
서론
정보 은닉(Information Hiding)이라는 개념은 1971년 데이비드 파르나스가 처음 제안했다. 이듬해인 1972년, 그는 "시스템을 모듈로 분해하는 데 사용될 기준에 관하여(On the Criteria to Be Used in Decomposing Systems into Modules)"라는 논문을 발표했고, 이 논문은 소프트웨어 공학 역사에서 가장 중요한 문헌 중 하나로 평가받는다.
왜 이 논문이 등장했는가
당시의 일반적인 설계 방식은 프로세스를 단계별로 분해하는 것이었다. 순서도를 그려 제어 흐름을 파악하고, 그 흐름 순서대로 시스템을 나누는 방식이다. 문제는 이 방식이 높은 결합도와 낮은 응집도를 유발한다는 점이다. 한 단계의 데이터 표현 방식이 바뀌면 연결된 여러 모듈을 동시에 수정해야 한다.
파르나스는 이 문제에 대한 대안으로 정보 은닉을 제시했다.
파르나스가 정의한 모듈
논문이 제시하는 모듈의 기준은 간단히 요약하면 단순하게 2가지이다.
1.변경될 가능성이 있는 설계 결정은 모듈 내부에 숨긴다.
2.모듈 간 상호작용은 잘 정의된 인터페이스를 통해서만 허용한다. 내부의 데이터 구조나 알고리즘은 외부에서 볼 수 없어야 한다.
이렇게 설계하면 내부 구현이 바뀌어도 인터페이스가 유지되는 한 다른 모듈에 영향을 주지 않는다. 변경의 파급 범위가 모듈 경계 안에 봉인된다.

KWIC 예시 — 두 가지 분해 방식
그리고 파르나스는 KWIC(Key Word In Context) 인덱싱 시스템을 예시로 삼아 두 가지 분해 방식을 비교한다.
첫 번째 방식: 절차적 분해
가장 직관적인 접근은 처리 흐름 그대로 모듈을 나누는 것이다.
입력 → 순환 이동(Circular Shift) → 알파벳 정렬(Alphabetizing) → 출력
각 단계가 하나의 모듈이 된다. 순서도를 그리면 그대로 설계가 나온다는 점에서 이해하기 쉽다. 그런데 이 방식에는 구조적인 취약점이 있다. 각 모듈이 앞 단계가 만들어낸 데이터 형식에 직접 의존하기 때문이다. 순환 이동 모듈이 데이터를 배열로 넘기면, 정렬 모듈은 배열을 전제로 작성된다. 만약 저장 방식을 배열에서 연결 리스트로 바꾸면, 정렬 모듈도 수정해야 하고 출력 모듈도 수정해야 한다. 설계 결정 하나가 시스템 전체로 파급된다.
그리고 그 문제를 해결하기위하여, 하나의 방식을 제안한다.

두 번째 방식: 정보 은닉 기반 분해
파르나스가 제안하는 방식은 처리 순서가 아니라 설계 결정을 기준으로 모듈을 나누는 것이다. "데이터를 어떻게 저장할 것인가", "줄을 어떻게 이동시킬 것인가", "정렬을 어떻게 구현할 것인가"
각각의 결정이 하나의 모듈 경계가 된다.
각 모듈은 그 결정의 내부 구현을 외부에 드러내지 않는다. 외부에는 필요한 기능만 인터페이스로 노출한다. 저장 모듈이 내부적으로 배열을 쓰는지 연결 리스트를 쓰는지, 정렬 모듈이 퀵소트를 쓰는지 병합 정렬을 쓰는지는 다른 모듈이 알 필요가 없다.
결과적으로 정렬 알고리즘을 바꿔도 정렬 모듈의 인터페이스가 유지되는 한 다른 모듈은 건드리지 않아도 된다. 변경이 모듈 경계 안에 봉인된다.
이것이 파르나스가 말하는 모듈의 본질이다. 재사용 가능하다는 것도 이 봉인에서 나온다. 내부 구현이 외부에 새어나오지 않기 때문에, 다른 프로젝트나 다른 맥락에 가져다 놓아도 예상치 못한 의존성이 따라오지 않는다.
두 방식의 차이를 한 문장으로 정리하면, 절차적 분해는 "무슨 일이 일어나는가"를 기준으로 나누고, 정보 은닉은 "무엇이 바뀔 수 있는가"를 기준으로 나눈다.
안정적인 인터페이스를 유지한 채 기능 단위로 경계를 정하면, 변경이 모듈 내부에 국한된다. 오류가 줄고 유지보수가 쉬워지며, 다른 프로젝트나 맥락에서도 재사용할 수 있다. 이것이 파르나스가 말하는 모듈의 본질이다.
이 논문을 기점으로 프로그래밍 방법론은 절차적 접근에서 구조적 접근으로 전환되었다.

문제: OOP는 이 원칙을 제대로 구현했는가
이 논문은 현대 소프트웨어 공학의 토대를 만든 문헌 중 하나로 평가받는다. 절차적 분해에서 구조적 분해로의 전환, 즉 "어떤 순서로 처리하는가"에서 "무엇을 숨길 것인가"로 설계 기준이 바뀐 것이 이 논문에서 시작된다.
그런데 이 논문은 OOP를 지지하는 문헌이 아님에도, OOP의 잘못된 사용을 비판하는 근거로 자주 인용된다. 왜 그런것일까?
OOP가 오용될 때 나타나는 전형적인 패턴은 두 가지다.
첫째, 불필요한 메서드와 필드를 public으로 노출한다.
둘째, 상속을 통해 부모 클래스의 내부 구현이 자식 클래스에 그대로 드러난다.
이런 방식은 캡슐화의 외형만 갖출 뿐, 파르나스가 말한 정보 은닉과는 거리가 멀다.
근본적인 오해는 클래스를 정의하는 방식에서 비롯된다.
흔히 통용되는 "클래스 = 데이터 + 메서드"라는 정의가 그것이다.
이 정의대로 클래스를 설계하면, 결국 절차적 분해를 클래스 단위로 다시 쓴 것에 불과하다. 클래스를 기능 블록으로 바라보는 순간, 파르나스가 비판한 단계 중심 분해와 구조적으로 다를 것이 없어진다.
해결책: 진정한 정보 은닉으로서의 클래스
파르나스의 기준으로 클래스를 다시 정의하면 이렇게 된다.
클래스: 도메인 + 개념 + 책임/규칙 + 필수 인터페이스만 노출 + 내부 구현 숨기기
도메인 개념을 단위로 경계를 정하고, 그 개념이 책임지는 동작과 규칙을 내부에 봉인하며, 외부에는 필수적인 인터페이스만 노출한다.
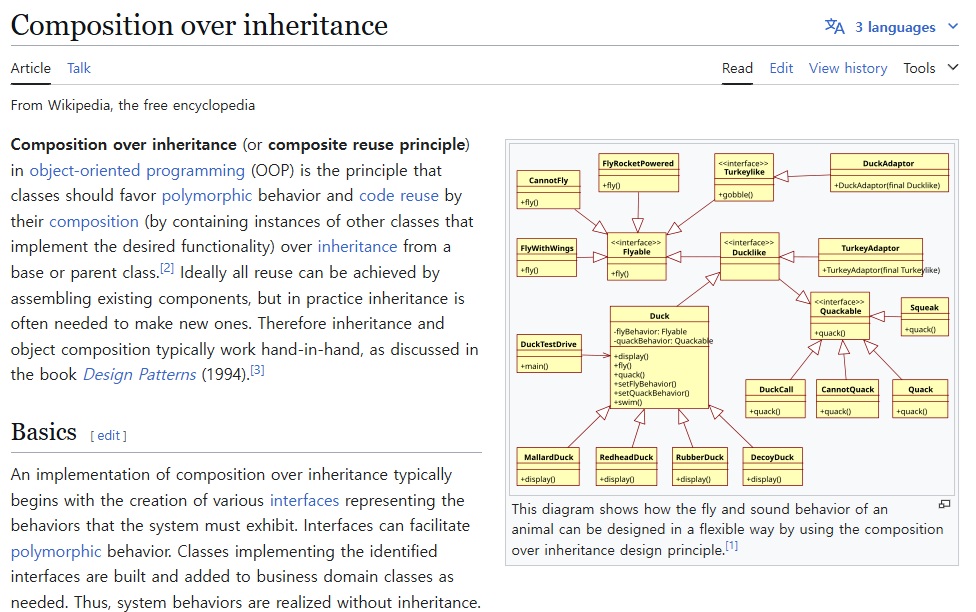
이 기준에서 보면 잘못 설계된 OOP는 정보 은닉을 구현한 것이 아니라 형식적인 캡슐화를 구현한 것이다. 현대 OOP가 "상속보다 조합(Composition over Inheritance)"을 권고하는 것도 이 맥락에서 나온다. 상속은 구조적으로 부모의 내부 구현을 자식에게 노출시키기 때문에, 파르나스의 원칙을 위반하기 쉽다.
이 관점에서 보면 DTO(Data Transfer Object)는 객체가 아니다. DTO는 내부 상태를 Getter/Setter로 그대로 노출하고 스스로 아무 판단도 하지 않는다. 행동이 없고 데이터만 있다. 로버트 마틴이 클린 코드에서 구분한 방식을 빌리면, 이것은 객체가 아니라 자료 구조다. 객체는 내부 데이터를 숨기고 행동을 노출하지만, 자료 구조는 데이터를 노출하고 행동이 없다. DTO가 나쁘다는 것이 아니다. DTO는 계층 간 데이터 전달이라는 명확한 역할이 있고, 자료 구조로서 그 역할을 충실히 수행한다. 문제는 DTO를 객체라고 부르거나, 도메인 객체를 DTO처럼 설계할 때 발생한다. 그 순간 파르나스가 말한 정보 은닉은 사라지고 절차적 분해가 클래스 문법으로 포장된 것만 남는다.
결국 1972년 파르나스가 제시한 기준은 단순하다. 바뀔 수 있는 것을 숨겨라.
하지만 바뀔 수 있는 것을 어떻게 판단할 것인가. 그 어려운 숙제를 받아든 채, 오늘도 우리는 프로그래밍을 한다.