 L1 캐시만으로는 CPU와 메인 메모리 간의 속도 격차를 완전히 해소하기 어려워진다. L1 캐시를 보조하는 더 큰 용량의 캐시에 대한 필요성이 대두 된다.


새로운 세대의 프로세서 속도가 점점 빨라짐에 따라, CPU 사이클 시간과 주 메모리 접근 시간 간의 차이가 더욱 커질 것이다.
이 차이가 증가함에 따라, 단일 계층(single-level) 캐시를 설계하는 것이 더욱 어려워진다.
즉, 단일 계층 캐시가 이 빠른 사이클 시간과 맞먹을 만큼 충분히 빠르면서도, 느린 주 메모리 접근 시간을 효과적으로 숨길 만큼 충분히 크도록 설계하기가 어렵다.
이 문제를 해결하는 한 가지 방법은 다중 계층 캐시(multi-level cache hierarchy)를 사용하는 것이다.
본 논문에서는 다중 계층 캐시의 구성 방식과 프로그램 실행 시간(program execution time) 간의 관계를 연구한다.
-Characteristics of Performance-Optimal Multi-Level Cache Hierarchies(Steven Przybylski, Mark Horowitz, John Hennessy,1989)
다층 캐시 구조
처음에는 L2(Level2) 캐시의 이름을 L2라는 이름을 하지 않았지만
이후에 1980년대 후반 다층 캐시 구조의 필요성이 대두됨에 따라 자연스레 정립된 개념으로 여겨진다.
1989년 다층 계층 캐시 구조(Multi-Level cache hierarchy)를 도입하는데, Characteristics of Performance-Optimal Multi-Level Cache Hierarchies
논문은 초창기에 그 필요성을 분석한 논문으로 유명하다.
어쨌건 L1에서 L2가 생기고, 외부 칩 형태로 L2를 탑재하였고, 인텔 펜티엄 프로(1995년)에서
CPU 패키지내 L2 캐시를 통합하는 방식이 등장하면서 L2 캐시는 널리 보급된다.(On-Chip Cache)
그리고 컴퓨터 성능이 발달함에 따라
CPU에 코어가 여러개로 늘어나면서, 각 코어가 효율적으로 캐시를 공유하고 데이터 일관성을 유지하는 것이 중요한 과제가 되었다.
그리고 그것의 해결책으로 등장한 것이 L3 캐시이다.
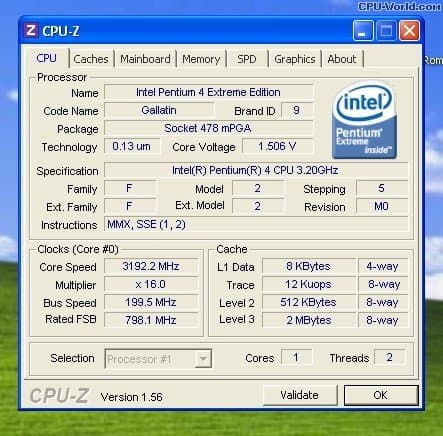
(최초의 소비자용 CPU에서 L3 캐시를 탑재했다고 알려진 인텔 펜티엄 4 Extreme에디션 2003)
물론 최근의 환경에선 L3 캐시가 다중 코어 환경에서 공유 캐시로 동작하면서 성능을 향상 시켰지만
현대 시스템에서는 CPU와 메모리 간의 대역폭 문제, 그래픽 및 AI 연산 증가로 초고속 메모리 접근 필요성으로 인해
L4 캐시의 필요성이 대두되고 있다. L4 캐시는 또한 CPU 뿐만 아니라 내장 GPU(iGPU)와도 공유될 수 있고,
실제로 인텔에서 Crystal Well이라는 이름으로 L4 캐시를 2013년도에 도입했지만,
2026년 현재도 여전히 비용이 너무 비싸서 아직까지 L3만큼 상용화 되진 않고, 주로 고성능 서버에서나 사용되고 있다.
자 이제 캐시의 계층 구조를 요약해보자
캐시의 계층 구조 (Memory Hierarchy)
계층 | 용량 | 접근 시간 | 위치 | 특징 |
|---|---|---|---|---|
L1 | 32~64KB | 1~4 CPU 사이클 | CPU 코어 내장 | - 가장 빠르고 작은 캐시 |
L2 | 256KB~1MB | 10~20 사이클 | CPU 코어 근처 | - 각 코어마다 개별적으로 존재 |
L3 | 16~64MB | 50~100 사이클 | 여러 코어가 공유 | - 여러 코어가 공유하는 캐시 |
L4 | 64MB~256MB+ | 150~300 사이클 | CPU 패키지 내 또는 외부 칩 | - 일부 고성능 서버, AI 연산, 내장 GPU(iGPU)에서 사용 |
DRAM | 8GB~1TB+ | 300~500 사이클 | 메인보드 DIMM 슬롯 | - 시스템 전체 메모리 |
- 계층
L1
- 용량
32~64KB
- 접근 시간
1~4 CPU 사이클
- 위치
CPU 코어 내장
- 특징
- 가장 빠르고 작은 캐시
- 명령어 캐시 & 데이터 캐시 분리 (L1I, L1D)
- 계층
L2
- 용량
256KB~1MB
- 접근 시간
10~20 사이클
- 위치
CPU 코어 근처
- 특징
- 각 코어마다 개별적으로 존재
- L1 캐시보다 크지만 속도는 느림
- 계층
L3
- 용량
16~64MB
- 접근 시간
50~100 사이클
- 위치
여러 코어가 공유
- 특징
- 여러 코어가 공유하는 캐시
- 캐시 코히어런스 관리 역할
- 계층
L4
- 용량
64MB~256MB+
- 접근 시간
150~300 사이클
- 위치
CPU 패키지 내 또는 외부 칩
- 특징
- 일부 고성능 서버, AI 연산, 내장 GPU(iGPU)에서 사용
- CPU뿐만 아니라 GPU, 메모리 컨트롤러와도 공유 가능
- 계층
DRAM
- 용량
8GB~1TB+
- 접근 시간
300~500 사이클
- 위치
메인보드 DIMM 슬롯
- 특징
- 시스템 전체 메모리
- L4 캐시보다 크지만 속도는 느림
- 전원이 꺼지면 데이터가 사라지는 휘발성 메모리(Volatile Memory)
L1-> L4로 갈수록 점점 더 크지만 속도가 느려지는 계층 구조이며, 캐시 미스가 발생시 DRAM을 참조해야하는데, 이 경우 CPU 성능을 크게 저하시킨다.
캐시 미스가 발생시 RAM에서 데이터를 가져올땐 일반적으로 100~300 사이클 정도 걸린다.
L4 캐시의 용량이 커질수록 DRAM과 유사해지고, L4 캐시를 탑재하는 것보다 빠른 DRAM을 사용하는 것이 비용 대비 효율적이라 아직까지는 소비자용 PC에서는 적극적인 도입이 이루어지고 있지 않다
특히 HBM(High Bandwidth Memory)가 등장함에 따라 L4 캐시 의 역할을 대체하기도해서 L4는 서버, AI 가속기등 특수한 환경에서만 현재 사용되고 있다.
하지만 앞으로 어떻게 될지 아직은 모를 일이다.
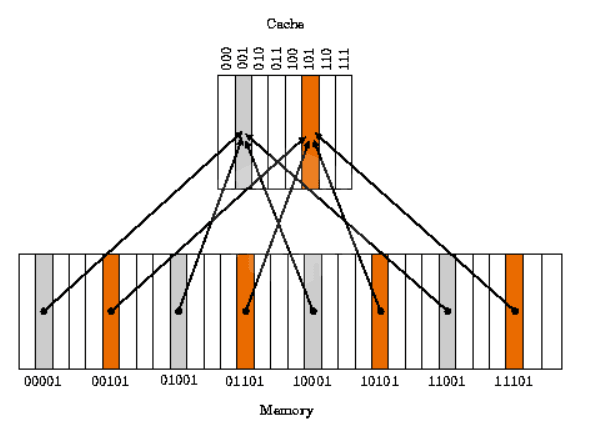
(캐시 직접 매핑 이미지)
캐시의 동작 원리
자 그렇다면 캐시의 동작 원리에 대해서 설명해보자
캐시라인(Cache Line)
캐시 라인은 캐시 메모리에서 데이터를 저장하고 관리하는 최소 단위이다. CPU가 메모리에서 데이터를 가져올 때, 개별 바이트나 워드 단위로 가져오는 대신, 고정된 크기의 데이터 블록(캐시라인)을 한꺼번에 가져온다. 이렇게 함으로써 메모리 접근의 효율성을 높이고, 데이터 지역성(Locality)를 활용해 성능을 최적화한다.
현대 시스템에서는 주로 64바이트(즉, 512비트)로 설정되는데, 과거 시스템에서는 16바이트, 32 바이트등 더 작은 크기도 사용되었지만 최근에는 64 바이트를 표준으로 한다.
캐시 라인은 데이터 뿐만 아니라 메타 데이터(태그,유효 비트, 더티 비트)등을 포함한다.
캐시 라인의 구조
캐시 라인은 캐시 메모리 내에서 하나의 "슬롯" 또는 "엔트리"로 저장되며, 다음과 같은 정보를 포함한다.
데이터(Data)
주 메모리에서 가져온 실제 데이터 블록(예: 64바이트).
CPU가 요청한 데이터뿐만 아니라 주변 데이터도 함께 포함됩니다(공간적 지역성 활용).
태그(Tag)
이 캐시 라인이 참조하는 주 메모리의 주소 정보를 나타냄
태그는 캐시가 해당 데이터가 어느 메모리 위치에서 왔는지 식별하는 데 사용됨
유효 비트(Valid Bit)
이 캐시 라인이 유효한 데이터로 채워져 있는지 여부를 나타냅니다(0: 비어 있음, 1: 유효함).
더티 비트(Dirty Bit)
쓰기 지연(write-back) 캐시에서 사용되며, 캐시 라인 데이터가 수정되었고 주 메모리와 동기화되지 않았음을 표시
기타 메타데이터
캐시 교체 정책(예: LRU, Least Recently Used)을 위한 시간 정보, 캐시 코히어런스 상태(MESI 프로토콜의 Modified, Exclusive, Shared, Invalid 등) 등.
캐시 라인의 동작 원리
캐시 라인은 CPU가 메모리에 접근할 때 어떻게 데이터를 가져오고 관리하는지를 결정한다.
동작 과정을 단계별로 설명하겠다
1. 캐시 히트(Cache Hit)와 미스(Cache Miss)
CPU가 메모리 주소 X의 데이터를 요청하면, 캐시는 해당 주소가 속한 캐시 라인을 확인
히트: 요청한 주소가 캐시 라인에 이미 존재하면, 캐시에서 데이터를 바로 반환한다.(빠른 접근).
미스: 캐시 라인에 없으면, 주 메모리에서 해당 주소와 주변 데이터를 포함한 캐시 라인 전체를 가져온다
2. 데이터 페치(Fetching)
캐시 미스가 발생하면, CPU는 요청한 데이터의 주소가 속한 캐시 라인 크기 단위(예: 64바이트)로 데이터를 페치(Fetch)
예: 주소 0x1000의 데이터를 요청하면, 0x1000~0x103F(64바이트 범위)를 한꺼번에 가져옴
이는 공간적 지역성(spatial locality)을 활용한 것으로, 인접 데이터가 곧 사용될 가능성이 높다고 가정
페치: 주 메모리(RAM)나 다른 캐시 계층에서 데이터를 캐시로 가져오는 동작 일체를 말함.
캐시 페치 또한 상황에 따라 Demand Fetch,Prefetch,Speculative Fetch 등으로 나뉨.
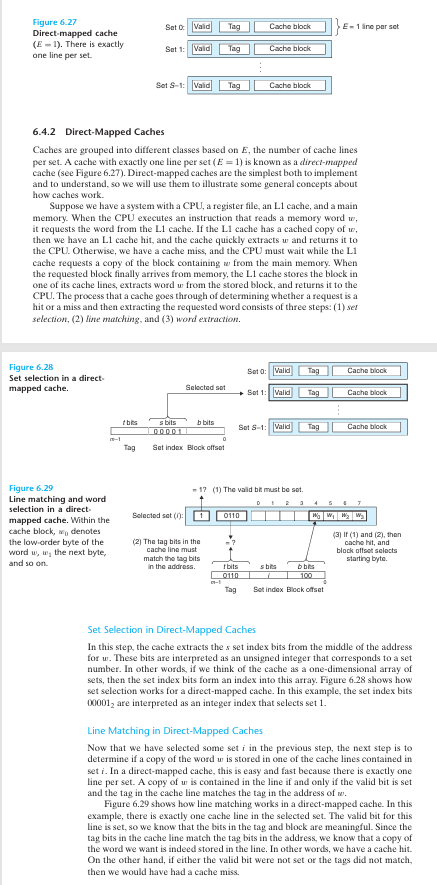
3. 캐시 라인 저장
가져온 캐시 라인은 캐시 메모리의 슬롯에 저장
직접 매핑(Direct-Mapped): 각 메모리 주소가 고정된 캐시 라인 위치에 매핑
집합 연관(Set-Associative): 여러 캐시 라인(집합) 중 하나에 저장되며, 교체 정책(LRU 등)에 따라 결정
완전 연관(Fully Associative): 캐시 내 아무 위치에나 저장 가능(현실적으로 드뭄).
캐시가 꽉 차면 기존 캐시 라인을 교체(replacement)
4. 쓰기 동작
쓰기 적중(Write Hit)
-Write-Through: 캐시와 주 메모리를 동시에 업데이트.
-Write-Back: 캐시만 업데이트하고 더티 비트를 설정, 나중에 메모리에 반영.
쓰기 미스(Write Miss)
-Write-Allocate: 캐시 라인을 가져와 캐시에 쓴 후 업데이트.
-No-Write-Allocate: 캐시 없이 주 메모리에 바로 씀.
5. 캐시 코히어런스
다중 코어 CPU에서는 각 코어의 캐시 라인이 동일한 메모리 주소를 참조할 수 있다.
MESI 프로토콜 등을 통해 캐시 라인 간 데이터 일관성을 유지한다
지역성(Locality)
시간 지역성(Temporal Locality)
-같은 데이터를 반복해서 사용할때, 캐시 히트율이 높아짐
공간 지역성(Spatial Locality)
-인접한 메모리 주소를 순차적으로 접근할 때 효율적
캐시 미스의 3가지 유형
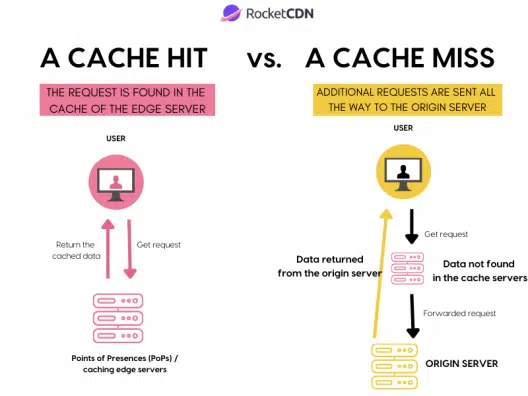
(이미지 출처:https://rocketcdn.me/what-is-a-cache-hit-ratio/)
1.Compulsory Miss (강제 미스)
정의: 데이터를 최초로 접근할 때 발생하는 캐시 미스로, 피할 수 없는 필연적인 미스.
"Cold Miss" 또는 "First Reference Miss"라고도 불림
발생 원인:
캐시가 처음 비어 있을 때, 또는 프로그램이 특정 데이터를 처음 사용할 때 캐시에 해당 데이터가 없기 때문에 발생
캐시 라인이 아직 채워지지 않은 상태에서 데이터 페치가 필요
특징: 프로그램 실행 초기에 주로 발생하며, 데이터가 한 번 페치되어 캐시에 로드되면 이후에는 이 유형의 미스가 줄어듬
예시:
프로그램 시작 시 배열 int array[100]의 array[0]을 처음 읽을 때, 캐시에 데이터가 없으므로 강제 미스가 발생.
이후 array[0] 접근은 캐시 히트로 처리됨.
줄이는 방법:
프리페치(Prefetching): 하드웨어 프리페처나 소프트웨어로 데이터를 미리 페치해 강제 미스를 줄일 수 있다.
완전히 없애는 것은 불가능하지만, 초기 로딩 속도를 개선할 수 있다.
다만 현실적 한계가 엄연히 존재하는 것이, 데이터의 첫 접근은 피할 수 없으므로, 이 미스는 설계상 필연적이다.
2. Conflict Miss (충돌 미스)
정의: 캐시에 공간이 충분함에도 불구하고, 다른 데이터가 같은 캐시 라인을 점유하고 있어 발생하는 캐시 미스. "Mapping Miss"라고도 불림
발생 원인:
캐시가 직접 매핑(direct-mapped)이거나 집합 연관(set-associative) 방식일 때, 여러 메모리 주소가 동일한 캐시 라인에 매핑되어 충돌이 생김
특징: 캐시 크기와는 무관하며, 캐시 매핑 방식과 데이터 접근 패턴에 의존
예시:
캐시가 4개의 라인(각각 64바이트)이고 직접 매핑일 때:
주소 0x1000과 0x2000이 동일한 캐시 라인(예: 라인 0)에 매핑됨.
0x1000을 로드한 후 0x2000을 접근하면 0x1000이 쫓겨나고(Eviction), 다시 0x1000을 접근하면 충돌 미스 발생.
줄이는 방법:
직접 매핑 대신 2-way, 4-way 집합 연관 캐시를 사용해 충돌 가능성을 줄임.
데이터 패딩(Padding): 메모리 레이아웃을 조정해 동일 캐시 라인에 매핑되는 데이터 충돌을 피함.
메모리 정렬: 데이터 구조를 캐시 라인 경계에 맞춰 충돌을 최소화.
현실적 한계로는 완전 연관(fully associative) 캐시로 설계하면 충돌 미스가 없어지지만, 하드웨어 복잡성과 비용 증가로 현실적이지 않다.
-캐시의 연관성(associativity)이 낮으면 데이터가 서로 덮어쓰기(overwrite)되어 미스가 빈번해짐
-캐시 연관성이란? 캐시 연관성은 데이터 매핑의 자유도를 조정하는걸 뜻한다. 즉 위에서 언급한 직접 매핑,집합 연관,완전 연관등이다.
3. Capacity Miss (용량 미스)
정의: 캐시 크기보다 큰 데이터를 처리할 때 발생하는 캐시 미스로, 캐시 용량 부족으로 데이터가 쫓겨나는 경우입니다.
발생 원인:
캐시가 모든 활성 데이터(working set)를 수용할 만큼 크지 않을 때, 자주 사용되는 데이터가 캐시에서 제거(Eviction)되고 다시 페치해야 합니다.
프로그램의 데이터셋 크기가 캐시 용량을 초과하면 발생 빈도가 높아집니다.
특징: 캐시 크기에 직접 의존하며, 연관성이나 매핑 방식과는 관련이 적습니다.
예시:
256KB L2 캐시가 있는 시스템에서 1MB 배열을 반복적으로 순회:
처음 256KB는 캐시에 로드되지만, 배열 끝으로 갈수록 초과 데이터가 이전 캐시 라인을 덮어씀.
다시 처음으로 돌아오면 캐시에서 쫓겨난 데이터로 인해 용량 미스 발생.
줄이는 방법:
캐시 크기 증가: L2, L3 등 더 큰 캐시를 추가해 용량 문제를 완화.
데이터 지역성 개선: 프로그램에서 사용하는 데이터셋(working set)을 줄이거나, 메모리 접근을 더 지역적으로 만듦(예: 블록 단위 처리).
효율적 알고리즘: 불필요한 데이터 접근을 줄여 캐시 용량 부담을 덜어냄.
현실적 한계로는 캐시 크기를 무한히 늘릴 수 없고, 하드웨어 비용과 전력 소모가 문제가 된다.
(플레이 그라운드로 캐시미스 시뮬레이터를 한번 조작해보자)

3C모델
캐시 미스 3가지 분류를 흔히 '3C's Model'로 불린다.
총 캐시 미스율=Compulsory+Conflict+Capacity로 계산하고,
이를 통해서 캐시 미스를 최대한 적게 하는것이 프로그래머의 실력이라고 할 수 있다.
3C 캐시 미스를 줄이는 방법 예시
Compulsory Miss: 첫 접근 필연적 미스 -> 프리페치로 완화.
Conflict Miss: 같은 캐시 라인 충돌 -> 집합 연관성(8-way) + 패딩으로 해결.
Capacity Miss: 캐시 용량 초과 -> 블록화(Blocking)로 데이터셋 분할.
캐시 친화적인 코드 작성하기
int array[1024][1024]; // 4MB (요소당 4바이트)
for (int j = 0; j < 1024; j++)
{ // 열 우선 접근
for (int i = 0; i < 1024; i++)
{
array[i][j] = i + j; // 열 방향 접근 (비연속)
}
}(비 캐시 친화적 코드)
int array[1024][1024];
for (int i = 0; i < 1024; i++)
{ // 행 우선 접근
for (int j = 0; j < 1024; j++)
{
array[i][j] = i + j; // 행 방향 접근 (연속)
}
}(캐시 친화적 코드)
1. 순차접근으로 공간 지역성 활용
->2D 배열에서 C 계열 언어에서는 열(Column)단위로 접근하면 메모리 주소가 비연속적이라 캐시 라인이 자주 교체된다. 예를 들어서 array[0][0] 다음 array[1][0]은 4096(1024*4)바이트 만큼 떨어져 있어 캐시라인(64바이트)에 인접 데이터가 활용되지 않아 용량 미스가 증가한다.
따라서 행 단위로 접근하면 array[i][j]-> array[i][j+1]은 4바이트 차이기때문에 공간 지역성을 활용할 수 있다.
(다만 메모리 저장의 문제이기때문에 행으로 데이터를 저장하는 C계열에서는 행 단위로, Matlab같은 열 단위로 저장하는 언어면 열 단위로 쓰는 것이 맞다)
int array[4096][4096]; // 64MB
for (int i = 0; i < 4096; i++)
{
for (int j = 0; j < 4096; j++)
{
array[i][j] *= 2;
}
}(비 캐시 친화적 코드)
int array[4096][4096];
const int BLOCK_SIZE = 64; // 캐시 라인(64바이트)과 배열 크기에 맞게 정렬
for (int ii = 0; ii < 4096; ii += BLOCK_SIZE)
{
for (int jj = 0; jj < 4096; jj += BLOCK_SIZE)
{
for (int i = ii; i < ii + BLOCK_SIZE && i < 4096; i++)
{
for (int j = jj; j < jj + BLOCK_SIZE && j < 4096; j++)
{
array[i][j] *= 2; // 64×64 블록 단위로 처리
}
}
}
}(캐시 친화적 코드)
2. 블록 단위 처리로 용량 미스 줄이기
큰 데이터셋을 캐시 크기에 맞춰서 용량 미스를 최소화한다.
64MB 배열은 L2(1MB)나 L3(16MB) 캐시를 초과하므로, 배열 끝으로 갈수록 초기에 로드된 데이터가 쫓겨나고 다시 페치되는데, 이는 용량미스가 증가한다
데이터를 64x64 블록(16kb)으로 나누어 처리하면, 각 블록이 캐시에 유지될 가능성이 높아진다.
struct Data
{
int a; // 4바이트
int b; // 4바이트
} data[1024];
for (int i = 0; i < 1024; i++)
{
data[i].a = i; // 같은 캐시 라인에 매핑될 가능성 있음
data[(i + 256) % 1024].b = i; // 충돌 발생 확률 높음
}(비 캐시 친화적인 구조체)
struct Data
{
int a; // 4바이트
int b; // 4바이트
char padding[56]; // 64바이트 캐시 라인에 맞게 패딩 추가
} data[1024];
for (int i = 0; i < 1024; i++)
{
data[i].a = i;
data[i].b = i; // 연속 접근으로 충돌 최소화
}(캐시 친화적 구조체 - 다만 단일 스레드에서는 사용하지 말 것!)
3. 데이터 패딩으로 충돌 미스 줄이기
처음 코드를 보면 data[i]와 data[i+256] 이 동일 캐시 라인에 매핑될 수 있는데, 구조체 크기를 64바이트로 패딩해서, 각 요소가 고유한 캐시 라인에 매핑되도록 한다.
이럼으로써 접근 패턴을 순차적으로 변경하고, 시간과 공간 지역성을 강화한다.
-데이터 패딩(Data Padding) 메모리 정렬과 캐시 성능 최적화를 위해 여분의 빈공간(Padding)을 삽입하는 기법, False Sharing을 줄여준다.
3-1. 왜 충돌이 발생하는가 - 수치로 확인
환경: 직접 매핑(direct-mapped), 2KB 캐시, 캐시라인 64B
→ 세트(set) 수 = 2048 / 64 = 32개세트 인덱스 계산식:
set_index(addr) = (addr / 64) % 32sizeof(Data) = 8이므로 data[i]의 주소 오프셋은 i × 8이다.
data[i] → set = (i × 8 / 64) % 32 = (i / 8) % 32
data[i + 256] → set = ((i + 256) × 8 / 64) % 32
= (i/8 + 256×8/64) % 32
= (i/8 + 32) % 32
= (i/8) % 32 ← data[i]와 동일한 세트32 % 32 = 0이므로 두 주소는 항상 같은 세트에 매핑된다.
// i = 0일 때
data[0].a → set 0 (data[0]..data[7] 로드)
data[256].b → set 0 ← 같은 세트, 직접 매핑이면 data[0]를 즉시 퇴출
// i = 1일 때
data[0].a 재접근 → CONFLICT MISS ← 방금 쫓겨났기 때문단, 실제 L1(32KB, 512 sets)에서는 (i/8 + 32) % 512 ≠ (i/8) % 512라 직접 충돌은 나지 않는다. 이 예제는 캐시가 작은 임베디드 환경에서 이 패턴이 왜 위험한지 원리를 보여주는 용도다.
반면 패딩 버전은 sizeof(Data) = 64로 늘어나므로 data[i]와 data[i+256]의 거리가 256 × 64 = 16384바이트다. 32-set 캐시에서 (16384/64) % 32 = 256 % 32 = 0이라 여전히 같은 세트에 매핑된다. 즉 패딩의 실제 효과는 세트 충돌 회피가 아니라, 각 요소를 독립된 캐시 라인에 격리해 false sharing을 제거하는 것이다 - 이 부분은 바로 아래 3-2에서 자세히 다룬다.
3-2. 패딩 예제의 적용 범위- 단일 스레드 vs 멀티 스레드
위 패딩 코드는 맥락에 따라 평가가 정반대로 갈린다.
단일 스레드 순차 접근에서는 오히려 역효과이다.
패딩 없는 원본 구조체(sizeof(Data) = 8)라면, 캐시 라인 하나(64B)에 요소 8개가 들어간다.
1번의 compulsory miss -> 이후 7번 연속 cache hit 캐시 라인 활용률: 8/8 = 100%56바이트 패딩을 추가하면(sizeof(Data) = 64), 캐시 라인 하나에 요소 1개만 들어간다.
매 루프마다 compulsory miss 반복
캐시 라인 활용률: 8/64 = 12.5%
-> 대역폭의 87.5%를 패딩(쓰레기 값) 페치에 낭비공간 지역성을 스스로 파괴하는 코드가 된다. 단일 스레드 순차 접근 기준으로는 패딩 없는 코드가 정답이다. 따라서 캐시 친화적 코드를 작성할때 단일 스레드냐도 중요하다.
패딩이 정답이 되는 조건 - False Sharing 방지
이 기법이 효과를 발휘하는 환경은 오직 멀티 스레드이다. 여러 코어가 인접한 배열 요소에 동시에 쓰기 작업을 할 때 문제가 생긴다.
core 0: data[0].a = 1; // 캐시 라인 A 점유
core 1: data[0].b = 2; // 같은 캐시 라인 A → core 0의 라인 무효화(Invalidate)MESI 프로토콜 상 두 코어가 같은 캐시 라인을 공유하면서 한쪽이 쓰기를 하면, 다른 쪽 코어의 캐시 라인이 Invalid 상태로 전환되어 강제 재페치가 발생합니다. 실제로는 a와 b가 서로 다른 변수인데, 같은 캐시 라인에 있다는 이유만으로 성능이 떨어지는 것을 거짓 공유(False Sharing)라고 한다.
이때 각 요소를 별도 캐시 라인에 격리하는 패딩이 해결책이 된다.
// 멀티 스레드 환경에서 올바른 패딩 사용
struct Data {
int a;
int b;
char padding[56]; // core 간 false sharing 차단
} data[1024];
// thread 0: data[0] 전용 캐시 라인
// thread 1: data[1] 전용 캐시 라인 → 서로 무효화 없음정리
환경 | 패딩 없음 | 패딩 있음 |
|---|---|---|
단일 스레드 순차 접근 | 공간 지역성 최대 활용 | 대역폭 낭비, 역효과 |
멀티 스레드 동시 쓰기 | False Sharing 발생 | 캐시 라인 격리, 정답 |
- 환경
단일 스레드 순차 접근
- 패딩 없음
공간 지역성 최대 활용
- 패딩 있음
대역폭 낭비, 역효과
- 환경
멀티 스레드 동시 쓰기
- 패딩 없음
False Sharing 발생
- 패딩 있음
캐시 라인 격리, 정답
외에도 캐시 블로킹, 타일링등의 예제가 있지만, 글이 너무 길어질 경우 가독성이 너무 낮아질 걸 고려해 이후에 작성하기로 하겠다.
캐시 친화적 코드 작성 팁
순차 접근: 배열을 행 단위로 처리해 캐시 라인을 최대한 활용.
데이터 크기 조정: 작업 데이터셋을 캐시 크기(L1: 32KB, L2: 256KB 등)에 맞춤.
패딩: 멀티 스레드 환경에서 캐시 라인(64바이트) 경계에 맞춰서 False Sharing을 방지. 단일 스레드 순차 접근에서는 역효과.
프리페치: 강제 미스를 줄이기 위해 명시적/암시적 프리페치 사용.
루프 최적화: 중첩 루프에서 내부 루프가 연속 메모리를 접근하도록 설계.
외에도 알고리즘 선택에도 주의를 기울여야 하는 것이
퀵소트와 머지소트의 경우, 평균 시간복잡도는 동일하지만
퀵소트는 캐시 친화적인 접근 패턴을 가지고, 머지 소트는 추가 메모리 공간 필요로 인해 캐시 효율성이 낮을 수 있다.
왜냐하면 퀵소트의 경우 제자리 정렬을 할때, 추가 메모리 접근 없이 연속으로 메모리 접근하고, 머지 소트의 경우 추가 버퍼를 필요로해, 버퍼와 원본 배열을 오가기때문에 캐시 라인 재사용률이 저하되기때문이다.

범용 케이스는 빠르게 만들어라(Make the common case fast)- David Patterson
마치며...
앞서 봤듯이 캐시는 단순히 '빠른 메모리'가 아니다.
데이터의 흐름을 제어하는 예측 시스템이며, 하드웨어와 소프트웨어를 소통하게 해주는 도구라고 할 수 있다.
그렇기에 우리는 프로그래머서 하드웨어와 소프트웨어를 적절하게 이을 의무가 있는 것이다.
우리는 단순히 코드를 작성하는 것이 아닌, 하드웨어에게 우리의 상상을 이야기하는 사람이니까.
참고 문헌:Randal E. Bryant, David R. O'HallaronComputer Systems: A Programmer's Perspective, 3rd Global Edition,Pearson, 2016.