
(PATRIOT MISSILE DEFENSE: Software Problem Led to System Failure at Dhahran, Saudi Arabia)
시작하기에 앞서서...
1991년 2월 25일 사우디아라비아 다란(Dhahran)의 미군 막사. 이라크가 발사한 스커드 미사일이 막사에 명중해 미군 28명이 사망했다. 미군의 패트리어트 미사일 방어 시스템이 가동 중이었지만, 스커드를 요격하지 못했다.
미 회계감사원(GAO)의 사후 보고서는 원인을 이렇게 정리한다.

Time is kept continuously by the system's internal clock in tenths of seconds but is expressed as an integer or whole number (e.g., 32, 33, 34...).
패트리어트 시스템은 내부 시간을 1/10초 단위의 정수 틱(tick)으로 셌다.
예를 들어 1초는 10틱, 100초는 1000틱이다. 문제는 이 정수 tick 값을 실제 초 단위 시간으로 바꾸려면 결국 0.1을 곱해야 한다는 점이다.
시간(time) = 틱(tick) × 0.1
그런데 0.1은 이진수로 정확히 표현되지 않는다. 10진수에서 1/3이 0.333333...으로 끝나지 않는 것처럼, 10진수 0.1은 이진수에서 다음처럼 끝나지 않는다.
0.1₁₀ = 0.0001100110011001100110011...₂
여기서 0011 패턴이 계속 반복된다.
컴퓨터는 무한히 많은 비트를 저장할 수 없기 때문에 어느 지점에서 이 값을 잘라야 한다. 패트리어트의 weapons control computer는 이 시간 변환을 제한된 24비트 register 정밀도 안에서 수행했다. 그 결과 0.1은 정확한 0.1이 아니라, 잘려나간 이진 근사값으로 계산됐다.
정확한 값은 아래의 형태다.
0.0001100110011001100110011...₂
24비트 정밀도 안에서 잘린 근사값은 다음과 같은 형태다.
0.00011001100110011001100₂
이 근사값은 10진수로 약 0.0999999046이다. 정확한 0.1보다 아주 조금 작다.
한 번의 오차는 거의 보이지 않는다. 하지만 패트리어트 시스템은 사고 당시 100시간 넘게 계속 켜져 있었다. 100시간은 360,000초이고, 1/10초 tick 기준으로는 3,600,000틱이다.
즉 아주 작은 시간 변환 오차가 긴 가동 시간과 결합하면서 커졌다. GAO 보고서의 Appendix II는 100시간 연속 운용 후 계산된 시간 오차를 0.3433초, range gate shift를 687m로 제시한다.
Scud는 초속 약 1,700~2,000m 수준으로 움직인다. 따라서 0.34초의 시간 오차는 수백 미터의 위치 예측 오차로 커진다.
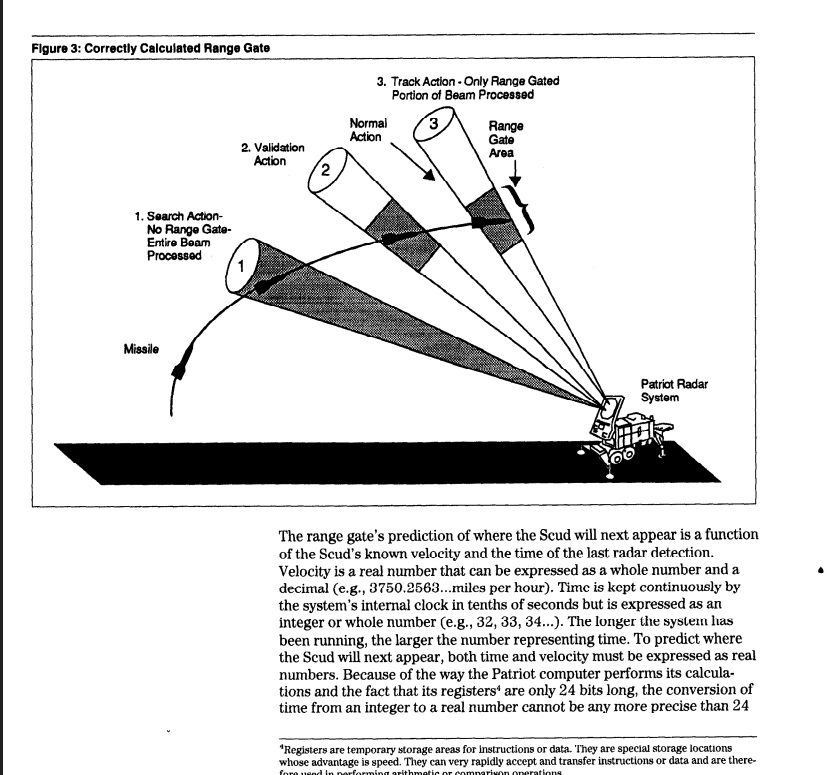
(GAO 보고서의 range gate 설명 그림. 정상 상황에서는 레이더가 넓은 탐색 빔에서 시작해, 예측된 위치 주변의 좁은 range gate만 처리한다. 다란 사고에서는 시간 오차 때문에 이 예측 위치가 실제 스커드 위치에서 벗어났다.)
결과적으로 패트리어트 시스템은 실제 스커드(Scud) 미사일이 있는 위치가 아니라, 스커드 미사일이 있을 것이라고 잘못 예측한 위치를 보고 있었다. 범위 게이트(range gate) 가 목표물의 중심에서 벗어났고, 시스템은 접근 중인 스커드 미사일(incoming Scud) 을 제대로 추적하지 못했다. 그 결과 요격 미사일은 발사되지 않았다.
이 글은 그 작은 0.1이 왜 이진수에서 무한 반복 소수가 되는지에서 시작한다. 그리고 1985년에 표준화된 IEEE 754가 왜 아직도 대부분의 컴퓨터 부동소수점 연산을 지배하는지, ML 시대에 그 표준의 가정이 어떻게 흔들리고 있는지로 이어진다.
이 글을 읽기 위해 필요한 배경지식
이 글을 읽기 위해 IEEE 754를 미리 알 필요는 없다. 다만 네 가지 감각이 있으면 좋다.
첫째, 컴퓨터는 실수를 10진수가 아니라 2진수 비트 패턴으로 저장한다. 그래서 10진수의 0.1처럼 간단해 보이는 수도 2진수에서는 0.000110011...처럼 끝나지 않을 수 있다.
둘째, float과 double은 실수를 정확히 저장하는 타입이 아니라, 유한한 비트 안에서 표현 가능한 값 중 가장 가까운 값을 저장하는 근사 표현이다. float은 보통 32비트, double은 보통 64비트를 사용하며, double이 더 정밀하지만 둘 다 근사값이라는 점은 같다.
셋째, 1e20, 1e-7 같은 표기는 과학적 표기법이다. 1e20은 1 × 10²⁰, 즉 1 뒤에 0이 20개 붙은 수를 뜻한다. 1e-7은 1 × 10⁻⁷, 즉 0.0000001을 뜻한다. 프로그래밍 언어에서는 아주 큰 수나 아주 작은 수를 간단히 쓰기 위해 이 표기를 자주 사용한다. 예를 들면 1e3은 1000, 1e6은 1,000,000, 1e-3은 0.001이다.
넷째, 딥러닝에서는 모든 숫자를 높은 정밀도로 계산하는 것보다 처리량이 더 중요할 때가 있다. 그래서 bfloat16, fp8, fp4 같은 낮은 정밀도 포맷이 등장했다.
이 글은 이 네 가지 배경 위에서 패트리어트 미사일 실패, IEEE 754, 그리고 ML 시대의 숫자 포맷 변화를 설명한다
0.1의 정체
먼저 익숙한 예시부터.
#include <iostream>
#include <iomanip>
int main() {
double a = 0.1;
double b = 0.2;
std::cout << std::setprecision(20) << (a + b) << std::endl;//std::setprecision은 출력 자릿수를 늘려 내부 오차를 보이게 한다.
return 0;
}
결과:
0.30000000000000004441누군가는 말할 것이다 버그라고.
하지만 이건 C++ 컴파일러나 CPU 결함도 아니다. IEEE 754 binary64(double)와 기본 반올림 모드(round to nearest, ties to even)를 쓰는 일반적인 구현에서는 자연스럽게 나오는 결과다.1
왜 그럴까? 10진수 0.1을 이진수로 변환하면 다음과 같다.
0.1 (10진) = 0.0001100110011001100... (2진, 무한 반복)
10진수에서 1/3이 0.333...로 표현되는 것과 같은 현상이다. 더 정확히는, 어떤 유리수를 기약분수로 만들었을 때 분모가 2의 거듭제곱이면 이진수에서 끝나고, 분모에 2가 아닌 인수가 남으면 이진수에서 반복된다.
0.5 = 1/2 -> 0.1₂ 정확히 표현 가능
0.25 = 1/4 -> 0.01₂ 정확히 표현 가능
0.1 = 1/10 -> 1/(2×5) 분모에 5가 남음 -> 무한 반복
0.2 = 1/5 -> 분모에 5가 남음 -> 무한 반복
부동소수점은 유한한 비트로 무한 소수를 잘라 저장한다. double은 약 15~17자리 10진 정밀도까지 보존하므로 0.1을 저장하는 순간 이미 1e-17 수준의 오차가 들어간다.2
0.1과 0.2는 각각 가장 가까운 binary64 값으로 반올림되어 저장된다. 그 두 근사값을 더한 뒤 다시 binary64로 반올림한 결과가 0.30000000000000004 근처의 값이다. 단순히 "오차가 누적됐다"라고만 말하면 반쯤 맞고, 더 정확히는 입력 변환과 덧셈 결과가 모두 표현 가능한 격자점으로 반올림된 결과다.
이건 표준의 결함이 아니라 유한 비트로 실수를 근사할 때 발생하는 본질적 한계다. 패트리어트는 이 한계를 100시간 누적시켰을 뿐이다.
문제는 왜 우리가 이 한계를 1985년에 표준화해서 40년 넘게 쓰고 있는가다.
pre-IEEE 754 - 혼돈의 시대
1960~70년대 부동소수점 하드웨어는 각 제조사마다 달랐다.
제조사 | 포맷 |
|---|---|
IBM System/360 | 16진 부동소수점 (base 16) |
DEC PDP-11/VAX | F-floating, D-floating |
CDC 6600 | 60비트 부동소수점 |
Cray-1 | 64비트 자체 포맷 |
Burroughs | 48비트 또는 96비트 |
같은 C 코드가 IBM에서 1.234를 출력하고 VAX에서 1.235를 출력하는 것이 일상이었다. 수치 계산 라이브러리는 기계마다 다시 짜야 했고, 어떤 기계에서 정확하던 알고리즘이 다른 기계에서 발산하기도 했다.
1970년대 부동소수점 하드웨어는 그야말로 숫자 취급 설명서가 제조사별로 다른 가전제품 같았다. 똑같이 생긴 콘센트인데 IBM에 꽂으면 선풍기가 돌고, DEC에 꽂으면 믹서기가 돌았다. 그나마 숫자라도 제대로 나오면 다행이었지만, 1 + 1이 기계마다 1.999999나 2.000001로 나왔다.
IBM System/360은 16진 부동소수점이라는 자존심을 밀고 나갔다. "우리는 4비트씩 정리한다. 세상 모든 숫자를 0.1단위로 쪼개지말자"는 멋대로 정의해놓은 철학이었다. 그 결과 0.5는 굉장히 정밀하게 표현됐고, 0.499는 "대충 그 근처겠지 뭐" 수준(Wobbling Precision)으로 표현됐다.
DEC은 F-floating, D-floating이라는 이중잣대를 들고 나왔다. 하나는 "평소엔 이걸로 쓰시고요", 다른 하나는 "돈 더 내신 분들은 이걸로 더 정밀하게". 유료 DLC로 정밀도를 판매하는 비즈니스 모델의 선구자였다.
CDC 6600은 60비트라는 애매한 숫자로 무장했다. "64비트는 너무 흔해, 우린 간지 나게 60비트로 간다"는 패션 철학이었다. Cray-1은 거기에 속도를 얹어 "숫자가 좀 틀려도 빨리 틀리면 장땡"이라는 한국인식 마인드를 장착했다.(조금 프로그래머식으로 말하면 반올림을 계산할때 꼭 필요한 여분의 메모리 공간인 가드비트[Guard Digit]를 하드웨어서 뺐다) Burroughs는 48비트와 96비트를 들고 "작은 건 작게, 큰 건 크게, 우린 전부 다름"이라는 종합선물세트였다.
이 난장판에서 프로그래머들은 같은 C 코드를 들고 기계를 옮길 때마다 매주 대한민국 훈련소에 입소한 훈련병3마냥 숫자가 다른 종교로 개종하는 걸 지켜봐야 했다. IBM에서 1.234로 출력되던 게 DEC VAX에서는 1.235로 바뀌었다.
프로그램의 계산 결과가 제조사별로 다른 복음성가를 부른 것이다. 어떤 기계에서 착실하게 수렴하던 수치해석 알고리즘이 다른 기계에선
"이런 계산 처음 봄ㅋ" 하며 발산해버렸다. 미사일 궤도, 교량 안전율, 은행 금리 계산이 "이번 주 우리 메인프레임 기분"에 따라 달라졌다.
이 혼돈을 끝내려는 시도가 1976년 Intel에서 시작됐다. Intel은 i432와 8086/8088 계열의 부동소수점 산술을 설계하면서 외부 컨설턴트 William Kahan을 영입했다.
Kahan은 UC Berkeley 수학자이자 수치해석 전문가였다. 그는 Intel 8087 산술 설계와 IEEE 754 초안 형성에 핵심적으로 참여했다. 다만 "Kahan이 위원회를 만들었다"라고 하면 부정확하다. IEEE p754 회의는 여러 회사와 연구자가 참여한 표준화 과정이었고, Kahan은 Intel의 허가를 받아 8087의 산술 사양과 그 이유를 위원회에 공개하면서 결정적 영향력을 행사했다.45
1989년 Kahan은 튜링상을 받았다. ACM의 공식 citation은 "수치해석에 대한 근본적 기여"이며, IEEE 754는 그 기여의 핵심 사례로 자주 언급된다.6이후 그는 표준의 설계 의도와 한계를 정리한 글과 강의 노트를 남겼고, 이 글의 많은 부분이 그 노트에 빚지고 있다.
여기서 짚고 갈 것 하나. IEEE 754는 1980년대 하드웨어 제약 안에서 만들어진 타협이다. 그 시점에 가능한 트랜지스터 수, 회로 복잡도, 메모리 비용을 기준으로 최선의 균형을 잡은 결과물이다. 그 균형이 2026년에도 여전히 최선인지는 다른 문제다.
비트 레이아웃 - 무엇을 저장하는가
IEEE 754의 핵심 발상은 이진법 기반의 과학적 표기법이다.1
우리가 일상에서 $123.456$을 $1.23456 \times 10^2$로 표현하듯,
이를 이진수 메모리 아키텍처로 옮긴 것이다.

(IEEE 754-2019 규격서 Section 3.4)
단, 아래의 수식은 IEEE 754-2019 규격서(Section 3.4)에 정의된 정규수(Normal number)에만 적용되는 공식이다. 0, 비정규수(Subnormal), 무한대(Infinity), NaN은 메모리 효율을 위해 완전히 다른 하드웨어 해석 규칙을 따른다.
$$v = (-1)^{S} \times (1 + \text{Fraction}) \times 2^{E - \text{bias}}$$
(단, 32비트의 bias는 127, 64비트의 bias는 1023이다)
32비트 float (Single precision)의 논리적 구조:
1 bit | 8 bits | 23 bits |
Sign ($S$) | Exponent ($E$) | Fraction ($T$) |
64비트 double (Double precision)의 논리적 구조:
1 bit | 11 bits | 52 bits |
Sign ($S$) | Exponent ($E$) | Fraction ($T$) |
값의 종류를 구분하는 '태그'로서의 비트 배치
IEEE 754의 비트 레이아웃은 단순히 실수를 압축하는 공간이 아니다. 이 구조는 값의 생명주기와 상태를 제어하는 하드웨어 태그(Tag) 역할을 겸한다. 지수부(Exponent)의 비트 패턴에 따라 소수부(Fraction)를 해석하는 렌즈가 완전히 달라진다.
Exponent 비트가 모두 0일 때 (0x00):
Fraction이 0이면: $\pm0$ (부호 있는 0)
Fraction이 0이 아니면: 비정규수 (Subnormal number). 언더플로우(Underflow)를 점진적으로 방어하기 위해 암묵적 비트가 $1$에서 $0$으로 전환되는 특수 구간이다.
Exponent 비트가 1 ~ 254일 때 (32비트 기준):
정규수 (Normal number). 앞서 언급한 기본 공식이 적용되는 일반적인 실수 영역이다.
Exponent 비트가 모두 1일 때 (0xFF):
Fraction이 0이면: $\pm\infty$ (무한대). $1.0 / 0.0$ 같은 연산의 결과다.
Fraction이 0이 아니면: NaN (Not a Number). $0.0 / 0.0$ 등 수학적으로 정의할 수 없는 계산 실패 신호다.
즉, IEEE 754 포맷은 "실수 하나"만 저장하는 그릇이 아니다. 정상적인 숫자부터 0, 극한의 미세한 수, 무한대, 심지어 예외 처리(Exception) 신호까지 단일 비트 레이아웃 안에 우아하게 욱여넣은 아키텍처의 결정체다.
라고 말하면 보통 잘 이해가 어렵다.
IEEE 754 비트 레이아웃: 택배 상자와 32비트 송장
택배 상자 겉면에 붙은 32비트짜리 송장(Invoice) 하나가 있다.
CPU라는 택배 기사는 상자를 일일이 뜯어보지 않는다. 오직 이 32비트 송장만 스캔한 뒤, "아, 이건 이렇게 던져야 하는구나"라고 기계적으로 취급한다.
이 송장은 크게 세 칸으로 나뉜다.
칸 | 이름 | 하는 일 |
1비트 | 부호 (Sign) | 상자의 위/아래 방향 화살표 (↑ 양수 / ↓ 음수) |
8비트 | 지수 (Exponent) | "이 상자 뭐야?" 알려주는 배송 등급 및 취급 태그 |
23비트 | 소수부 (Fraction) | 실제 내용물 (화물) |
여기서 핵심은 지수(Exponent) 태그다. 지수 태그의 상태에 따라 이 상자는 5가지의 완전히 다른 운명을 맞이한다.
1. 일반 화물 (정규수) — 지수 태그: 1~254 사이
평범한 숫자들이다. 3.14, -42.0, 1.0 같은 정상적인 화물.
그런데 발송자가 글쓴이같이 가난뱅이라면 어떨까? 공간을 아끼려고 "물건의 제일 앞부분(1)은 무조건 있다고 치고 송장에 안 적음"이라는 과대포장 방지법을 쓴다. (이것이 암묵적 비트다).
📦 택배 기사: "평범한 화물. 예민한 거 없음. 정규 루트로 배송."
2. 텅 빈 상자 (±0) — 지수 태그: 0, 소수부: 0
내용물이 하나도 없는 완벽한 빈 상자다.
그런데 송장에 "윗면(↑)"인지 "아랫면(↓)"인지는 꼬박꼬박 적혀 있다. 내용물도 없는데 부호가 존재하는 이유는, 택배 기사가 "이 상자가 양수 쪽에서 오다가 비워졌는지, 음수 쪽에서 오다가 비워졌는지(수렴의 관성)"를 기억하기 위해서다.
📦 택배 기사: "텅 빔. 근데 상자가 뒤집혀서 온 건 장부에 기록해 둠."
3. 소멸 직전의 가루 (비정규수) — 지수 태그: 0, 소수부: 0 아님
상자는 비어간다는데, 바닥에 화물 부스러기가 좀 남았다.
정상적인 송장 표기법으로는 담을 수 없을 만큼 미세한 숫자들이다. 이땐 "제일 앞부분 1은 무조건 있다"는 약속을 포기하고, 0.xxx로 시작하는 비상 모드에 돌입한다. 갑자기 0으로 확 증발해 버리는(Underflow) 사고를 막기 위한 완충 구간이다.
📦 택배 기사: "정상이라기엔 너무 작고, 버리기엔 아까운 부스러기들. 천천히 0으로 추락 중."
4. 우주로 날아간 상자 (Infinity) — 지수 태그: 255 (MAX), 소수부: 0
송장에 "측정 불가: 무한"이라고 적혀 있다.
$1.0 / 0.0$ 같은 배송 불가능한 오더가 떨어졌을 때, CPU가 "몰라. 답 없어. 근데 이 방향으로 계속 감" 하면서 던져버리는 상자다. 부호 태그 덕분에 +∞인지 -∞인지도 칼같이 구분한다.
📦 택배 기사: "사이즈 측정 불가. 그 방향으로 지구 끝까지 던져버림."
5. 아나키스트의 우편 폭탄 (NaN) — 지수 태그: 255 (MAX), 소수부: 0 아님
송장에 삐뚤빼뚤한 붉은 글씨로 "수학은 죽었다 (Not a Number)"라고 적혀 있다.
$0.0 / 0.0$ 이나 $\sqrt{-1}$ 같이 수학의 제1원칙을 짓밟는 범죄적 사상이 입력되었을 때 시스템이 배출하는, 일종의 '유나바머(Unabomber) 우편 폭탄'이다. 이 상자 안에는 화물 대신, 기존 연산 체계를 혐오하는 아나키스트의 장문 선언문이 들어있다.
이 상자의 가장 무서운 점은 자비 없는 폭발성이다. 택배 기사(CPU)가 무심코 이 상자를 다른 멀쩡한 숫자 상자와 묶어 덧셈이나 곱셈 컨베이어 벨트(ALU)에 올리는 순간, 펑 하고 터져버린다. 어떤 우량 화물을 가져다 붙여도 결과물은 무조건 잿더미(NaN)가 된다. 단 하나의 NaN 상자가 전체 계산 파이프라인을 타고 흐르며 연쇄 우편 테러를 일으키는 셈이다. 뭐가 됐건 위험한 건 버리는 게 제일이다.
📦 택배 기사: "화물 아님. 세상을 증오하는 불온서적 들어있음. 다른 화물이랑 스치는 순간 다 같이 터짐. 제발 그냥 버려라."
Sign 비트 ($S$)
가장 최상위 1비트(MSB). 0이면 양수, 1이면 음수다. 부호-크기(Sign-Magnitude) 방식을 취하므로, 2의 보수(Two's complement) 방식과 달리 $+0$과 $-0$이 물리적으로 별개로 존재하게 된다.
Exponent와 Bias (편향)
8비트 Exponent는 물리적으로 0에서 255까지의 정수를 담는다. 하지만 부동소수점은 $0.001$처럼 아주 작은 수를 표현하기 위해 음수 지수($2^{-3}$)도 가져야 한다. 이를 위해 IEEE 754는 2의 보수를 쓰는 대신 Bias(편향)라는 기법을 도입했다.
32비트 float의 경우 Bias는 127이다. 메모리에 저장된 정수 $E$에서 127을 빼야 비로소 실제 수학적 지수가 도출된다.
저장된 비트:
10000000($= 128$) $\rightarrow$ 실제 지수: $128 - 127 = 1$저장된 비트:
01111110($= 126$) $\rightarrow$ 실제 지수: $126 - 127 = -1$
왜 굳이 음수를 표현하는 훌륭한 '2의 보수'를 버리고 Bias를 도입했을까?
이는 1980년대 하드웨어 엔지니어들의 지독한 최적화의 산물이다. Bias를 적용하면, 양의 부동소수점 두 개를 비교할 때 복잡한 부동소수점 연산기(FPU)를 거칠 필요 없이 단순한 정수 비교기(Integer Comparator)에 비트를 밀어 넣는 것만으로도 완벽하게 대소 비교(Lexicographical ordering)가 성립한다.
Fraction과 Implicit Leading Bit (암묵적 비트)
흔히 가수(Mantissa)라 부르지만, IEEE 754의 공식 명칭은 Fraction(소수부)이다.
이진수로 정규화된 부동소수점은 항상 $1.xxx \dots \times 2^n$ 형태를 띤다. 여기서 소수점 앞의 $1$은 수학적 정의상 반드시 존재하므로, 메모리 트랜지스터를 낭비하며 저장할 이유가 없다. 이를 하드웨어 설계 용어로 암묵적 비트(Implicit Leading Bit)라 부른다.
따라서 32비트 float는 물리적으로 23비트의 Fraction을 가지지만, 생략된 1비트를 포함해 논리적으로는 24비트의 유효숫자(Significand) 정밀도를 지닌다. float의 정밀도가 "약 7자리의 10진수 유효숫자"를 가진다고 말하는 수학적 근거가 바로 이것이다.
($\log_{10}(2^{24}) \approx 7.22$)
실제 0.1 들여다보기
C++에서 0.1의 비트 패턴을 직접 보자.
#include <iostream>
#include <bit>
#include <bitset>
#include <cstdint>
int main() {
float f = 0.1f;
uint32_t bits = std::bit_cast<uint32_t>(f);
std::bitset<32> b(bits);
std::cout << b << std::endl;
return 0;
}
출력:
00111101110011001100110011001101
분해하면:
sign: 0
exponent: 01111011 (= 123, 실제 지수 = 123 - 127 = -4)
mantissa: 10011001100110011001101
mantissa의 10011001100110011001101 부분에서 1001이 반복되는 패턴이 보일 것이다. 이게 0.1의 이진 무한 반복 소수를 23비트까지 잘라낸 결과다. 마지막 비트는 라운딩되어 1이다.
이 비트 패턴이 표현하는 실제 값은 약 0.10000000149011612다. float에 0.1을 넣는 순간 우리는 정확한 0.1을 저장한 게 아니라 0.10000000149...를 저장한 것이다.
특수값들 - 표준이 정의한 예외
IEEE 754는 일반적인 부동소수점 값 외에 몇 가지 특수값을 정의한다.[1] 이게 또 다른 "당연한 게 깨지는" 지점이다.
±0
부호 비트가 있다는 건 0도 두 개라는 뜻이다. +0과 -0이 별개로 존재한다.
double pos_zero = 0.0;
double neg_zero = -0.0;
std::cout << (pos_zero == neg_zero) << std::endl; // 1
std::cout << (1.0 / pos_zero) << std::endl; // inf
std::cout << (1.0 / neg_zero) << std::endl; // -inf
== 비교에서는 같다고 나오지만, 나눗셈의 결과는 다르다. 부호가 살아 있다.
수학적으로 0과 -0은 같다. 그러나 IEEE 754는 "0에서 어느 방향으로 underflow했는가"를 보존하기 위해 두 개를 분리한다. 1980년대 수치 알고리즘 설계자들이 원했던 정보다.
±∞
기본 반올림 모드(round to nearest)에서 오버플로가 발생하면 보통 무한대로 간다.
double large = 1e308;
std::cout << large * 10 << std::endl; // inf
std::cout << -large * 10 << std::endl; // -inf
옛날 부동소수점은 오버플로 시 trap(예외 발생)하거나 큰 임의의 수가 되는 등 동작이 일관되지 않았다. IEEE 754는 ±∞를 명시적 값으로 정의해서 계산이 멈추지 않고 진행되도록 했다.
다만 "오버플로는 항상 무한대"라고 외우면 안 된다. IEEE 754에는 여러 rounding mode가 있고, 방향성 있는 반올림에서는 최대 유한값으로 포화되는 경우도 있다. 실무에서 중요한 건 다음 정도다.
기본 round-to-nearest:
너무 큰 양수 -> +∞
너무 작은 음수 -> -∞
방향성 있는 반올림:
방향에 따라 최대 유한값이 될 수 있다.
NaN - 자기 자신과 같지 않은 유일한 값
NaN은 Not a Number의 약자다. 0/0, ∞-∞, sqrt(-1) 같은 부정형 결과에 할당된다.
double nan = 0.0 / 0.0;
std::cout << (nan == nan) << std::endl; // 0 (false)
NaN은 자기 자신과도 같지 않다. 이건 IEEE 754가 명시적으로 그렇게 정의했다. 핵심은 NaN이 수직선 위의 어떤 값도 아니라는 점이다. 그래서 x < y, x > y, x == y 같은 일반 비교는 NaN이 끼는 순간 "순서가 정해지지 않은 비교(unordered comparison)"가 된다.
NaN == NaN -> false
NaN < 1.0 -> false
NaN > 1.0 -> false
NaN != NaN -> true
이 덕분에 NaN은 계산 중에 조용히 전파되면서 "여기 어딘가에서 수치적으로 정의되지 않는 일이 있었다"는 신호가 된다. 좋은 점은 계산을 즉시 중단하지 않는다는 것이고, 나쁜 점은 NaN이 한참 뒤에 발견되면 원인을 거슬러 올라가기 어렵다는 것이다.
이 정의 덕분에 NaN을 검출하는 정식 방법은 다음과 같다.
bool is_nan(double x) {
return x != x;
}
자기 자신과 비교해서 다르면 NaN. 자기 자신과 같지 않은 값이 IEEE 754에는 단 하나 존재하고, 그게 NaN이다.
subnormal - 0과 최소 정규수 사이
정규화된 부동소수점은 1.xxx × 2^n 형태다. exponent가 가질 수 있는 최솟값은 float의 경우 -126이다. 따라서 표현 가능한 최소 정규수는 약 1.18 × 10^-38이다.
그렇다면 그보다 작은 수는? 0으로 잘라버릴 수도 있지만(flush to zero), IEEE 754는 더 우아한 처리를 택했다. subnormal(또는 denormal) 영역이다.
exponent가 모두 0인 패턴에서는 0.xxx × 2^-126 형태로 정규화 없이 mantissa를 쓴다. 이렇게 하면 정밀도는 떨어지지만 0까지의 거리를 더 매끄럽게 채울 수 있다. 이걸 gradual underflow라고 한다.
문제는 성능이다. 일부 CPU와 GPU에서는 subnormal 연산이 일반적인 부동소수점 fast path에서 벗어나 훨씬 느려질 수 있다. 오디오 처리, DSP, 신경망 forward pass처럼 작은 수가 누적되는 도메인에서 이 성능 절벽은 실제 문제가 된다. 그래서 많은 고성능 도메인은 FPU의 FTZ(flush-to-zero) 또는 DAZ(denormals-are-zero) 모드를 활성화해서 정확한 gradual underflow 대신 속도를 택한다.
IEEE 754가 진짜로 표준화한 것
IEEE 754는 단순히 "float은 sign/exponent/mantissa로 저장한다"는 비트 포맷만 정한 표준이 아니다. 더 중요한 것은 연산의 의미다.
표준이 맞추려 한 것은 다음이다.
1. 같은 입력이면 같은 기본 연산 결과가 나오게 한다.
2. 덧셈, 뺄셈, 곱셈, 나눗셈, sqrt를 정확히 반올림하게 한다.
3. overflow, underflow, division by zero, invalid, inexact 같은 예외 상태를 정의한다.
4. NaN, infinity, signed zero, subnormal을 공통 언어로 만든다.
5. 반올림 모드를 명시한다.
이 중 초보자가 가장 자주 놓치는 것이 inexact다. 부동소수점 연산 대부분은 정확히 표현되지 않는다. IEEE 754는 이 사실을 숨기지 않고, 결과가 반올림되었음을 exception flag로 남길 수 있게 했다.
invalid operation : 0/0, sqrt(-1), ∞ - ∞
division by zero : 1/0
overflow : 표현 범위를 넘음
underflow : 너무 작아서 정규수로 표현 불가
inexact : 정확한 수학적 결과를 표현하지 못해 반올림됨
여기서 "exception"은 항상 언어 수준의 예외 throw를 뜻하지 않는다. IEEE 754 문맥에서는 기본적으로 상태 플래그다. 계산은 계속 진행되고, 필요한 프로그램만 나중에 플래그를 읽어 대응한다. 이 설계 덕분에 수치 코드는 매 연산마다 멈추지 않고도 오류 정보를 보존할 수 있다.
ULP - 오차를 재는 단위
부동소수점에서 "오차가 작다"는 말은 절대값만 보면 안 된다. 1 근처의 1e-7과 1e30 근처의 1e-7은 의미가 완전히 다르다.
그래서 수치 계산에서는 ULP(unit in the last place)라는 말을 쓴다. 현재 크기에서 인접한 두 부동소수점 값 사이의 간격이다.
작은 수 근처:
표현 가능한 값들이 촘촘하다.
큰 수 근처:
표현 가능한 값들 사이가 넓어진다.
이것이 다음 현상의 원인이다.
#include <iomanip>
#include <iostream>
int main() {
double x = 1e20;
std::cout << std::setprecision(20) << (x + 1.0) << std::endl;
}
수학적으로는 100000000000000000001이어야 하지만, double에서는 1.0이 사라진다. 1e20 근처에서 double의 격자 간격이 이미 1보다 훨씬 크기 때문이다.
눈물을 머금고 쓰는 메모: 부동소수점은 실수 전체를 담는 상자가 아니라, 구간마다 눈금 간격이 달라지는 자다. 큰 수 쪽으로 갈수록 자의 눈금이 50대 거래처 부장님 머리털 마냥 듬성듬성해진다. 이걸 잊으면 "왜 1을 더했는데 안 변하지?" 같은 귀신같이 버그를 만난다.
깨지는 가정들
IEEE 754를 일상적으로 쓰면서 우리는 몇 가지 수학적 가정을 무의식적으로 한다. 그 가정들이 IEEE 754에서는 깨진다.[2]
결합법칙은 성립하지 않는다
수학에서 (a + b) + c = a + (b + c)다. 부동소수점에서는 아니다.
double a = 1e20;
double b = -1e20;
double c = 1.0;
std::cout << (a + b) + c << std::endl; // 1
std::cout << a + (b + c) << std::endl; // 0
a + b를 먼저 계산하면 1e20 - 1e20 = 0이 되고, 거기에 1을 더해 1이 나온다. b + c를 먼저 계산하면 -1e20 + 1 = -1e20(1은 1e20의 정밀도 안에서 사라진다)이 되고, 거기에 1e20을 더해 0이 나온다.
이게 -ffast-math 컴파일 옵션이 위험한 이유다. 이 옵션은 결합법칙이 성립한다고 가정하고 곱셈/덧셈 순서를 자유롭게 재배치한다. 정확한 수치 계산이 필요한 코드에서는 결과가 달라질 수 있다.
0.1을 100번 더하면 10이 아니다
double sum = 0.0;
for (int i = 0; i < 100; i++) {
sum += 0.1;
}
std::cout << sum << std::endl; // 9.99999999999998
0.1을 저장할 때 들어간 오차가 100번 누적되어 1e-13 수준의 오차로 나타난다. 패트리어트 미사일이 100시간 동안 0.1초 단위로 누적시킨 오차가 0.34초였던 게 정확히 이 원리다.
완화책으로는 Kahan summation 같은 보상 합산 알고리즘이 있다. 다만 이 알고리즘은 IEEE 754 이후에 나온 땜질이 아니라, Kahan이 1960년대부터 다루던 truncation/roundoff error 감소 기법의 계열이다.7
#include <vector>
double kahan_sum(const std::vector<double>& xs) {
double sum = 0.0;
double c = 0.0; // 잃어버린 작은 항의 보상값
for (double x : xs) {
double y = x - c;
double t = sum + y;
c = (t - sum) - y;
sum = t;
}
return sum;
}
핵심은 "작아서 사라진 조각"을 별도 변수 c에 저장했다가 다음 덧셈에서 보정하는 것이다. 이 방법도 마법은 아니지만, 단순 누적보다 훨씬 안정적인 경우가 많다.
정수도 어느 순간부터 정확하지 않다
double은 실수를 근사하지만, 작은 정수는 정확히 표현한다. binary64는 significand가 53비트 정밀도를 가지므로, 절댓값이 2^53 이하인 정수는 모두 정확히 표현할 수 있다.
문제는 그 다음부터다.
#include <iomanip>
#include <iostream>
int main() {
double x = 9007199254740992.0; // 2^53
std::cout << std::setprecision(17) << x << std::endl;
std::cout << std::setprecision(17) << (x + 1.0) << std::endl;
std::cout << std::setprecision(17) << (x + 2.0) << std::endl;
}
일반적인 결과:
9007199254740992
9007199254740992
9007199254740994
2^53 근처에서는 표현 가능한 double 값의 간격이 2가 된다. 그래서 +1은 격자 사이에 떨어져 사라지고, +2는 다음 격자점으로 이동한다. JavaScript의 Number.MAX_SAFE_INTEGER가 2^53 - 1인 이유도 이것이다.
catastrophic cancellation
비슷한 크기의 두 수를 빼면 유효 숫자가 급격히 사라진다.
double a = 1000000000.1;
double b = 1000000000.0;
double diff = a - b; // 0.10000002384185791
a와 b를 저장할 때 이미 큰 수의 정밀도 한계에 부딪힌 상태다. 두 값의 차이가 0.1이어야 하지만 그 정밀도가 보장되지 않는다.
이게 이차방정식 근의 공식을 그대로 코딩하면 안 되는 이유다. -b + sqrt(b² - 4ac)에서 b가 크고 4ac가 작으면 sqrt(b² - 4ac) ≈ b가 되어 두 비슷한 수의 차로 변하고, 유효 숫자가 사라진다. 수치해석 교과서가 가장 먼저 다루는 사례다.
일상에서 많이 저지르는 실수들
-ffast-math는 왜 위험한가
GCC와 Clang의 -ffast-math는 이름은 가볍지만 의미는 꽤 크다. GCC 기준으로 -ffast-math는 -funsafe-math-optimizations, -ffinite-math-only, -fno-rounding-math, -fno-signaling-nans, -fexcess-precision=fast 같은 옵션 묶음을 켠다.8
결과적으로 컴파일러는 다음 식의 세계에 가까운 가정을 한다.
NaN이나 ±∞가 없다고 가정해도 된다.
현재 rounding mode가 바뀌지 않는다고 봐도 된다.
signaling NaN을 신경 쓰지 않아도 된다.
일부 수학 함수의 errno/예외 의미를 약화해도 된다.
곱셈과 덧셈을 FMA로 합치거나 연산 순서를 바꿔도 된다.
성능은 빨라질 수 있다. 대신 IEEE 754가 보장하려던 NaN, infinity, rounding mode, 예외 상태, 연산 순서 의미가 약해진다. 게임 엔진이나 그래픽처럼 마지막 자리의 오차가 무의미한 도메인에서는 쓸 수 있지만, 과학 계산, 금융, 의료 영상처럼 결과의 재현 가능성이 중요한 도메인에서는 검증 없이 켜면 안 된다.
특히 다른 라이브러리와 링킹할 때 -ffast-math가 글로벌하게 켜지면, 그 라이브러리가 가정하는 IEEE 754 동작이 깨질 수 있다. Boost나 Eigen 같은 numerical 라이브러리는 이를 명시적으로 경고한다.
돈은 부동소수점으로 다루지 않는다
double price = 0.10;
double total = 0.0;
for (int i = 0; i < 1000; i++) {
total += price;
}
std::cout << total << std::endl; // 99.999999999998593
거래 금액을 부동소수점으로 누적하면 누적 오차와 반올림 정책 불일치가 회계 결과로 새어 나올 수 있다. 그래서 금융 시스템의 정산·원장 영역은 BigDecimal(자바), decimal(C#, Python), 정수 기반 cent 단위(많은 핀테크)를 쓴다.
GPU와 fast math의 거래
GPU는 워크로드에 따라 IEEE 754 의미를 엄격히 지키기도 하고, 성능을 위해 relaxed/approximate 연산을 허용하기도 한다. "GPU는 기본적으로 IEEE 754를 안 지킨다"라고 말하면 너무 거칠다.
CUDA의 경우 --use_fast_math를 켜면 --ftz=true, --prec-div=false, --prec-sqrt=false, --fmad=true가 함께 켜진다.9
--ftz=true:
single precision denormal을 0으로 flush한다.
--prec-div=false:
single precision division/reciprocal에서 빠른 근사를 허용한다.
--prec-sqrt=false:
single precision sqrt에서 빠른 근사를 허용한다.
--fmad=true:
multiply-add를 FMA로 합칠 수 있다.
픽셀 한두 개의 색이 1/255 정도 다르게 나오는 건 사람 눈에 안 보일 수 있다. 하지만 같은 차이가 물리 시뮬레이션, 금융 리스크, 의료 영상 재구성에 들어가면 의미가 달라진다. 그래서 GPU 수치 계산은 항상 "정확도 모드"와 "처리량 모드" 사이의 선택이다.
ML 시대의 균열
여기서부터가 이 글의 본 주제다.
IEEE 754가 1985년에 정의한 트레이드오프는 "정확도 vs 하드웨어 비용"이었다. 그 시대의 수치 계산은 과학 시뮬레이션, 공학 해석, 금융 계산이 주류였고, 모두 정확도가 결과의 신뢰성을 좌우했다.
2010년대 중반 이후 ML이 부상하면서 트레이드오프가 바뀌었다.
신경망 학습에서 가중치 하나하나의 정밀도는 별로 중요하지 않다. 수억 개의 파라미터가 평균적으로 맞는 방향으로 업데이트되면 충분하다. 오히려 처리량(throughput)이 결과 품질을 결정한다. 같은 시간에 더 많은 데이터를 처리할 수 있으면 더 큰 모델, 더 긴 학습이 가능하고 그게 곧 성능이다.
이 인식 전환이 IEEE 754를 균열시키기 시작했다.
bfloat16 - Google의 반란
2017년 Google이 TPU v2를 공개하며 도입한 bfloat16(brain floating point)이 이 흐름의 시작이었다.10
IEEE 754의 float16(half precision)은 sign 1 + exponent 5 + mantissa 10이다. 16비트 안에서 mantissa에 더 많이 할당해 정밀도를 보존한다.
bfloat16은 sign 1 + exponent 8 + mantissa 7이다. mantissa를 희생하고 exponent를 float32와 동일하게 가져갔다. 결과적으로 정밀도는 떨어지지만 표현 가능한 범위(dynamic range)는 float32와 같다. Google TPU에서는 bfloat16 곱셈 결과를 FP32로 누적하는 식으로 쓰인다.5
왜 이런 선택을 했는가? 신경망 학습에서는 gradient가 매우 작거나 매우 클 수 있고, 범위가 부족하면 underflow나 overflow가 발생해서 학습이 깨진다. 반면 mantissa의 정밀도는 부족해도 stochastic gradient descent의 평균화가 어느 정도 보정한다.
Google TPU, NVIDIA Ampere(A100), Intel Xeon 일부 세대가 bfloat16을 네이티브 지원한다. IEEE 754가 정의한 binary16과는 다른 포맷이지만, ML에서는 사실상 표준적인 mixed precision 선택지가 됐다.
fp8과 더 작은 포맷들
2022년 NVIDIA, Arm, Intel은 FP8 Formats for Deep Learning을 공동 발표했고, 같은 해 NVIDIA Hopper(H100)가 fp8을 네이티브 지원하기 시작했다11
fp8에는 두 가지 변종이 있다. E4M3(exp 4 + mantissa 3)와 E5M2(exp 5 + mantissa 2). forward pass에는 E4M3, backward pass에는 E5M2를 쓰는 식으로 워크로드에 따라 다른 포맷을 섞어 쓴다.
2024년 NVIDIA Blackwell(B200)은 fp4까지 내려갔다. 4비트 부동소수점. exponent와 mantissa를 합쳐 4비트로 부동소수점을 표현한다. 더 정확히는 fp4는 16개의 값만 표현 가능한 사실상 lookup table에 가깝다.12
이 포맷들은 IEEE 754의 전통적 목표였던 범용 수치 계산의 안정성보다, ML 워크로드의 처리량과 메모리 효율을 앞세운 결과물이다. "정확도를 완전히 포기했다"기보다는 정확도가 필요한 위치와 필요하지 않은 위치를 분리한다고 보는 편이 정확하다.
가중치/activation 저장:
낮은 정밀도 허용
행렬 곱:
낮은 정밀도 입력 사용
누적(accumulation):
FP32 또는 더 넓은 accumulator 사용
loss scaling / quantization scale:
작은 포맷의 범위를 보정하는 메타데이터 사용
즉 ML 시대의 숫자 포맷은 "하나의 숫자 타입이 모든 정확성을 책임진다"는 모델에서 벗어난다. 포맷, scale, accumulator, optimizer가 함께 정확도를 만든다.
무엇이 끝나고 무엇이 시작되는가
물론 IEEE 754가 완전히 끝났다는 것은 아니다.
과학 계산, 공학 시뮬레이션, CAD, 렌더링, 통계 모델링은 여전히 float32와 float64를 쓴다. 금융도 리스크 모델, 옵션 가격 계산, 시뮬레이션에는 float64를 많이 쓴다. 다만 회계·정산·원장 금액은 decimal 또는 정수 fixed-point를 쓰는 것이 일반적이다.
그러나 ML 학습과 추론이 컴퓨팅 자원의 큰 비중을 차지하면서, GPU와 TPU의 트랜지스터는 점점 IEEE 754가 아닌 포맷에 할당되고 있다. NVIDIA H100의 부동소수점 처리 능력은 bfloat16과 fp8에서 압도적으로 크고, float64는 상대적으로 빈약하다.
1985년에 굳은 표준이 40여 년째 모든 컴퓨팅을 지배할 것이라는 가정이 처음으로 흔들리고 있다.
마치며...

Floating point numbers are like sandpiles: every time you move one you lose a little sand and you pick up a little dirt.
부동소수점은 모래더미와 같다. 이리저리 옮겨 담을때마다 모래는 조금씩 흘러내리고, 그 자리에 먼지가 조금씩 섞여 들어간다.
— Brian Kernighan & P.J. Plauger (The Elements of Programming Style, 1974) P.117
우리는 종종 기술의 거대한 관성을 망각한다.
1985년, 당시 하드웨어의 처절한 비용 제약과 과학 계산이라는 주된 워크로드가 타협하여 탄생한 결과물이 IEEE 754다. 그 시절의 관점에서는 기적에 가까운 합리적 결정이었다. 그러나 한 번 '표준'이라는 콘크리트가 굳어지면 불편함은 무시된다. 모든 CPU, 컴파일러, 수치 라이브러리, 네트워크 프로토콜이 그 기반 위에 쌓인다. 기술의 표준은 이상적인 우아함이 아니라, 이미 깔려버린 인프라의 매몰 비용과 생태계의 관성으로 연명한다.
표준은 하나의 성이다. 우리는 그 성벽 안에서 안전하게 계산하고, 성벽 밖에서는 새로운 야만인들이 다른 숫자로 다른 세계를 짓기 시작한다. 흥미로운 것은, 40년 동안 철옹성 같았던 이 관성이 최근 AI/ML 시대에 접어들며 산산조각 나고 있다는 점이다. 딥러닝이라는 새로운 거대 워크로드는 '소수점 아래의 정밀함'보다 '폭발적인 연산 속도와 대역폭'을 요구했다. 이 막대한 시장의 압력은 BF16, FP8, NF4 같은 변태적인 격자들을 새롭게 만들어내며 낡은 표준에 균열을 내고, 다시 제조사 마음대로 비트를 쪼개 쓰는 제2의 야만 시대를 열었다.
0.1 + 0.2가 0.3이 아니라는 사실은 조금도 이상한 것이 아니다. 진짜 이상한 것은, 우리가 다루는 기계는 듬성듬성하고 거친 유한한 격자 위를 위태롭게 건너뛰며 계산하는데, 우리는 자꾸만 그것을 완벽하게 이어져 있는 무한한 연속의 수직선이라고 착각한다는 점이다. 사람의 마음은 매끄러운 수직선을 꿈꾸는데, 기계의 손은 듬성듬성한 격자 위를 짚는다. 우리는 매일 이 균열 위를 걸으면서도 발밑을 내려다보는 일에 서투르다.
격자 위로 모래는 흘러내리고 먼지는 쌓인다. 한 번 옮겨 담을 때마다, 한 번 더하고 곱할 때마다, 우리가 미처 붙잡지 못한 모래알갱이들이 조용히 손가락 사이로 빠져나간다. 그렇게 빠져나간 자리에 세상의 먼지가 내려앉는다. 부동소수점은 그렇게 조금씩 닳고 조금씩 더러워진다. 우리는 완벽한 숫자를 한 번도 손에 쥔 적이 없으면서도, 그 닳아빠진 모래더미를 다시금 두 손으로 떠올린다.
그 격자의 세계 속에서도 우리는 매일 아침 0.1과 0.2를 더하며 살아간다. 흘러내린 모래와 쌓여든 먼지의 총합 위에서, 그래도 다리가 버티고 미사일이 날아가고 은행 장부가 맞아떨어지기를 기대하면서. 이 모든 것이 버틸 수 있는 이유는, 흘러내리는 양을 알고 먼지 섞이는 속도를 가늠하는 자들이 아직 이 세계를 떠받치고 있기 때문이다.
부동소수점은 모래더미와 같다. 이리저리 옮겨 담을 때마다 모래는 조금씩 흘러내리고, 그 자리에 먼지가 조금씩 섞여 들어간다. 우리는 그 먼지 섞인 모래로 성을 쌓고, 그 성을 믿고, 그 성 안에서 매일 잠이 든다.
각주
- IEEE 754-2019, IEEE Standard for Floating-Point Arithmetic (현행 표준, 1985 원본의 후속) ↩
- David Goldberg, What Every Computer Scientist Should Know About Floating-Point Arithmetic, ACM Computing Surveys 23(1), 5-48 (1991) ↩
- 대한민국 20대 남성들은 군 훈련소에 입소하면 매 주말마다 종교 행사에 참석한다. 이때 부대 내 종교 시설에서는 훈련병들에게 위문품으로 간식을 나눠주는데, 각 종교마다 제공하는 메뉴(초코파이, 햄버거 등)가 달라 매주 신앙을 바꾸는 이른바 '생계형 개종'이 흔하게 일어난다. 이번 주는 초코파이를 2개 주는 불교에 귀의했다가, 다음 주는 맥도날드 햄버거를 주는 기독교로, 그다음 주는 콜라를 얹어주는 천주교로 세례를 받는 식이다. 철저한 기복신앙이자 메뉴판에 따른 철새 행보다. ↩
- William Kahan, Lecture Notes on the Status of IEEE Standard 754 for Binary Floating-Point Arithmetic (1996) ↩
- William Kahan, An Interview with the Old Man of Floating-Point, IEEE Computer condensed version (1998). Intel 8087과 IEEE p754 형성 과정에 대한 Kahan의 회고. ↩
- ACM A. M. Turing Award - William Kahan, Association for Computing Machinery (1989). 공식 수상 사유는 "For his fundamental contributions to numerical analysis." ↩
- William Kahan, "Further remarks on reducing truncation errors", Communications of the ACM, 8(1), 1965. Kahan summation 계열의 원전. ↩
- GCC Manual, Optimize Options: -ffast-math, GCC documentation. ↩
- NVIDIA CUDA Compiler Driver, `--use_fast_math`, NVIDIA CUDA documentation. ↩
- Shibo Wang & Pankaj Kanwar, BFloat16: The secret to high performance on Cloud TPUs, Google Cloud Blog (2019) ↩
- Paulius Micikevicius et al., FP8 Formats for Deep Learning, arXiv:2209.05433 (2022) ↩
- NVIDIA Blackwell Architecture, NVIDIA, GTC (2024). 2세대 Transformer Engine의 micro-tensor scaling 기반 FP4 지원. ↩