
메모리 관리 방식: 수동 관리와 가비지 컬렉션
흔히 프로그래밍 언어에서 메모리 관리 방식은 2가지로 나뉜다
Manual 과 GC이다.
수동 메모리 관리(Manual Memory Management) 와 자동 메모리 관리(Garbage Collection,GC)이다.
수동 메모리 관리란?
개발자가 직접 메모리 할당과 해제를 관리하는 방식이다.
대표적인 언어로 C,C++ malloc/free,new/delete 등등 개발자가 직접 메모리를 할당 해제한다.
장점으로는 정밀한 제어를 통한 메모리 할당 해제 시점을 프로그래머가 완전히 통제 가능하며 예측 가능한 성능이기때문에 GC의 불필요한 오버헤드가 존재하지 않는다.
또한 필요 없는 메모리를 즉시 해제해 리소스를 절약할 수 있다.
다만, 단점은 메모리 누수(Memory Leak)가 존재하고, 댕글링 포인터(Dangling Pointer)가 존재하며 개발이 복잡해진다는 것이다.
*메모리 누수: 할당된 메모리를 해제 않아서 프로그램이 종료될때까지 누적되는 현상, 시스템 메모리 고갈로 크래시를 발생시킬 수 있다.
**댕글링 포인터:이미 해제된 메모리를 참조할 경우 예측 불가능한 동작이 발생함
최근에는 Rust는 수동 메모리의 관리의 대안으로 소유권 시스템(OwnerShip System)을 통해 메모리를 안전하게 관리하는데, 이는 완전한 수동 메모리 관리라기보다는 수동 메모리 관리의 새로운 대안이라고 여겨진다.
가비지 컬렉션의 기원 (1960)

자유 저장소 목록 (Free-Storage List)
어느 시점에서든지, 리스트 구조를 저장하기 위해 예약된 메모리의 일부만이 실제로 S-표현식(S-expressions)을 저장하는 데 사용됩니다.
나머지 레지스터들(우리 시스템에서는 초기에 약 15,000개 정도)은 자유 저장소 목록(free-storage list)이라는 단일 목록으로 구성됩니다.
프로그램 내의 특정 레지스터인 FREE는 이 목록의 첫 번째 레지스터 위치를 포함합니다.
추가적인 리스트 구조를 구성하기 위해 단어(word)가 필요할 때, 자유 저장소 목록의 첫 번째 단어가 사용되고, 레지스터 FREE의 값은 자유 저장소 목록의 두 번째 단어 위치로 변경됩니다.
사용자가 레지스터를 자유 저장소 목록으로 반환하는 것을 프로그래밍할 필요는 없습니다.
-Recursive Functions of Symbolic Expressions Their Computation by Machine, Part I John McCarthy
GC의 출발점은 John McCarthy의 논문 Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I (1960) 이다. 이 논문에서 McCarthy는 자유 저장소 목록(Free-Storage List) 개념을 소개하는데, 이것이 GC의 핵심 아이디어가 된다.
왜 이 개념이 필요 했을까?

(존 매카시)
LISP(LISt Processor)는 기호 처리(Symbolic Processing)와 재귀 호출(Recursion)을 지원하는 고수준 언어였다. 실행 중 끊임없이 객체를 생성하는 구조였기 때문에, 더 이상 사용되지 않는 객체(Garbage)가 메모리에 축적되는 문제가 심각했다.
또한 당시 컴퓨터 기술로는 LISP의 메모리 관리가 매우 복잡하고 어려운 문제였다.
프로그래머가 모든 메모리 할당·해제를 완벽히 추적하는 것은 현실적으로 불가능했고, 이것이 자동 메모리 관리 기술을 탄생시킨 배경이다.
자유 저장소 목록(Free-Storage List)은 초기 LISP 시스템에서 자동 메모리 관리를 구현하는 기초적인 개념이었다.
당시 LISP는 동적으로 리스트 구조를 생성하는 방식이었고, 프로그래머가 명시적으로 메모리를 해제하는 것이 어려웠다.
이를 해결하기 위해, 사용되지 않는 메모리 블록을 추적하는 Free-Storage List 개념이 자동 메모리 관리 개념으로 발전했다.
특정 레지스터(FREE)에 가용 메모리 리스트의 시작 위치를 저장하고, 필요할 때 가져오고, 더 이상 사용되지 않는 경우 다시 반환하는 방식인데, 이 아이디어는 이후 Mark-and-Sweep 방식의 GC의 기반이 되었다.
(GC의 구현방식 및 아이디어 상세설명은 다음섹션에서 이야기하겠다)

컴퓨터에 리스트를 저장하기 위한 뉴얼-쇼-사이먼(Newell-Shaw-Simon) 방식의 중요한 특징은
동일 데이터가 여러 번 발생하더라도 컴퓨터 내 한 곳에만 저장될 수 있다는 점입니다. 즉, 리스트들이 "중첩(overlapped)"될 수 있습니다.
그러나 이러한 중첩은 이후 삭제(erasure) 과정에서 문제를 일으킵니다. 더 이상 필요 없는 리스트가 주어졌을 때,
다른 리스트와 중첩되지 않은 부분만을 선택적으로 삭제해야 합니다. LISP에서는 매카시(McCarthy)가 이 문제에 대해 우아하지만 비효율적인 해결책을 제시했습니다.
본 논문은 효율적인 삭제를 가능하게 하는 일반적인 방법을 설명합니다. -
"A Method for Overlapping and Erasure of Lists" (1963) George E. Collins
존 맥카시의 논문이 mark-and-Sweep 방식의 기반이 되었지만, GC실행시 프로그램이 멈추는 Stop - the - World 현상이 발생하는 단점이 있었다.
이를 해결하기 위해 Collins는 참조 카운팅(Reference Counting) 을 제안했다. 각 객체에 참조 횟수를 저장하여 참조 수가 0이 되는 순간 즉시 메모리를 회수하는 방식이다. 다만 순환 참조(Circular Reference) 문제를 해결하지 못한다는 한계가 있었고, Python, Swift 등 현대 언어에서는 보완 기법을 추가해 사용하고 있다.
(여담이지만 '우아하지만 비효율적'이다라니 엣날부터 생각하지만 전반적으로 프로그래머의 직업적 특징인지 모르겠으나 프로그래머들은 주로 상대방을 '우아하게' 비꼬는 재주가 있다. 아무래도 실체가 없는 추상적 개념에 대한 이야기를 하니까 실체적 폭력에 대한 존재가 옅어져서 그런게 아닐까 싶기도하다. 한국에서는 이러면 보통 물리적 실체인 주먹으로 응징을 당했을 표현이다.)
가상 메모리 환경의 GC — Fenichel & Yochelson (1969)


본 논문에서는 매우 큰 가상 메모리 환경에서 동작하는 리스트 처리 시스템을 위한 가비지 컬렉션 알고리즘을 제안합니다.
이 알고리즘의 주요 목적은 "여유 메모리 확보"보다는 활성 메모리의 압축(compaction)에 있습니다.
가상 메모리 시스템에서는 여유 메모리가 실제로 고갈되지 않기 때문에, 가비지 컬렉션 실행 시점을 결정하기가 쉽지 않습니다.
따라서 본 논문에서는 가비지 컬렉션 트리거 조건에 대한 다양한 기준을 논의합니다. -"A LISP Garbage Collector for Virtual-Memory Computer Systems" (Fenichel & Yochelson, 1969)
(가상메모리(Virtual Memory):물리적 메모리 크기를 넘어서는 대용량 메모리를 논리적으로 관리하는 기술)
이 논문은 Minsky의 복사방식 GC(Copying GC)를 개선하여, 가상 메모리(Virtual Memory)에서 효율적으로 동작하는 방법을 기술한 논문이다.
본 논문은 Misnky의 가비지 컬렉터, 깊이 우선 탐색 (DFS, depth-first-serach)을 이용해 도달가능한 데이터를 보조 저장소에 복사하고, 이를 새로운 연속된 주소에 할당한 후 다시 메모리로 로드 하는 방식을 실제적으로 구현한 논문인데, 완성도에 대한 비판도 있었지만,
이 논문은 Minsky의 방법을 기반으로 "Copying GC"를 현대적인 가상메모리 환경에 적용한 첫 논문이라는 기념비적이자, 이 논문이 없었다면 자바와 C#의 Generational GC 개념이 등장하지 못했을 것이다.
비재귀 GC — Cheney (1970)

"간단한 비재귀적(nonrecursive) 리스트 구조 압축 기법 또는 가비지 컬렉터가 제시됩니다. 이 알고리즘은 컴팩트(compact)한 구조와 LISP 스타일의 리스트 구조 모두에 적용 가능합니다. 재귀(recursion)를 사용하지 않고, 복사된 리스트를 추적하기 위해 부분 구조(partial structure)를 점진적으로 활용함으로써 재귀 의존성을 제거했습니다."- (C. J. Cheney, 1970)
Cheney는 DFS 대신 너비 우선 탐색(BFS) 을 사용한 비재귀 GC를 제안했다. 별도의 스택 없이 GC를 수행할 수 있도록 설계된 이 방식은 스택 오버플로우 문제를 원천 차단하고, 캐시 친화적 구조를 가진다는 장점이 있다.
이 연구는 후에, 오늘날 Java,C#,Python의 Copying GC 방식에 큰 영향을 주었다.
BFS가 DFS와 달리 비재귀적으로 구현된 이유
핵심은 두 탐색 방식이 사용하는 자료구조의 차이에 있다.
DFS는 한 방향으로 끝까지 파고든 뒤 되돌아오는 백트래킹(Backtracking) 방식이다. 동굴을 탐험할 때 한 갈래 길을 끝까지 따라간 뒤, 막히면 왔던 길을 되짚어 돌아오는 것과 같다. 되돌아가려면 지나온 경로를 반드시 기억해야 하고, 이를 위해 스택(Stack) 또는 재귀 호출이 필요하다. 스택은 LIFO(Last In, First Out) 구조이므로, 가장 최근에 방문한 노드부터 역순으로 꺼내 백트래킹을 구현할 수 있다.
BFS는 방식이 다르다. 동굴 입구에 팀을 나누어 배치하고, 현재 층의 모든 갈림길을 먼저 훑은 뒤 다음 층으로 내려가는 방식이다. 먼저 발견된 갈림길부터 순서대로 탐색해야 하므로, 먼저 들어온 것이 먼저 나오는 큐(Queue) 가 자연스럽게 들어맞는다. 큐는 FIFO(First In, First Out) 구조이며, 재귀 호출 없이 반복문만으로 동작을 완결할 수 있다.
자, 그럼 독자를 위해서 조금 더 쉽게 요약하면 다음과 같다.
DFS의 스택 기반 동작 원리
현재 노드를 스택(또는 재귀 호출)에 저장한다.
방문할 다음 노드가 있으면 스택(또는 재귀 호출)을 통해 계속 진행한다.
더 이상 진행할 곳이 없으면 백트래킹을 실행한다.
BFS의 큐 기반 동작 원리
탐색을 시작할 노드를 큐에 추가(Enqueue)한다.
큐에서 하나씩 꺼내(Dequeue) 방문 처리한 후, 인접 노드들을 다시 큐에 추가한다.
모든 노드를 탐색할 때까지 반복한다.
큐를 사용하기 때문에 별도의 재귀 호출이 필요 없다.
동굴 탐험으로 비유하면 다음과 같다.
DFS: 한 길을 따라 끝까지 들어간 후, 길이 막히면 되돌아가 새로운 길을 탐색한다. 되돌아갈 경로를 반드시 기억(저장)해야 한다.
BFS: 입구에 팀을 배치하여 모든 갈림길을 동시에 탐색하고, 현재 층의 모든 길을 확인한 뒤 다음 층으로 내려간다. 먼저 도착한 갈림길부터 인원을 우선 배치한다.
GC 발전 연표 요약
연도 | 연구자 | GC 알고리즘 | 개선된 점 | 문제점 |
|---|---|---|---|---|
1960 | John McCarthy | Mark-and-Sweep | 최초의 GC 개념 도입 | Stop-the-World, 단편화 문제 |
1963 | Marvin L. Minsky | Copying GC (DFS 기반) | 메모리 단편화 해결, 캐시 최적화 | 순환 참조 문제, 디스크 사용 |
1969 | Fenichel & Yochelson | Copying GC (Virtual Memory 적용) | 두 개의 반공간(Semispaces) 사용 | 메모리 부족 시 성능 저하 |
1970 | C. J. Cheney | Nonrecursive Copying GC (BFS 기반) | 스택 없이 GC 수행 가능 | BFS 기반으로 메모리 재배치 최적화가 미흡 |
이 흐름의 핵심은 Stop-the-World 문제를 점진적으로 줄이며 실시간(Concurrent) GC 로 발전하는 과정이다.
GC 알고리즘 개요
본격적인 설명에 앞서 기본 개념을 짚고 넘어간다.
메모리는 일반적으로 스택 메모리(Stack Memory) 와 힙 메모리(Heap Memory) 두 가지 풀로 나뉜다.
스택 메모리는 수명이 짧고 크기가 작은 데이터를 저장하는 데 주로 사용된다(주로 값 형식).
힙 메모리는 수명이 길고 크기가 큰 데이터를 저장하는 데 주로 사용된다(주로 참조 형식).
GC 알고리즘은 크게 두 계열로 나뉜다.
1. Tracing GC (추적 기반 GC)
가장 널리 사용되는 방식이다.
특정 객체가 가비지인지 판단하는 기준은 도달성(Reachability) 이다. Root(전역 변수, 스택 변수 등)에서 시작하여 도달 가능한(Reachable) 객체를 찾고, 도달하지 못한 객체를 해제한다. 유효한 참조가 없는 객체는 Unreachable로 분류되어 수거된다.
대표적인 알고리즘은 세 가지이며, 아래에서 순서대로 다룬다.
이하 첨부 코드는 핵심 개념을 설명하기 위한 의사 코드(Pseudo Code)이며, 실제 동작을 보장하지 않는다.
1-1. Mark-and-Sweep(마크 스윕)
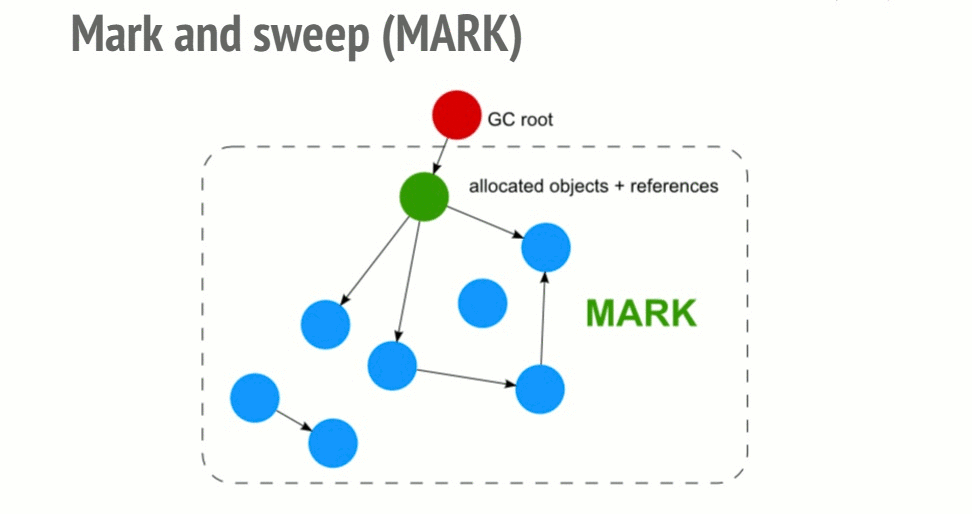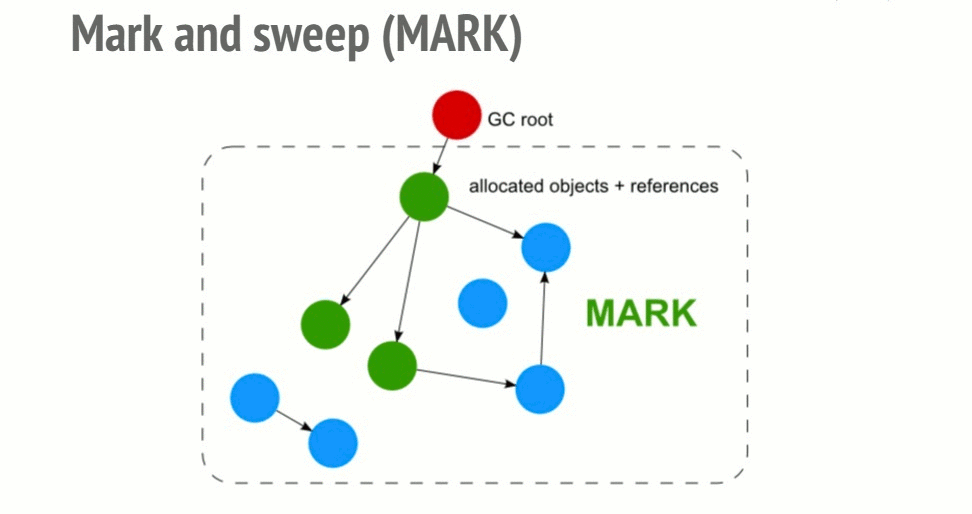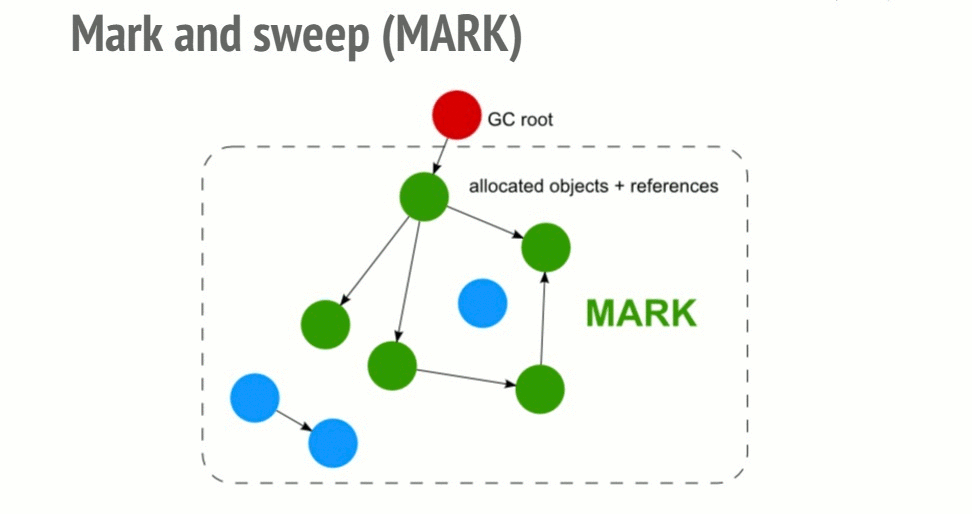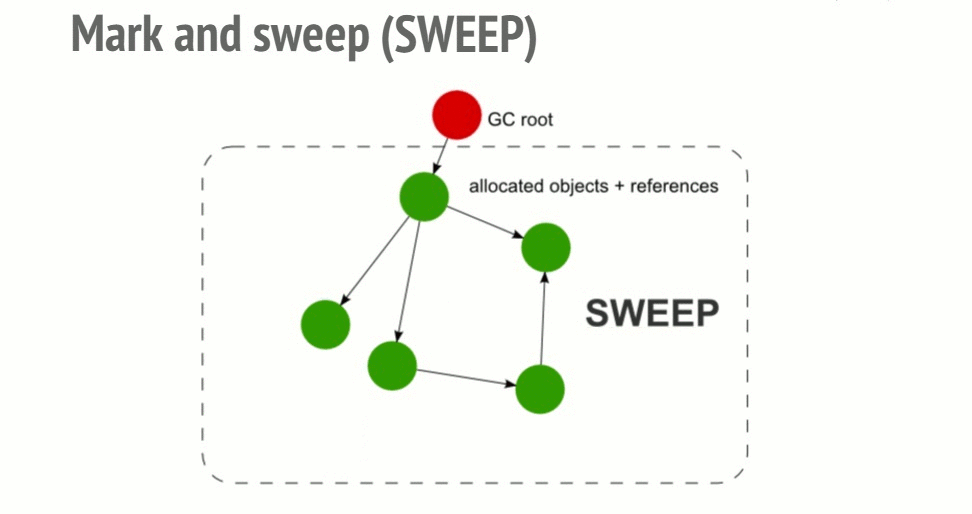
(이미지 출처:https://deepu.tech/memory-management-in-programming/)
코드내에서 C++의 RAII을 따라 shared_ptr을 사용할 경우 실제로 GC 동작 관측이 어렵기때문에 원시 포인터를 사용해야한다
#include <iostream>
#include <vector>
#include <algorithm>
// Mark-and-Sweep GC 구현 (원시 포인터 사용)
class Object {
public:
bool marked; // GC 표시 상태
std::vector<Object*> children; // 자식 객체 목록
Object() : marked(false) {}
void addChild(Object* child) {
children.push_back(child);
}
// 소멸자: 객체 삭제 시 로그 출력 (디버깅용)
~Object() {
std::cout << "Deleting Object at " << this << std::endl;
}
};
// 전역 힙 및 루트 객체 컨테이너
std::vector<Object*> heap;
std::vector<Object*> roots;
// 객체와 자식 객체를 재귀적으로 표시
void mark(Object* obj) {
if (obj == nullptr || obj->marked) {
return;
}
obj->marked = true;
for (Object* child : obj->children) {
mark(child);
}
}
// Sweep 단계: 표시되지 않은 객체를 삭제하고 힙에서 제거
void sweep() {
auto it = heap.begin();
while (it != heap.end()) {
Object* obj = *it;
if (!obj->marked) {
// 도달 불가능한 객체 해제
delete obj;
it = heap.erase(it);
} else {
// 다음 GC 실행을 위해 표시 초기화
obj->marked = false;
++it;
}
}
// 루트 목록 갱신: 힙에 남아 있는 객체만 유지
std::vector<Object*> newRoots;
for (Object* root : roots) {
if (std::find(heap.begin(), heap.end(), root) != heap.end()) {
newRoots.push_back(root);
}
}
roots = newRoots;
}
// GC 실행: Mark 후 Sweep
void gc() {
for (Object* root : roots) {
mark(root);
}
sweep();
}
int main() {
// 객체 생성 및 힙 등록
Object* a = new Object();
Object* b = new Object();
Object* c = new Object();
// 객체 간 참조 관계 설정
a->addChild(b);
b->addChild(c);
heap.push_back(a);
heap.push_back(b);
heap.push_back(c);
// 루트 객체 설정 (a를 루트로 지정)
roots.push_back(a);
std::cout << "Heap size before GC: " << heap.size() << std::endl;
gc();
std::cout << "Heap size after GC: " << heap.size() << std::endl;
// 남은 객체 해제 (실제 시스템에서는 최종 GC가 처리)
for (Object* obj : heap) {
delete obj;
}
heap.clear();
roots.clear();
return 0;
}1960년 McCarthy가 제안한 이래 가장 널리 사용되는 Tracing GC의 기본형이다.
동작은 두 단계로 이루어진다.
1. Mark 단계
루트(전역 변수, 스택 변수 등)에서 시작하여 참조를 따라가며 도달 가능한(Reachable) 객체를 순차적으로 표시한다. 이 과정은 객체 그래프를 재귀적으로 순회하며 진행되고, 한 번도 방문되지 않은 객체는 표시 없이 남는다.
2. Sweep 단계
힙 전체를 순회하며 Mark 단계에서 표시되지 않은 객체, 즉 어떤 루트에서도 도달할 수 없는 객체를 가비지로 판단하고 메모리를 해제한다. 표시된 객체는 다음 GC 사이클을 위해 표시를 초기화한 뒤 유지한다.
구현이 비교적 단순하고, 실제로 참조되는 객체만 보존하기 때문에 메모리를 낭비 없이 관리할 수 있다.
단점은 두 가지다.
첫째, Stop-the-World 문제다. Mark 단계에서 힙 전체를 정확하게 순회하려면 객체 참조 관계가 변하지 않아야 한다. 따라서 GC가 실행되는 동안 애플리케이션 스레드를 완전히 중단시켜야 하며, 힙이 클수록 중단 시간이 길어진다.
둘째, 메모리 단편화(Memory Fragmentation) 다. Sweep 단계에서 객체를 제거한 뒤 남은 빈 공간이 힙 곳곳에 흩어지게 된다. 이 빈 공간들의 총합은 충분하더라도 연속된 큰 블록이 존재하지 않으면 새로운 객체를 할당하지 못하는 상황이 발생한다.
메모리 단편화는 발생 위치에 따라 두 종류로 나뉜다.
*내부 단편화: 할당된 블록 내부의 사용되지 않는 공간이다. 4KB 블록을 할당받았지만 실제로 1KB만 사용하는 경우가 대표적이다. 블록 크기를 고정하는 할당 방식에서 자주 발생한다.
*외부 단편화: 가용 메모리가 작은 조각으로 분산되어, 전체 여유 공간은 충분함에도 연속된 블록을 확보하지 못하는 현상이다. 객체가 반복적으로 생성·해제될수록 심화된다.
1-2. Mark-Compact(마크 컴팩트)
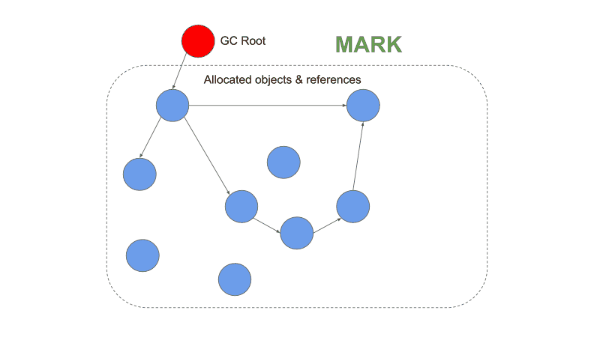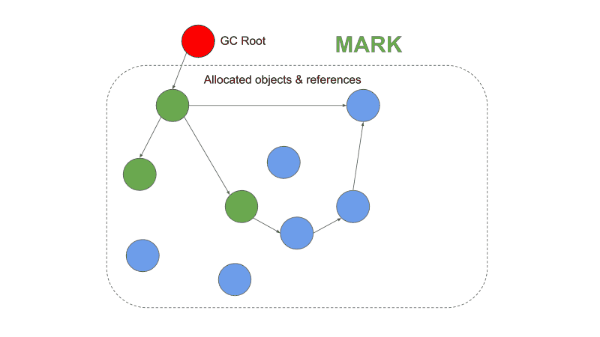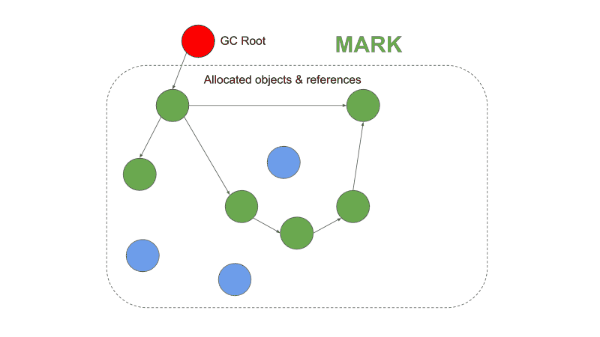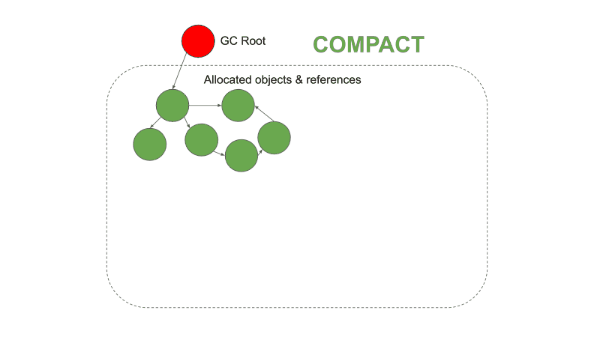
Mark-and-Sweep의 단편화 문제를 해결하기 위해 등장한 방식이다. Mark 단계까지는 동일하게 동작하지만, Sweep 대신 Compaction(압축) 단계를 수행한다는 점이 다르다.
동작은 세 단계로 이루어진다.
1. Mark 단계
Mark-and-Sweep과 동일하게 루트에서 시작하여 도달 가능한 객체를 표시한다.
2. Compact 단계
살아남은 객체들을 힙의 한쪽 끝으로 순서대로 밀어 넣는다. 객체를 새로운 주소로 이동시킨 뒤, 기존에 그 객체를 가리키던 모든 참조 포인터를 갱신한다.
3. 결과
객체들이 연속된 메모리 공간에 밀집되고, 나머지 영역은 완전히 비워진다. 이후 새 객체는 빈 영역의 시작 주소부터 순서대로 할당할 수 있어, 단편화가 구조적으로 발생하지 않는다.
단점은 Compaction 과정 자체의 비용이다. 객체를 물리적으로 이동해야 하므로 복사 연산이 발생하고, 이동된 모든 객체의 참조 포인터를 일일이 갱신해야 한다. 힙에 살아있는 객체가 많을수록 이동 대상이 늘어나 GC 중단 시간이 Mark-and-Sweep보다 길어진다.
1-3. Copying GC(복사 기반 GC)
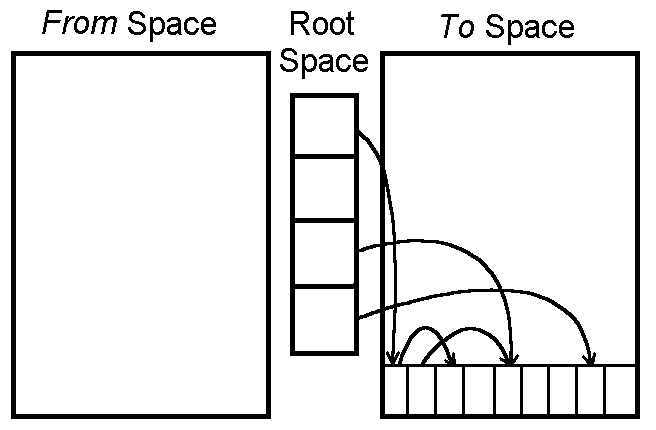
힙을 동일한 크기의 두 영역으로 나누어 관리하는 방식이다. 두 영역은 각각 From Space 와 To Space 로 불린다. 평소에는 From Space만 사용하여 객체를 할당하고, GC가 실행되면 From Space에서 도달 가능한 객체만 To Space로 복사한다. 복사가 완료되면 두 공간의 역할을 교체(Swap)하고, 기존 From Space 전체를 한 번에 비운다.
Mark-and-Sweep이 힙 전체를 순회하며 가비지를 찾아 제거하는 것과 달리, Copying GC는 살아있는 객체만 추려서 옮기는 방식이다. 가비지를 직접 처리하지 않고 살아있는 것만 복사하면 나머지는 자동으로 사라진다.
객체를 To Space에 순서대로 밀착 배치하기 때문에, 복사 후에는 단편화 없이 연속된 빈 공간이 확보된다. 새 객체 할당 시 포인터를 단순히 전진시키는 것만으로 충분하므로 할당 속도도 빠르다.
단점은 전체 힙의 절반만 실제로 사용할 수 있다는 점이다. 나머지 절반은 항상 To Space로 비워두어야 하므로 메모리 사용 효율이 구조적으로 50%로 제한된다.
아래 코드는 placement new를 사용해 두 반공간(Semispace)을 직접 관리한다. shared_ptr 사용 시 복사 동작 관측이 어렵기 때문에 원시 포인터로 구현했다.
#include <iostream>
#include <vector>
#include <algorithm>
#include <cstring>
constexpr std::size_t HEAP_SIZE = 1024;
// 객체 클래스 (단순 연결 리스트 구조)
class Object {
public:
int value;
Object* next;
explicit Object(int val) : value(val), next(nullptr) {}
// 소멸자 (디버깅용)
~Object() {
std::cout << "Deleting Object with value "
<< value << " at " << this << std::endl;
}
};
// 두 반공간(Semispace)으로 메모리 관리
std::vector<char> fromSpace(HEAP_SIZE);
std::vector<char> toSpace(HEAP_SIZE);
std::size_t fromIndex = 0;
std::size_t toIndex = 0;
// 지정된 공간에 객체 할당 (placement new 사용)
Object* allocate(int val, std::vector<char>& space, std::size_t& idx) {
if (idx + sizeof(Object) > space.size()) {
return nullptr; // 공간 부족
}
Object* obj = new (&space[idx]) Object(val);
idx += sizeof(Object);
return obj;
}
// 객체와 연결된 객체를 재귀적으로 복사
Object* copy(Object* obj, std::vector<char>& targetSpace, std::size_t& targetIdx) {
if (obj == nullptr) {
return nullptr;
}
Object* newObj = allocate(obj->value, targetSpace, targetIdx);
if (newObj == nullptr) {
return nullptr;
}
newObj->next = copy(obj->next, targetSpace, targetIdx);
return newObj;
}
// Copying GC 실행: 도달 가능한 객체를 새 공간으로 복사
void gc(Object*& root) {
toIndex = 0;
Object* newRoot = copy(root, toSpace, toIndex);
// 공간 교체: 복사된 공간을 새 힙으로 사용
std::swap(fromSpace, toSpace);
fromIndex = toIndex;
root = newRoot;
}
int main() {
// fromSpace에 객체 할당
Object* a = allocate(10, fromSpace, fromIndex);
if (a == nullptr) {
std::cerr << "Allocation failed for object a." << std::endl;
return 1;
}
Object* b = allocate(20, fromSpace, fromIndex);
if (b == nullptr) {
std::cerr << "Allocation failed for object b." << std::endl;
return 1;
}
a->next = b;
std::cout << "Before GC, root object value: " << a->value << std::endl;
gc(a);
std::cout << "After GC, copied root object value: " << a->value << std::endl;
return 0;
}2. Reference Counting GC (참조 카운팅 GC)
앞서 살펴본 Tracing GC 계열이 "도달 가능한 객체를 찾아내는" 방식이라면, Reference Counting은 반대로 각 객체가 현재 몇 곳에서 참조되고 있는지를 실시간으로 추적하는 방식이다. 객체를 참조할 때마다 카운트를 증가시키고, 참조가 끊길 때마다 감소시킨다. 카운트가 0이 되는 순간 해당 객체는 더 이상 사용되지 않는다고 판단하여 즉시 메모리를 해제한다.
각 객체에 참조 횟수(Reference Count)를 저장하여, 카운트가 0이 되는 순간 즉시 메모리를 해제한다. 객체를 즉시 회수할 수 있어 Stop-the-World가 발생하지 않으며, 어떤 객체가 얼마나 참조되고 있는지 명시적으로 파악할 수 있다는 장점이 있다.
단점은 두 가지다. 두 객체가 서로를 참조하는 순환 참조(Circular Reference) 상황에서는 카운트가 영원히 0이 되지 않아 메모리가 회수되지 않는다. 또한 객체 수가 많아질수록 카운트 갱신 연산이 누적되어 성능이 저하된다.
Swift는 이를 개선한 ARC(Automatic Reference Counting) 를 사용한다.
아래 코드는 전역 참조 테이블 unordered_map을 사용하여 객체 생성 시 참조 카운트를 1로 초기화하고, addRef와 releaseRef를 통해 카운트를 조절하며, 카운트가 0이 되면 delete를 호출하는 방식으로 구현했다.
#include <iostream>
#include <unordered_map>
// 간단한 값을 보관하는 객체 클래스
class Object {
public:
int value;
explicit Object(int val) : value(val) {}
// 소멸자: 객체가 해제될 때 호출됨
~Object() {
std::cout << "Deleting Object with value "
<< value << " at " << this << std::endl;
}
};
// 전역 참조 카운트 테이블: 객체 포인터와 참조 횟수 매핑
std::unordered_map<Object*, int> refTable;
// 객체 생성: 참조 카운트를 1로 초기화하고 객체 반환
Object* createObject(int val) {
Object* obj = new Object(val);
refTable[obj] = 1;
return obj;
}
// 참조 증가: refTable에서 참조 카운트를 증가시킴
void addRef(Object* obj) {
if (obj != nullptr) {
auto it = refTable.find(obj);
if (it != refTable.end()) {
++it->second;
}
}
}
// 참조 해제: 참조 카운트를 감소시키고, 0이 되면 메모리 해제
void releaseRef(Object* obj) {
if (obj != nullptr) {
auto it = refTable.find(obj);
if (it != refTable.end()) {
if (--(it->second) == 0) {
refTable.erase(it);
delete obj;
}
}
}
}
int main() {
// 객체 생성 (각각 참조 카운트 1로 초기화)
Object* a = createObject(10);
Object* b = createObject(20);
// b의 참조 증가 (b를 여러 곳에서 참조한다고 가정)
addRef(b);
// b 참조 해제: 두 번 호출하여 참조 카운트가 0이 되어 메모리 해제됨
releaseRef(b);
releaseRef(b);
// a 참조 해제: 메모리 해제됨
releaseRef(a);
std::cout << "Remaining objects in refTable: "
<< refTable.size() << std::endl;
return 0;
}Tracing GC와 Reference Counting GC 비교
분류 | Tracing GC | Reference Counting GC |
|---|---|---|
기본 개념 | 루트에서 시작하여 도달 가능한 객체를 추적하고 나머지를 해제 | 참조 횟수가 0이 되는 순간 즉시 메모리 해제 |
순환 참조 | GC가 자동으로 처리 | 카운트가 0이 되지 않아 메모리 누수 발생 |
GC 실행 비용 | 객체 수 및 참조 그래프 크기에 비례 | 객체가 많을수록 카운트 갱신 부담 증가 |
Stop-the-World | GC 실행 중 프로그램 중단 | 즉시 해제, 중단 없음 |
대표 언어 | C#, Java, Python | Objective-C (ARC), Swift |
이로써 기본 GC 알고리즘 두 계열을 모두 살펴보았다. 이후에는 이 알고리즘들을 기반으로 한 최적화 전략을 다룬다.
최적화 전략
1.Generational GC(세대별 GC)
가장 널리 알려진 GC 최적화 전략이다.
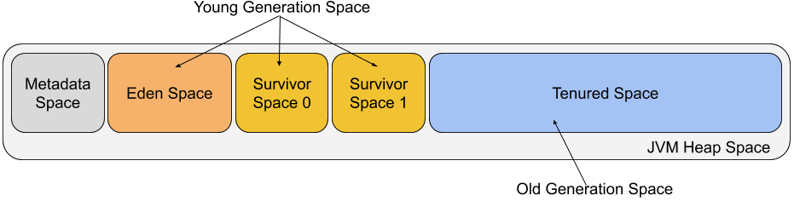
객체의 생존 기간에 따라 Young Generation 과 Old Generation 으로 구분하여 GC를 수행한다. 새로 생성된 객체(Young)는 빠르게, 오래 살아남은 객체(Old)는 상대적으로 느리게 수거한다. 이 전략의 전제는 단순하다. 대부분의 객체는 생성 직후 짧은 시간 안에 소멸한다는 경험적 관찰, 이른바 약한 세대 가설(Weak Generational Hypothesis) 이다.
Young Generation (Eden + Survivor Space)
Eden 영역
새롭게 생성된 객체가 최초로 할당되는 곳이다. 대부분의 객체는 이 영역에서 생성되고 곧 소멸하기 때문에 GC가 자주 발생한다.
Survivor 영역
Eden에서 GC를 견디고 살아남은 객체들이 이동하는 공간이다. Survivor 영역은 일반적으로 두 개로 나뉘는데, 앞서 설명한 Copying GC의 From Space / To Space 구조가 그대로 적용된다. Survivor 0이 From Space, Survivor 1이 To Space 역할을 담당한다. 여러 차례 GC를 통과한 객체는 Old Generation으로 승격(Promotion) 된다.
Young Generation에서 객체가 수거될 때를 Minor GC 라고 한다. Copying GC를 사용하기 때문에 빠르게 처리된다.
Old Generation (Tenured 영역)
Young Generation에서 반복적으로 GC를 견디며 살아남은 객체들이 이동하는 공간이다. GC 발생 빈도는 낮지만, 한 번 발생하면 대상 객체 수가 많아 처리 비용이 크다. Mark-Sweep 또는 Mark-Compact 방식으로 정리되며, GC 발생 시 Stop-the-World가 동반될 수 있다.
Old Generation에서 객체가 수거될 때를 Major GC(또는 Full GC) 라고 한다.
Old 영역은 일반적으로 Young보다 크게 할당된다. 영역이 큰 만큼 가득 차는 데 시간이 걸려 GC 빈도가 낮다.
인생에 빗대어 보면
이 구조를 사람의 일생에 비유하면 다음과 같다.
1.Eden 동산에 영혼 상태로 머물다가
2.세상의 부름을 받고 태어난다.
3.세상의 풍파를 견디며 살아가고(Survivor), 사고 없이 무사히 버텨
4.노인이 되어 사회적 존경을 얻는다(Promotion).
5.그 노인이 세상을 떠나면, 젊은이의 죽음보다 훨씬 더 많은 사람이 애도하게 된다. Old Generation의 GC 비용이 더 크다는 뜻이다.
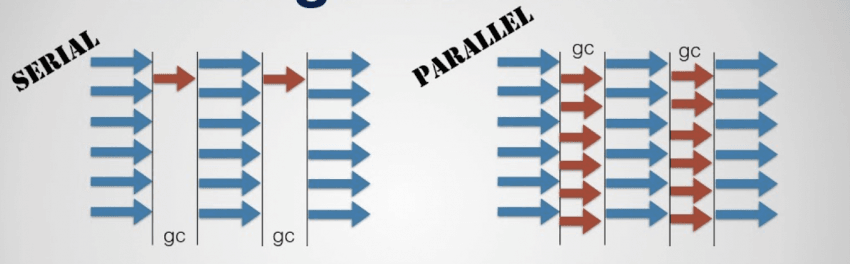
2.Parallel GC(병렬 GC)
여러 스레드를 동시에 사용하여 GC를 병렬로 수행함으로써 처리 속도를 높이는 방식이다. 단일 스레드로 GC를 수행하면 힙이 클수록 중단 시간이 선형으로 늘어나는데, 여러 스레드가 힙을 분할하여 동시에 처리하면 그 시간을 줄일 수 있다. 대용량 힙을 다루는 대형 애플리케이션에 특히 효과적이다.
단점은 스레드 간 동기화 오버헤드다. 여러 스레드가 동시에 힙을 탐색하고 객체를 수거하는 과정에서 작업 영역이 겹치지 않도록 조율해야 하므로, 스레드 수가 늘어날수록 동기화 비용도 함께 증가한다.
Generational GC와 Parallel GC는 상호 배타적이지 않다. 세대를 나누는 것과 GC를 병렬로 수행하는 것은 독립적인 전략이므로 함께 적용할 수 있으며, 실제로 Java HotSpot JVM과 .NET 런타임 모두 두 전략을 조합하여 사용한다.
이 외에도 Stop-the-World를 최소화하기 위한 Concurrent GC 계열로 발전하였으며, Java의 G1 GC와 ZGC가 대표적이다
GC는 어떻게 실행될까?

1. Stop-the-World GC
GC 실행 시 애플리케이션의 모든 스레드를 완전히 중단시키는 전통적인 방식이다. 힙 전체를 정지된 상태에서 탐색하기 때문에 구현이 단순하고 정확한 메모리 회수가 가능하다. 단점은 GC가 실행되는 동안 애플리케이션이 응답하지 않으므로, 힙이 클수록 중단 시간이 길어져 사용자 경험이 저하된다.
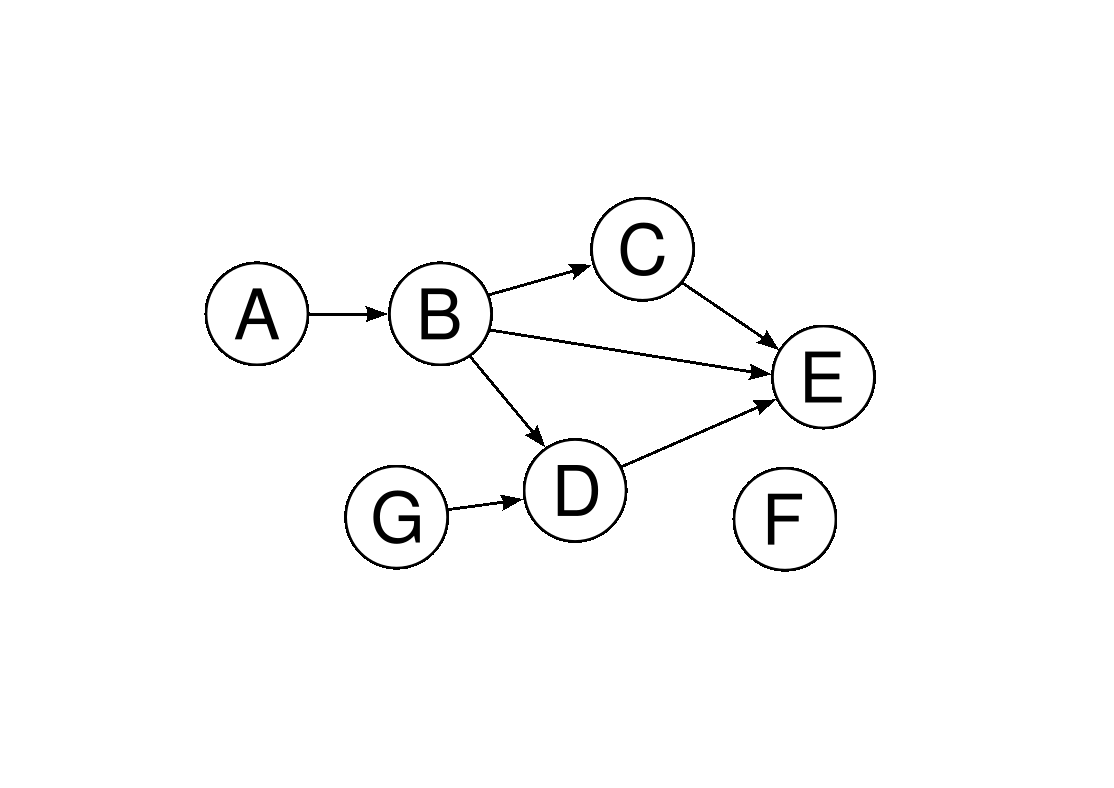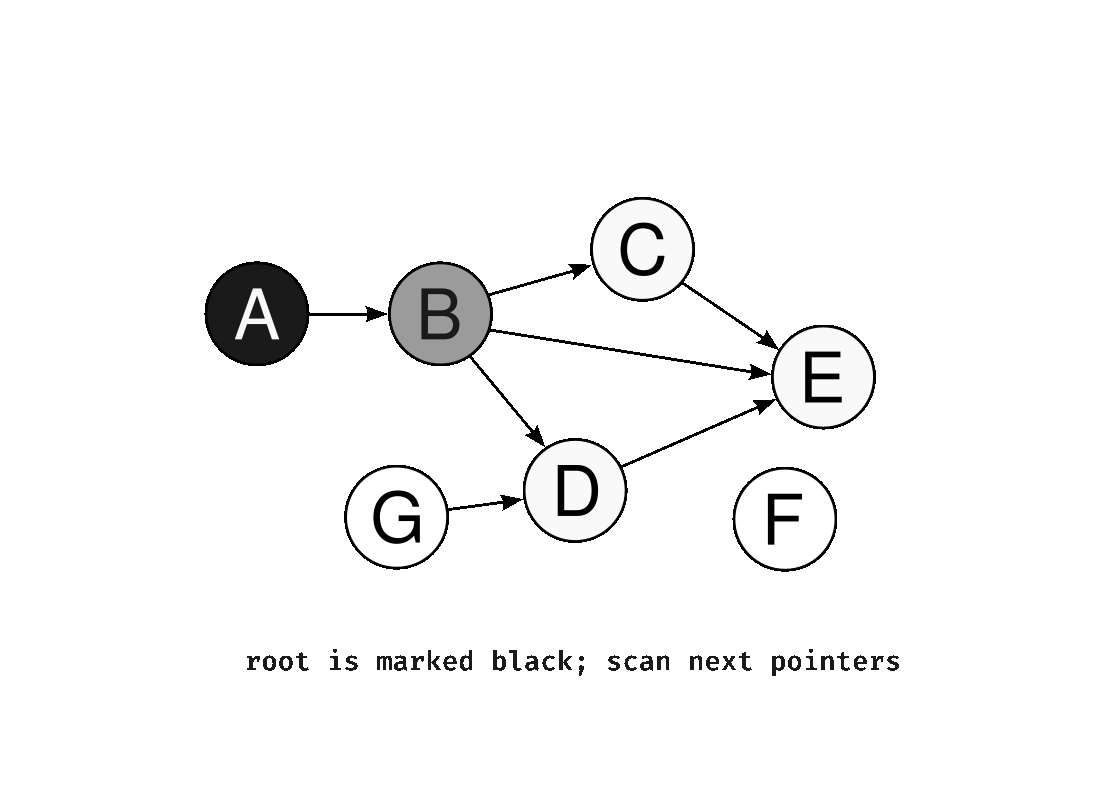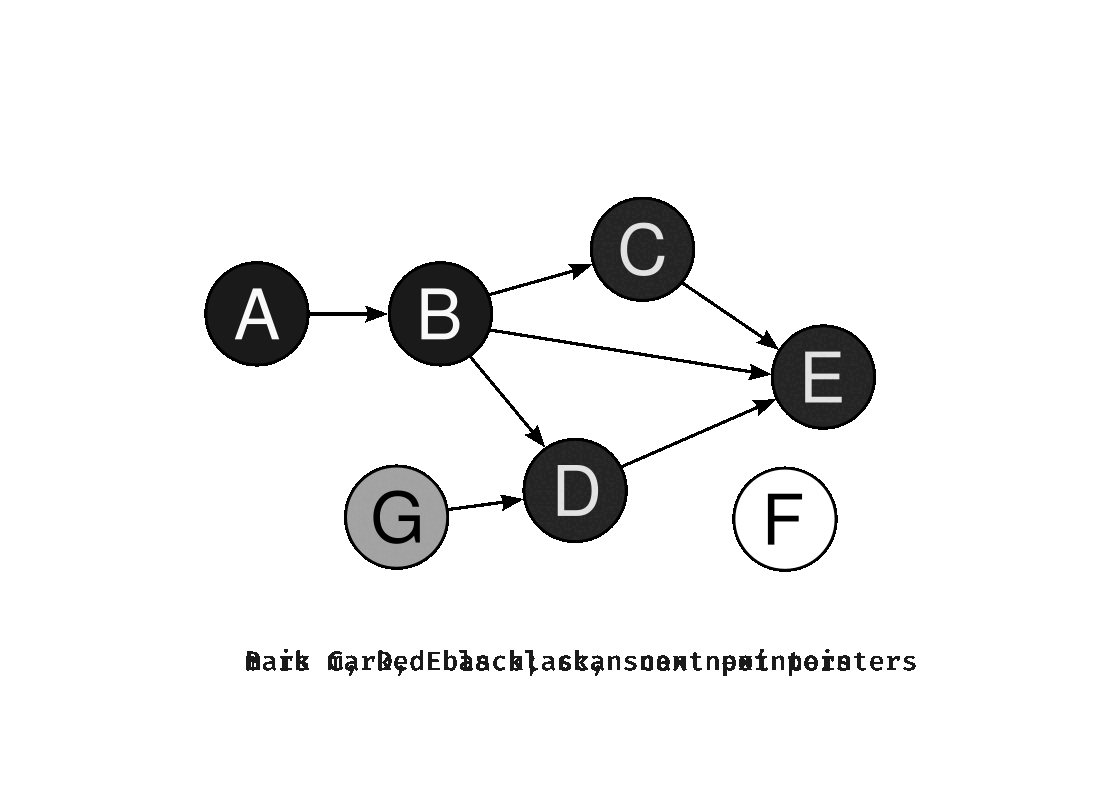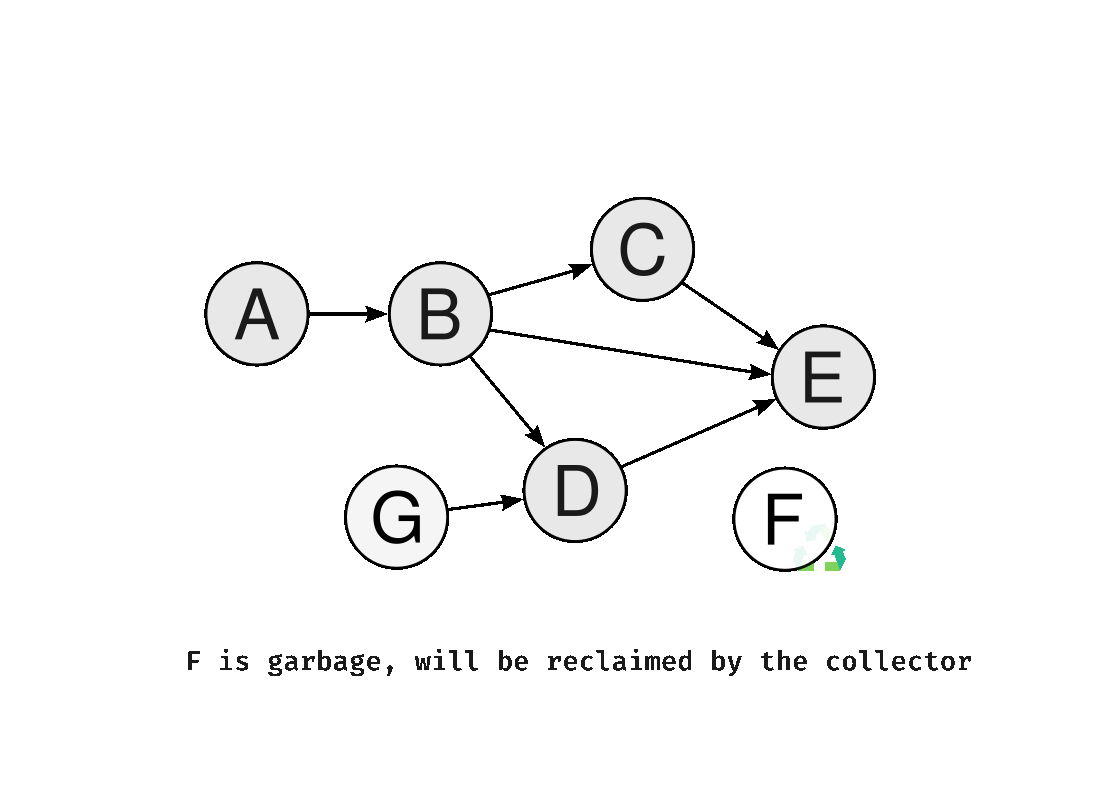
2. Incremental GC (점진적 GC)
GC를 한 번에 완료하지 않고 여러 작은 단계로 나누어 실행하는 방식이다. 애플리케이션과 GC를 번갈아 가며 수행하기 때문에 단일 중단 시간이 짧아진다.
Dijkstra의 Tri-Color Marking Algorithm 을 기반으로 구현된다. 이 알고리즘은 모든 객체를 세 가지 상태로 분류하여 처리 진행 상황을 추적한다.
흰색(White): 아직 방문하지 않은 객체. GC가 끝난 후에도 흰색으로 남은 객체는 도달 불가능한 가비지다.
회색(Gray): 방문했지만 자식 객체를 아직 처리하지 않은 객체. 처리해야 할 작업이 남아 있음을 의미한다.
검은색(Black): 방문이 완료되고 자식 객체까지 모두 처리된 객체. 살아있는 것으로 확정된 상태다.
동작 순서는 다음과 같다.
1.모든 객체를 흰색으로 초기화한다.
2.루트에서 참조된 객체를 회색으로 표시하고 큐에 추가한다.
3.회색 객체를 하나씩 꺼내 자식 객체를 회색으로 표시한 뒤, 자신은 검은색으로 변경한다.
4.회색 객체가 없을 때까지 반복한다. 남은 흰색 객체를 수거한다.
여기서 핵심 불변 조건은 검은색 객체가 흰색 객체를 직접 참조하지 않는다는 것이다. 검은색은 처리가 완료된 상태이므로, 검은색이 흰색을 직접 가리키면 그 흰색 객체는 영원히 회색을 거치지 못하고 가비지로 오수거될 위험이 생긴다. 이 조건을 유지하는 한 GC를 여러 단계로 나누어도 정확성이 보장된다.
3. Concurrent GC (동시 GC)
GC 스레드와 애플리케이션 스레드가 동시에 실행되어 Stop-the-World 시간을 최소화하는 방식이다. GC 스레드가 별도로 동작하면서 애플리케이션이 실행되는 도중에도 Mark나 복사 같은 작업을 수행한다. 다중 코어를 활용할 수 있어 대형 애플리케이션에 적합하다.
단점은 애플리케이션이 실행 중에 객체 참조 관계가 계속 변하기 때문에 메모리 관리가 복잡해진다는 점이다. 이를 해결하기 위해 위에서 설명한 Tri-Color 알고리즘에 Write Barrier를 추가하여, 참조 관계가 변경될 때마다 색상 조건이 깨지지 않도록 보정한다. Java의 G1 GC, ZGC, .NET의 Background GC가 이 방식을 채택하고 있다.
(가비지 컬렉션을 눈으로 볼 수 있는 플레이 그라운드)
마치며

조기 최적화는 모든 악의 근원이다- 도널드 커누스(Donald Knuth)
이 글에서는 GC의 역사와 현재 쓰이는 GC 알고리즘, 최적화 전략과 실행 방법을 썼다. 이후에 GC를 피하는 ZoC(Zero Allocation) 등도 있지만
이 글은 초보자를 대상으로 하기때문에, 초보자가 파악하기 어려워서 아쉽게도 생략하고, 일부 최적화 전략등을 생략했다.
직접 메모리를 다루는 것을 좋아하는 사람들은 GC를 악으로 여기며, 프로그래밍의 불확실성을 늘려준다고 말할지도 모르지만,
도널드 커누스가 말했듯 메모리 관리와 같은 '조기 최적화'에 매몰되기 보단, GC는 개발자로 하여금 '문제 해결'에 집중할 수 있게 해준다.
프로그래머의 역할은 단순히 기술을 숙지하는 것이 아니라, 당면한 문제를 해결하는 것이다.
GC는 많은 프로그래머들에게 '메모리 관리'라는 부담을 덜어주는 중요한 도구이다.
중요한 것은 'GC가 좋은가 나쁜가'가 아니라, '어떤 도구가 나의 문제를 해결하는 데 가장 적합한가'를 고민하는 것이다.