
(명저 중의 명저 코드 컴플리트)
들어가며...
왜 우리는 항상 '모듈화'가 중요하다는 소리를 듣는데
거기서 모듈화의 핵심을 제대로 이해하지 못하는 사람들은 종종 이런 소리를 한다.
'코드를 나누면 좋다'라고 말이다
그런데 이상하게도 코드를 더 잘게 쪼갰는데도 더 복잡해지는 경우가 많다.
예를들어서 서비스 클래스를 분명히 도메인별로 나눴지만, 하나의 데이터 흐름이 여러 클래스를 오가며 오히려 파편화되어 추적이 어려워진다라거나 말이다.
이 글은 왜 그런가에 대한 이야기이다.

(1974년 Yourdon & Constantine의 구조적 설계 논문)
구조적 설계(Structured Design)는 복잡성을 줄임으로써 코드 작성, 디버깅, 수정 작업을 더 쉽게, 더 빠르게, 더 저렴하게 만들기 위한 일반적인 프로그램
설계 고려사항과 기법들의 집합이다.
이 주요 아이디어들은 거의 10년에 걸친 콘스탄타인(Mr. Constantine)의 연구 결과이다.
이 논문에서는 그 결과들을 소개하지만, 이론과 유도 과정 자체는 다루지 않는다.
이러한 아이디어들은 마이어스(Mr. Myers)에 의해 복합 설계(Composite Design)라고도 불렸다.
저자들은 이러한 프로그램 설계 기법이 HIPO6의 문서화 기법이나 구조적 프로그래밍의 코딩 기법과 호환되며 상호 보완적이라고 믿는다.
이러한 비용 절감형 설계 기법들은 항상 시스템의 다른 제약 조건들과 균형을 맞춰야 한다.
하지만 프로그래머의 시간 비용이 계속 상승함에 따라, 단순하고 변경이 쉬운 프로그램을 만드는 능력은 점점 더 중요해질 것이다.
-1974년 Yourdon & Constantine의 구조 디자인 논문
결합도와 응집도는 무엇이고 어째서 시작되었는가?
1960년대~1970년대 초반 모듈화(Modularity)에 대한 논의는 존재했다.
역사적으로는 다익스트라가 구조적 프로그래밍을 주장하며 모듈식 설계의 중요성을 강조했고, 그의 논문에서도 강조했다
그리고 1972년 데이비드 파나스의 기념비적 논문 "On the Criteria To Be Used in Decomposing Systems into Modules" (1972) 에서 정보은닉과 모듈 경계 설계를 제안했다
즉 이제 거대한 시스템을 만들기 위한 초기단계에 프로그래머들은 들어서게 되고, 모듈화라는 것이 그 도구가 될 것이 분명했다.

1971년 니클라우스 비르트(Niklaus Wirth)는 모듈화를 점진적 정제(Stepwise Refinement)과정으로 설명했다.
모듈화의 점진적 문제(Stepwise Refinement)란 무엇인가?
복잡한 문제를 해결하기위해서 하향식 설계(탑 다운)를 이야기한다.
1. 추상적인 수준에서 시작: 가장 먼저 해결 해야할 문제를 매우 높은 수준에서 정의한다. 즉 문제의 큰 그림을 그린다
2. 점진적인 구체화를 시작한다.
3. 이후 문제의 세부사항을 추가한다
4. 구현을 반복한다.
비르트는 이러한 과정이 자연스레 모듈화로 이어진다고 말했다
각 정제단계에서 도출되는 하위 문제들이 결국에는 독립적인 기능 단위 '모듈'이 되는 것이다.
-모듈은 특정 하위 문제를 해결할 것이며
-모듈간의 인터페이스는 각 단계에서 정의된 데이터와 제어 흐름에 따라 결정 된다.
따라서 높은 수준의 추상화에서 구체적인 구현으로가는 과정자체가 시스템을 명확한 책임과 인터페이스를 가진 독립적 모듈로 구성하는 방법이라는 것이다.
그럼 모듈의 경계 설계와 모듈식 설계가 중요하는 것은 알겠다
그러면 자연스레 우리는 이 질문 앞에 다시 선다.
그럼 어떻게 모듈화의 품질은 어떻게 평가할 것인가?
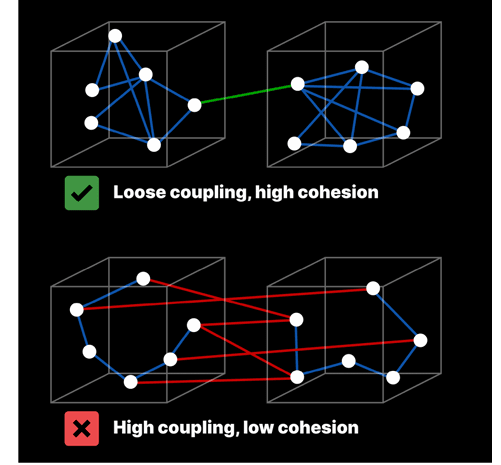
(응집도와 결합도를 잘 표현한 그림)
그리고 1974년 Yourdon & Constantine의 구조적 설계 논문에서 이것을 정량 평가하는 기준을 마련한다.
그 기준이
응집도(Cohesion)
결합도(Coupling)
이다.
이것을 바탕으로 '모듈화'는 단순한 코드 분할을 넘어 시스템 복잡도 관리의 핵심 도구로 자리잡았다.
같은 시기 앨런 케이의 Smalltalk 계열에서 OOP가 태동했고, 1980년대 후반부터 C++과 함께 산업계 주류로 올라섰다. 그러나 상속, 다형성, 동적 바인딩이 본격화되자 Yourdon/Constantine이 절차적 시대에 세운 결합도 척도로는 잡히지 않는 의존성들이 드러나기 시작했다.
이 공백을 메운 것이 1990년대의 OO 메트릭 연구다. Chidamber & Kemerer의 CK 메트릭(CBO, RFC, LCOM)은 결합도를 정량화했고, Page-Jones의 Connascence는 결합의 종류를 OOP 문법에 맞춰 재분류했으며, Briand 등은 객체지향 결합도의 분류 체계를 실증적으로 다듬었다.
이 축적된 논의가 현장 프로그래머에게 닿은 통로가 『Code Complete』였다. McConnell은 학계의 분류를 실무 감각으로 압축해
- 내용/공통/제어/스탬프/데이터 결합이라는 전통 분류 대신, 단순 데이터 결합, 단순 객체 결합, 객체 인자 결합, 의미 결합이라는 맥락 중심의 네 갈래로 다시 짰다.
한편 이 용어들은 1990년 IEEE 610.12 같은 표준 문서에도 같은 시기에 편입되며 업계 공용어로 자리잡았다
응집도와 결합도는 무엇인가?

결합도와 함께 구조적 설계에서 비롯된 응집도는 일반적으로 같은 맥락에서 논의됩니다.
응집도는 클래스 내의 모든 루틴 또는 루틴 내의 모든 코드가 중심 목적을 얼마나 잘 지원하는지, 즉 클래스가 얼마나 집중되어 있는지를 나타냅니다.
강력하게 관련된 기능을 포함하는 클래스는 강한 응집도를 갖는다고 설명되며, 경험적 목표는 응집도를 가능한 한 강하게 만드는 것입니다.
응집도는 복잡성을 관리하는 데 유용한 도구인데, 클래스 내의 코드가 중심 목적을 더 많이 지원할수록 뇌가 해당 코드가 수행하는 모든 작업을 더 쉽게 기억할 수 있기 때문입니다. 루틴 수준에서의 응집성에 대한 사고는 수십 년 동안 유용한 경험적 방법이었으며 오늘날에도 여전히 유용합니다. 클래스 수준에서는 응집성의 경험적 방법이 이 장의 앞부분과 6장에서 논의된 더 넓은 경험적 방법인 잘 정의된 추상화에 의해 크게 포괄되었습니다.
추상화는 루틴 수준에서도 유용하지만, 그 세부 수준에서는 응집도 더 동등한 위치에 있습니다.
-Code Complete 2nd Edition, Aim for Strong Cohesion 부분
결론부터 이야기하자면 응집도는 높게, 결합도는 낮추게 하는 것이 유리하다.
응집도(Cohesion)
-모듈 내부 요소들의 기능적 연관성을 계층적 분류
결합도(Coupling)
-모듈간의 의존성 강도
그리고 이 응집도와 결합도를 판단하는 지표를 알아보자
바로 Code Complete와 Yourdon & Constantine의 논문을 바탕으로 말이다.


전통적 응집도의 분류( Yourdon & Constantine)-1974
응집도 종류 | 설명 |
|---|---|
우연적 응집 (Coincidental Cohesion) | 모듈 내 작업들이 서로 전혀 관련이 없음. 단순히 물리적으로 묶여 있을 뿐. 가장 나쁜 응집도. 예: |
논리적 응집 (Logical Cohesion) | 관련은 있지만 작업을 선택적으로 수행함. 하나의 진입점에서 분기(switch/case)로 동작이 결정됨. 예: |
시간적 응집 (Temporal Cohesion) | 시간적으로 함께 실행되는 작업을 묶은 것. 예: |
절차적 응집 (Procedural Cohesion) | 모듈 내 작업들이 특정 순서로 실행되지만 서로 직접적인 연관성은 없음. 예: 파일 열고, 로그 남기고, UI 닫기 등이 순차적으로 있는 경우. |
통신적 응집 (Communicational Cohesion) | 모듈 내 모든 작업이 같은 데이터 구조를 사용. 관련성은 명확하지만, 처리 작업이 다양할 수 있음. 예: 동일한 테이블을 조회, 수정, 삭제하는 기능이 하나의 모듈에 있음. |
순차적 응집 (Sequential Cohesion) | 한 작업의 출력이 다음 작업의 입력으로 이어짐. 예: 데이터를 읽고 → 가공하고 → 저장하는 일련의 파이프라인. |
기능적 응집 (Functional Cohesion) | 모듈이 하나의 명확한 기능만 수행하며, 내부 요소들이 모두 그 기능을 위해 존재. 가장 이상적인 형태. 예: |
- 응집도 종류
우연적 응집 (Coincidental Cohesion)
- 설명
모듈 내 작업들이 서로 전혀 관련이 없음. 단순히 물리적으로 묶여 있을 뿐.
가장 나쁜 응집도.
예:
Utils.cs에 로그, 날짜 파싱, DB 커넥션이 다 들어있음.
- 응집도 종류
논리적 응집 (Logical Cohesion)
- 설명
관련은 있지만 작업을 선택적으로 수행함. 하나의 진입점에서 분기(switch/case)로 동작이 결정됨.
예:
HandleCommand(CommandType type)같은 메서드.
- 응집도 종류
시간적 응집 (Temporal Cohesion)
- 설명
시간적으로 함께 실행되는 작업을 묶은 것.
예:
InitAll(),ShutdownAll()같이 프로그램 시작/종료 시 동작을 모은 것.
- 응집도 종류
절차적 응집 (Procedural Cohesion)
- 설명
모듈 내 작업들이 특정 순서로 실행되지만 서로 직접적인 연관성은 없음.
예: 파일 열고, 로그 남기고, UI 닫기 등이 순차적으로 있는 경우.
- 응집도 종류
통신적 응집 (Communicational Cohesion)
- 설명
모듈 내 모든 작업이 같은 데이터 구조를 사용.
관련성은 명확하지만, 처리 작업이 다양할 수 있음. 예: 동일한 테이블을 조회, 수정, 삭제하는 기능이 하나의 모듈에 있음.
- 응집도 종류
순차적 응집 (Sequential Cohesion)
- 설명
한 작업의 출력이 다음 작업의 입력으로 이어짐.
예: 데이터를 읽고 → 가공하고 → 저장하는 일련의 파이프라인.
- 응집도 종류
기능적 응집 (Functional Cohesion)
- 설명
모듈이 하나의 명확한 기능만 수행하며, 내부 요소들이 모두 그 기능을 위해 존재. 가장 이상적인 형태.
예:
CalculateTax(),GenerateReport()같은 함수
코드 컴플리트에서는 모듈 또는 루틴에 대해서 응집도를 말하는데, 여기서 루틴은 '특정 작업을 수행하는 독립적 코드 블록'을 의미한다. 즉 클래스 단위뿐 아니라 메서드 하나하나도 응집도의 평가 대상이다.
응집도란 클래스 또는 루틴의 요소들이 얼마나 잘 서로 어울리는지를 말한다. 코드 컴플리트는 이 평가를 위에서 살펴본 7단계 분류 위에 놓고, 우연적 응집을 가장 강하게 비판하며 기능적 응집을 이상으로 삼는다.
그렇다면 응집도가 낮아지고 있다는 것을 어떻게 감지할 수 있는가?
코드 컴플리트는 다음 징후를 명시적으로 지목한다.
루틴 이름에 and 또는 or가 포함된다. 이름 자체가 "이것도 하고 저것도 한다"고 고백하는 것이다. SaveAndNotify(), ValidateOrFallback() 같은 이름은 루틴이 이미 두 개의 책임을 지고 있다는 선언이다.
매개변수가 과도하게 많다. 루틴이 처리해야 할 맥락이 내부에서 하나로 수렴되지 않기 때문에, 외부에서 여러 갈래의 정보를 주입받아야 하는 상황이 된다.
복잡한 제어 흐름이 루틴 내부에 존재한다. 하나의 루틴 안에서 여러 분기가 서로 다른 목적을 향해 흩어질 때, 응집도는 이미 무너져 있다.
아래 예시를 보자.
응집도 - 코드 예시
// 응집도가 낮은 루틴: 이름에 And가 있고, 책임이 두 개다
public void ValidateAndSaveOrder(Order order, bool sendNotification)
{
if (order.Items.Count == 0)
throw new InvalidOperationException("주문 항목이 없습니다.");
repository.Save(order);
if (sendNotification)
notificationService.Send(order.CustomerId, "주문이 접수되었습니다.");
}(응집도가 낮은 예시)
이 루틴은 세 가지 다른 관심사를 하나의 메서드에 욱여넣고 있다. 유효성 검사, 저장, 알림이다. 각각의 이유로 독립적으로 변경될 수 있는 것들이다.
알림 방식이 이메일에서 푸시로 바뀌면 이 메서드를 수정해야 한다. 저장소가 DB에서 캐시로 바뀌어도 이 메서드를 수정해야 한다. 유효성 규칙이 추가되어도 마찬가지다. 세 가지 이유로 하나의 메서드가 바뀔 수 있다는 것은, 이 메서드가 세 가지 책임을 지고 있다는 뜻이다.
테스트 관점에서도 문제가 드러난다. 저장 기능만 테스트하고 싶어도 알림 로직이 함께 실행된다. sendNotification을 false로 넘겨서 알림을 막을 수 있지만, 그것 자체가 제어 결합이고, 테스트를 위해 내부 분기를 호출자가 제어하고 있다는 신호다.
// 응집도를 높인 루틴: 각자 하나의 책임만 진다
public void ValidateOrder(Order order)
{
if (order.Items.Count == 0)
throw new InvalidOperationException("주문 항목이 없습니다.");
}
public void SaveOrder(Order order)
{
repository.Save(order);
}
public void NotifyCustomer(Order order)
{
notificationService.Send(order.CustomerId, "주문이 접수되었습니다.");
}(응집도가 높은 예시)
각 루틴은 하나의 이유로만 바뀐다. ValidateOrder는 유효성 규칙이 바뀔 때만, SaveOrder는 저장소 구현이 바뀔 때만, NotifyCustomer는 알림 방식이 바뀔 때만 수정된다. 변경의 원인이 분리된 것이다.
호출 측에서 세 루틴을 순서대로 부르는 것이 더 많은 코드처럼 보일 수 있다. 그러나 ValidateAndSaveOrder가 예외를 던졌을 때 어느 단계에서 실패했는지 스택 트레이스만으로는 바로 알 수 없다. 분리된 루틴에서는 어떤 메서드가 예외를 던졌는지가 이름으로 즉시 드러난다.
코드 컴플리트가 말하는 좋은 응집도의 결과는 구체적이다. 코드가 하나의 일에만 집중하고, 루틴 이름이 주석을 대신하며, 수정이 국지적인 범위에서만 끝나고, 루틴 내 코드 라인들 사이의 맥락성이 높아진다.
다만 기능적 응집을 추구한다고 해서 무조건 메서드를 미세하게 쪼개는 것이 정답은 아니다.
호출 흐름이 지나치게 분산되어 전체 서사를 읽기 어려워지면, 응집도를 높이려던 시도가 오히려 인지 비용을 키울 수 있다.
뒤집어 말하면, 수정 하나가 예상치 못한 여러 파일로 번져 나간다면 그것은 응집도 문제가 이미 결합도 문제로 전이된 신호다.

(Structured Design 1979년 결합도에 대한 설명)

(코드 컴플리트에서 결합도)
전통적 결합도의 분류
결합도 종류 | 설명 |
|---|---|
내용 결합 (Content Coupling) | 한 모듈이 다른 모듈의 내부(구현 세부사항)에 직접 접근하는 경우. 매우 강한 의존성을 가지며, 수정 시 외부 모듈에 직접 영향을 줌. |
공통 결합 (Common Coupling) | 여러 모듈이 전역 데이터를 공유하는 경우. 전역 상태를 누가 언제 수정하는지 추적이 어렵고, 부작용으로 디버깅이 힘들어짐. |
외부 결합 (External Coupling) | 외부 시스템, 포맷, 디바이스, 통신 규약에 의존하는 경우. 시스템 외부 변경이 내부 동작에 영향을 미칠 수 있음. |
제어 결합 (Control Coupling) | 한 모듈이 제어 플래그(조건)를 다른 모듈로 전달해서 내부 로직 흐름을 간접적으로 지시하는 경우. 의미 결합의 전조가 될 수 있음. |
스탬프 결합 (Stamp Coupling) | 전체 자료구조(예: 구조체, 클래스)를 전달하지만 일부 필드만 사용하는 경우. 불필요한 정보가 전달되어 결합도와 오해 가능성을 증가시킴. |
데이터 결합 (Data Coupling) | 필요한 데이터만 인자로 전달하는 가장 이상적인 결합 형태. 모듈 간의 의존을 최소화하고 인터페이스가 명확함. |
결합 없음 (No Coupling) | 완전히 독립적인 모듈로, 서로 간에 어떤 정보도 공유하지 않음. 보통의 시스템 설계에서는 실질적으로는 존재하지 않지만, 테스트 모듈 등에서는 가능함. |
- 결합도 종류
내용 결합 (Content Coupling)
- 설명
한 모듈이 다른 모듈의 내부(구현 세부사항)에 직접 접근하는 경우. 매우 강한 의존성을 가지며, 수정 시 외부 모듈에 직접 영향을 줌.
예: 함수 A가 함수 B 내부의 지역 변수나 private 함수를 직접 조작함.
- 결합도 종류
공통 결합 (Common Coupling)
- 설명
여러 모듈이 전역 데이터를 공유하는 경우. 전역 상태를 누가 언제 수정하는지 추적이 어렵고, 부작용으로 디버깅이 힘들어짐.
예: 전역 변수globalConfig를 여러 모듈이 동시에 참조하고 수정.
- 결합도 종류
외부 결합 (External Coupling)
- 설명
외부 시스템, 포맷, 디바이스, 통신 규약에 의존하는 경우. 시스템 외부 변경이 내부 동작에 영향을 미칠 수 있음.
예: 파일 포맷, DB 스키마, 하드웨어 프로토콜 등과 강하게 묶인 코드.
- 결합도 종류
제어 결합 (Control Coupling)
- 설명
한 모듈이 제어 플래그(조건)를 다른 모듈로 전달해서 내부 로직 흐름을 간접적으로 지시하는 경우. 의미 결합의 전조가 될 수 있음.
예:Process(flag)처럼 호출자가 내부 조건 분기를 지정.
- 결합도 종류
스탬프 결합 (Stamp Coupling)
- 설명
전체 자료구조(예: 구조체, 클래스)를 전달하지만 일부 필드만 사용하는 경우. 불필요한 정보가 전달되어 결합도와 오해 가능성을 증가시킴.
예:Process(User user)에서user.name만 씀.
- 결합도 종류
데이터 결합 (Data Coupling)
- 설명
필요한 데이터만 인자로 전달하는 가장 이상적인 결합 형태. 모듈 간의 의존을 최소화하고 인터페이스가 명확함.
예:CalculateTax(income, regionCode)처럼 필요한 값만 전달.
- 결합도 종류
결합 없음 (No Coupling)
- 설명
완전히 독립적인 모듈로, 서로 간에 어떤 정보도 공유하지 않음. 보통의 시스템 설계에서는 실질적으로는 존재하지 않지만, 테스트 모듈 등에서는 가능함.
예: 독립적으로 실행되는 유틸리티 함수.
Code Complete 기반의 결합도 유형 정리
결합도 종류 | 설명 |
|---|---|
단순 데이터 결합 (Simple-data-parameter Coupling) | 모듈 간에 전달되는 데이터가 모두 원시형(primitive)이고, 모두 매개변수(parameter)를 통해 전달되는 경우. 일반적으로 가장 이상적인 결합 형태. |
단순 객체 결합 (Simple-object Coupling) | 한 모듈이 다른 객체를 단순히 인스턴스화하거나 직접 사용하는 수준의 결합. 내부 동작을 의존하지 않기 때문에 안전한 결합으로 간주됨. |
객체 인자 결합 (Object-parameter Coupling) | 한 객체가 다른 객체를 통해 제3의 객체를 전달받아 사용하는 경우. 중간 객체는 전달될 객체의 존재와 의미를 알아야 하므로 결합이 더 타이트해짐. |
의미 결합 (Semantic Coupling) | 한 모듈이 다른 모듈의 동작 방식이나 내부 로직을 암묵적으로 이해하고 있을 때 발생. 내부 동작에 대한 사전 지식이 없으면 올바로 사용할 수 없는, 가장 위험한 결합 형태. |
- 결합도 종류
단순 데이터 결합 (Simple-data-parameter Coupling)
- 설명
모듈 간에 전달되는 데이터가 모두 원시형(primitive)이고, 모두 매개변수(parameter)를 통해 전달되는 경우. 일반적으로 가장 이상적인 결합 형태.
- 결합도 종류
단순 객체 결합 (Simple-object Coupling)
- 설명
한 모듈이 다른 객체를 단순히 인스턴스화하거나 직접 사용하는 수준의 결합. 내부 동작을 의존하지 않기 때문에 안전한 결합으로 간주됨.
- 결합도 종류
객체 인자 결합 (Object-parameter Coupling)
- 설명
한 객체가 다른 객체를 통해 제3의 객체를 전달받아 사용하는 경우. 중간 객체는 전달될 객체의 존재와 의미를 알아야 하므로 결합이 더 타이트해짐.
- 결합도 종류
의미 결합 (Semantic Coupling)
- 설명
한 모듈이 다른 모듈의 동작 방식이나 내부 로직을 암묵적으로 이해하고 있을 때 발생. 내부 동작에 대한 사전 지식이 없으면 올바로 사용할 수 없는, 가장 위험한 결합 형태.
결합도 모듈간 의존성의 강도를 말한다
재미있는 사실이 하나 있다. 1974년 요던과 콘스탄틴의 구조적 설계에 등장했던 '응집도(Cohesion)'의 척도는 객체지향 시대인 현대에도 그 개념이 거의 동일하게 적용된다. (물론, 세부적으로 따지면 루틴 중심에서 메서드 중심으로 바뀌긴했다. 하지만 의미가 크게 변하진 않았다.)
함수든 메서드든 "한 가지 일만 하라(기능적 응집도)"는 철학은 변하지 않기 때문이다.
하지만 '결합도(Coupling)'는 다르다. 1974년의 전통적 결합도(데이터, 제어 결합 등)는 철저히 서브루틴 간의 데이터 흐름만을 따지던 절차적 시대의 유물이다. 객체지향(OOP) 시대가 열리며 상속, 인터페이스, 다형성이 등장하자, 옛날 잣대로는 클래스 간의 끔찍한 의존성을 도저히 평가할 수 없게 되었다.
974년 원전에도 1979년 책에도 결합도 분류는 있었지만,
데이터/제어/스탬프/공통/내용 결합 등
서브루틴 간 데이터 흐름을 전제로 한 것이었다. 객체지향 시대가 열리자 상속, 다형성, 동적 바인딩처럼 절차적 모델로는 잡히지 않는 의존성이 전면에 드러났고, 1990년대 들어 Chidamber & Kemerer, Page-Jones, Briand로 이어지는 OO 결합도 연구가 분류 체계를 새로 짰다.
McConnell의 네 갈래 분류는 그 학계 흐름을 실무 언어로 압축한 것이
명저 『코드 컴플리트』에서 전통적 결합도 대신 객체 인자 결합(Object-parameter Coupling)이나 의미 결합(Semantic Coupling)이라는 완전히 새로운 분류 체계를 제시한 이유가 바로 이것이다. OOP 생태계에서는 데이터의 흐름보다 '객체 간의 암묵적인 맥락과 협력'이 시스템을 망가뜨리는 주범이 되었기 때문이다.
코드 컴플리트가 쓰인 시기는 OOP가 메인이 되던 시기이기때문에,
'맥락(Context) 기반의 결합도가 더 현실적이라고 여겨졌고, 객체간 협력의과 인터페이스 오용등 새로운 방법의 결합도가 도입됐다.
이러한 차이로 인해서 결합도의 분류 방법을 실전 중심으로 바꾼것이다.
전통적 결합도가 설계의 이론적 척도였다면
McConnell이 분류한 결합도는 실제 OOP 지향 개발에서 마주치는 코드간 잘못된 상호작용을 더 잘보여준다.
즉, 전통적 결합도는 "무엇을 얼마나 주고받는가"에 초점을 맞춘다.
현대적 결합도는 "상대의 내부 의미와 맥락을 얼마나 알아야 하는가"까지 본다.
전통적 결합도 - 코드 예시
내용 결합과 공통 결합은 현대 C#에서 private 접근자와 전역 상태로 재현되므로 가장 먼저 짚는다.
// 내용 결합: A가 B의 내부 상태를 직접 건드린다
public class OrderProcessor
{
public void Process(PaymentService paymentService)
{
// PaymentService의 내부 필드를 직접 조작
paymentService.retryCount = 0;
paymentService.lastError = null;
}
}(결합도가 높은 예시)
OrderProcessor가 PaymentService의 내부 필드를 직접 초기화하고 있다. 문제는 PaymentService가 자신의 상태를 스스로 관리하지 못한다는 점이다. retryCount와 lastError가 언제, 어디서, 왜 초기화되는지는 PaymentService의 코드를 봐서는 알 수 없다. OrderProcessor를 봐야만 알 수 있다.
PaymentService의 내부 구현이 바뀌면, 예를 들어 retryCount가 remainingAttempts로 이름이 바뀌거나 타입이 달라지면, OrderProcessor도 반드시 같이 수정해야 한다. 두 클래스가 하나처럼 묶여버린 것이다.
// 개선: 상태 초기화는 PaymentService 내부에서 책임진다
public class PaymentService
{
private int retryCount = 0;
private string lastError = null;
public void Reset()
{
retryCount = 0;
lastError = null;
}
}
public class OrderProcessor
{
public void Process(PaymentService paymentService)
{
paymentService.Reset(); // 내부를 알 필요가 없다
}
}(결합도가 낮은 예시)
Reset()이라는 공개 계약만 알면 된다. PaymentService가 내부적으로 무엇을 초기화하든 OrderProcessor는 관여하지 않는다.
우리가 코드를 쪼개고도 파편화의 지옥에 빠지는 이유는, 기능적 응집도를 높인 것이 아니라 단지 파일만 찢어놓고 '클래스 간의 순서와 맥락을 암묵적으로 알아야만 하는 의미 결합(Semantic Coupling)'을 시스템 전체에 흩뿌려 놓았기 때문이다.
// 공통 결합: 여러 모듈이 전역 상태를 공유한다
public static class GlobalConfig
{
public static string DatabaseUrl = "localhost";
public static int Timeout = 30;
}
public class OrderRepository
{
public void Save(Order order)
{
var conn = new DbConnection(GlobalConfig.DatabaseUrl); // 전역 참조
}
}
public class ReportService
{
public void Generate()
{
var conn = new DbConnection(GlobalConfig.DatabaseUrl); // 동일한 전역 참조
}
}
// GlobalConfig.DatabaseUrl이 바뀌면 두 모듈 모두 영향을 받는다
// 언제 누가 바꿨는지 추적이 불가능하다// 제어 결합: 호출자가 내부 분기를 지시한다
public void Process(Order order, bool isUrgent)
{
if (isUrgent)
{
priorityQueue.Enqueue(order);
}
else
{
normalQueue.Enqueue(order);
}
}
// 개선: 호출자는 내부 로직을 알 필요가 없다
public void ProcessUrgent(Order order) => priorityQueue.Enqueue(order);
public void ProcessNormal(Order order) => normalQueue.Enqueue(order);// 스탬프 결합: 필요한 것은 이름뿐인데 객체 전체를 받는다
public void SendWelcomeMail(User user)
{
mailService.Send(user.Email, "환영합니다"); // user.Email만 사용
}
// 개선: 필요한 데이터만 받는다
public void SendWelcomeMail(string email)
{
mailService.Send(email, "환영합니다");
}Code Complete 기반 결합도 - 코드 예시
의미 결합이 가장 위험하고 감지가 어렵기 때문에 예시에 가장 많은 설명을 붙였다.
// 단순 데이터 결합: 원시형만 파라미터로 전달한다
public bool IsEligibleForDiscount(int purchaseCount, decimal totalAmount)
{
return purchaseCount >= 10 && totalAmount >= 100_000m;
}// 단순 객체 결합: 객체를 인스턴스화해서 사용하지만 내부를 알 필요가 없다
public class OrderService
{
private readonly TaxCalculator taxCalculator = new TaxCalculator();
public decimal GetFinalPrice(Order order)
{
return order.BasePrice + taxCalculator.Calculate(order.BasePrice, order.Region);
}
}// 객체 인자 결합: B가 C를 A에게 전달한다
// A는 C의 존재와 타입을 알아야 한다
public class ReportBuilder
{
public Report Build(DataLoader loader)
{
var rawData = loader.GetDataSource(); // DataSource를 통해 제3의 타입에 의존
return new Report(rawData);
}
}// 의미 결합: 주석 없이는 올바른 호출 순서를 알 수 없다
public class PaymentProcessor
{
private bool isInitialized = false;
public void Initialize()
{
isInitialized = true;
}
public void Process(Payment payment)
{
// 호출자가 반드시 Initialize()를 먼저 불러야 한다는 것을
// 이 시그니처만 봐서는 알 수 없다
if (!isInitialized)
throw new InvalidOperationException("초기화가 필요합니다.");
ExecutePayment(payment);
}
}
// 개선: 초기화를 생성자에서 강제하거나, 팩토리 메서드로 감싼다
public class PaymentProcessor
{
private PaymentProcessor() { }
public static PaymentProcessor Create()
{
var processor = new PaymentProcessor();
processor.Initialize();
return processor;
}
public void Process(Payment payment) => ExecutePayment(payment);
}의미 결합의 핵심은 컴파일러가 잡지 못한다는 점이다. 코드는 문법적으로 완전히 정상이지만, 호출 순서나 내부 상태에 대한 암묵적 지식이 없으면 런타임에서야 터진다. 팀이 커질수록 이 비용은 기하급수적으로 올라간다.
그리고 이 응집도와 결합도는 서로 상호작용하며, 우리의 코드 품질을 이해하는 도구가 된다.
가령 논리적 응집을 가진 모듈은 제어 결합(Control Coupling)을 유발할 가능성이 높다는 등 서로가 상호 보완적인 관점을 가진다.

“프로그래머는 시인처럼, 순수한 사유(思考)의 재료 근처에서 일한다.
프로그래머는 허공에, 상상력의 힘으로 허공의 성을 짓는다."- 프레더릭 P. 브룩스 주니어, 『맨먼스 신화: 소프트웨어 공학에 대한 에세이』
끝맺으며
소프트웨어 설계의 역사는 모듈화 원칙의 진화사라고 할 수 있다.
1974년 Yourdon & Constantine이 제시한 응집도/결합도는 단순한 이론이 아니라, 거대 시스템 시대를 연 엔지니어들이 피땀으로 얻은 통찰이다.
코드를 분할한다는 것은 분해(decomposition)가 아니라, 새로운 추상화 계층을 창조하는 행위이다.
《Code Complete》이 강조하듯, 모듈화의 성패는
->"한 루틴이 한 문장으로 설명되는가?"(기능적 응집)
->"변경 시 얼마나 적은 파일을 건드리는가?"(낮은 결합도)
라는 현실적 질문으로 환원된다.
모듈화의 핵심은 파일 수를 늘리는 것이 아니라, 응집도는 높이고 결합도는 낮추는 방향으로 경계를 설계하는 데 있다.
그리고 이 개념들은 마이크로 서비스 아키텍쳐와 도커까지 수많은 곳으로 깊이 파고들어 곳곳에 퍼졌다.
70년대 선구자들이 남긴 유산은 변하지 않았다.
모듈화는 여전히 소프트웨어 설계의 가장 강력한 무기이고,
우리는 선배 프로그래머의 지혜를 이어받아서 당시로썬 거대한 아키텍쳐를 다룰 수 있게 되었다.
그리고 프로그래머로써 선배 프로그래머의 말 한마디에 짧은 글귀를 하나 덧붙인다
우리는 허공에 코드를 짓는다. 하지만 그 허공은, 남이 이해할 수 있어야만 한다.