
(《构建微服务》是广为人知的MSA入门书籍)
在开始之前...
我的主页 MAKONEA 也是基于 MSA 构建的,
在外包项目中,"请用微服务架构来开发"的需求也越来越多。
现在,这个概念似乎已经形成了"理所当然就该这样做"的氛围,但一开始并非如此。
本文将探讨MSA为何出现,
是为了解决什么问题而被选择的
让我们在历史背景中追溯这一演变过程。
技术选择,始终诞生于前一种技术的局限与失败之上。
要真正理解MSA,
在此之前,我们需要先了解当时存在哪些架构方式,以及这些方式为何存在不足。
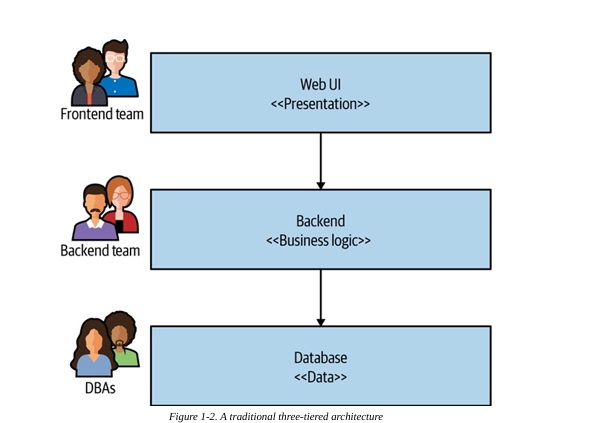
(传统3-tier架构单体应用架构示意图1)
1. Monolith(单体架构)
许多 Web 应用传统上采用 3-tier architecture 进行设计。
表示层负责界面展示,业务逻辑层负责规则与处理,数据层负责存储与查询。

어떤 조직이 시스템을 설계하면,
그 시스템의 구조는 결국 그 조직의 커뮤니케이션 구조를 반영하게 된다.
— Melvin Conway, “How Do Committees Invent?”
这里还有一点值得关注。为什么偏偏是3-tier architecture如此广泛流行?Sam Newman在《Building Microservices》中引用Conway's Law对这一问题作出了解释。系统的结构反映了构建它的组织的沟通结构。过去的IT组织往往按技术能力划分,分为数据库团队、后端开发团队和前端开发团队。3-tier architecture正是这一组织结构的直接映射。也就是说,3-tier的流行并非因为它在技术上是"正确答案",而是因为它是针对当时组织结构所做的最优设计。
这里有一点很重要。这种层次划分是逻辑上的分离,而非部署单元的分离。
无论代码被多优雅地拆分成3-tier architecture,或是涂抹了多少设计模式,一旦按下构建按钮,所有内容就会被打包成一个二进制文件,运行在一个进程之上。这就是Monolith。它源自希腊语,"单一的(mono)"加上"石头(lith)",意指由一整块石材构成的庞大结构。
Monolith的问题并非"没有结构"。其内部结构可以整理得井井有条。问题在于,变更、部署、扩展和故障的边界全都被绑定在同一个应用单元之中。
而这种捆绑在规模较小时反而是一种优势。
网络延迟趋近于零,因为模块间的连接是内存函数调用,而非网络调用。无需考虑分布式事务,单一数据库即可保证完整的数据一致性。代码流程可以在一处追踪。在初期产品、小型团队和快速验证阶段,这种简洁性是最大的优势。
MSA的布道者们(编程训练营和YouTuber们)总在诱导你从一开始就把一切拆分得细碎,但在业务生存能力尚未得到验证的情况下,就去承担网络分区和基础设施的复杂度,无异于自寻死路。
从常识来看,在没有用户的情况下,有必要刻意将系统设计得更复杂吗?完全没有。牛棚里一头牛都没有,没有任何理由把牛棚建得复杂。
理解MSA时,首先需要摒弃的误解是"Monolith是陈旧且糟糕的架构"这一观念。Monolith并非失败的架构,而是一种在系统规模超过某个临界点后,成本结构随之发生变化的架构。
成本上升的节点有三个。
Deployment coupling(部署耦合)。 即使只修复了一个登录模块的bug,也必须重新部署整个订单模块。每次部署的风险范围覆盖整个系统。部署周期随之变长,而更长的周期又迫使更多变更被打包在一次部署中,风险因此进一步放大。这是一个恶性循环。
Scaling coupling。 即使流量集中在商品查询上,也必须连同支付服务器一起进行扩容。因为所有功能都在同一个进程中,没有办法只针对实际承受负载的组件进行选择性扩展。
团队耦合。 团队规模扩大后,所有人都在同一个代码库上操作。合并冲突、构建等待、"谁动了这段代码?"这类问题变成家常便饭。团队越大,在同一个代码库上协作的成本就会呈指数级增长。
在业务生存能力尚未得到验证的阶段,如果这三个问题还不存在,那么Monolith就是正确的选择。
MSA是在这些成本真正难以承受时才打出的那张牌。
2. SOA——第一次尝试与失败
Monolith局限性问题的第一次正式尝试,是SOA(面向服务架构)。
Mark Richards 同样评价SOA是"庞大、昂贵、复杂,且实施周期过长的架构"。
2000年代初,企业级领域主导了这一运动,其核心理念很简单。
将系统拆分为服务,让这些服务通过标准化接口进行通信。
方向是对的,问题出在实现方式上。

当时,SOA确实席卷了整个业界。许多企业为了提高可复用性和跨组织协作,纷纷引入了这一架构。然而,结果却与预期大相径庭。设计与实现耗费了过多时间,结构日趋复杂,成本也大幅攀升。最终,大量项目以失败告终,SOA逐渐被业界所抛弃。借用Mark Richards的说法,SOA是"一种庞大、昂贵、复杂,且实现周期过长的架构"。这一点至关重要。问题并不在于理念本身,而在于实现这一理念的方式。
SOA的标准技术栈由SOAP(Simple Object Access Protocol)、WSDL(Web Services Description Language)和ESB(Enterprise Service Bus)组成。理论上,ESB是集中协调服务间通信的智能中间件,其核心理念是在一处统一处理路由、转换和编排。
但现实却大相径庭。
ESB无节制地吸收业务逻辑和路由规则,愈发臃肿,各个服务也因此对ESB产生了强烈的依赖。这便是所谓"智能管道、哑端点(Smart pipes, dumb endpoints)"的陷阱。服务本身的内聚性被破坏,系统的控制权再度向中心集中。本想构建分布式系统而拆分了Monolith,结果却在中央重新竖起了一个名为ESB的庞大"单点故障(SPOF, Single Point of Failure)"。
SOAP与WSDL是一场XML Schema的噩梦。每新增一个服务,就需要编写WSDL、生成存根(stub),再花费数天时间协调双方的契约。"应能轻松添加服务"这一SOA的承诺与现实之间,存在着巨大的鸿沟。
SOA的失败,本质上是哲学层面的失败,而非技术层面的失败。服务虽然被拆分,但耦合度并未真正降低,试图减少复杂性,却又制造出ESB这一新的复杂性。

微服务领域则选择了另一种不同的方式:“智能终端,哑管道”。
应用程序被设计成尽可能松散耦合,同时每个服务仍保持较高的内聚性。
——马丁·福勒2
这次失败的教训,成为此后MSA的前车之鉴。这也正是MSA将"智能端点、哑管道(Smart endpoints, dumb pipes)"奉为核心原则的根本原因。
3. Amazon的转折点——2002年Bezos Mandate
就在SOA在企业级市场走向失败的2002年,Amazon内部流传着一封具有历史意义的邮件。

(Steve Yegge公开的亚马逊内部指引回顾3)
这便是如今被称为"Bezos Mandate"或"Bezos API Memo"的内部指令,其核心内容如下。
所有团队必须通过服务接口对外暴露数据和功能。
各团队只能通过该接口进行通信。
不允许其他通信方式。禁止直接链接、直接读取数据库以及共享内存模型。
使用何种技术均可,HTTP、Corba、Pubsub,随便什么都行。
无一例外。
不遵守此规定者,一律开除。
这条规则的重要性不在于技术栈本身,而在于其强制执行力。彼时,Amazon 正在一个庞大的单体系统之上持续扩张。各团队直接读取彼此的数据库,以无内部 API 的方式直接链接库来堆砌功能。Bezos Mandate 切断了这种连接方式,要求所有功能置于 API 之后,并强制将团队间通信转变为基于网络的服务接口。起初,这不过是一条旨在降低内部耦合度的规定。然而,这一变革使 Amazon 开始将自身内部功能视为"服务"来思考。正如 Yegge 所言,此后 Amazon 转型为一个以 services-first 方式审视所有设计的组织。沿着这条脉络,基础设施功能也成为可通过 API 提供的服务,并为 2006 年 S3 与 EC2 的发布奠定了 AWS 的根基。那条为打破单体架构而设立的内部规则,最终成为云计算时代的重要基石之一。
4. Netflix——用混沌铸就韧性
2008年,Netflix遭遇了一次严重的数据库损坏事故。
(Netflix的回顾文章4)
Netflix在2016年的一篇回顾文章中提到,2008年的数据库损坏事故导致DVD配送中断长达3天,
他们表示,这一事件成为了历时7年的AWS迁移之旅的起点。
整整3天,DVD配送陷入停滞。这次事故给Netflix工程团队留下了两个深刻的教训。
第一,中心化的单一系统中,一个故障就可能导致整个服务中断。第二,故障是无法预防的,必须构建能够在故障中依然存活的系统。
2009年,Netflix开始将数据中心迁移至AWS。这不是一次简单的基础设施迁移,而是一段历时7年、将单体系统拆解为数百个微服务的漫长旅程。
在这一过程中,Netflix开发了几个核心工具。
周一,Netflix 开源了一款名为“混沌猴子”的软件。
这个工具会随机终止构成其流媒体服务的虚拟机,用于模拟服务在日常运行中会碰到的小规模故障。
这意味着,任何人都可以使用这个工具,甚至修改它的源代码来满足自己的需求。
——《连线》杂志,《Netflix 用猴子“祸害”亚马逊,现在你也可以》,2012 年 5
Chaos Monkey. 一种在生产环境中随机终止实例的自动化工具。其理念源于"验证系统能否承受故障的最好方法,就是真正制造一次故障"。Chaos Monkey的存在本身,就促使工程师们编写以故障为前提的代码。
Eureka. 服务注册中心。解决了在数百个服务实例动态启动与下线的环境中,各服务如何相互发现的问题。

(Netflix博客中介绍Hystrix的文章6)
Hystrix. 熔断器(Circuit Breaker)库。当依赖服务变慢或宕机时,快速失败(Fail Fast)对该服务的请求,防止故障扩散至整个系统。
Netflix于2012年将这些工具以开源形式公开发布。这套被称为Netflix OSS的工具集,成为当时"如何在生产环境中运营微服务"的参考实现。Netflix所创造的这些模式,此后成为MSA的标准词汇。
5. "Microservices"——正式命名之日

Netflix、eBay、Amazon、LinkedIn、Google,这些运营大规模系统的组织,以不同的名称,用相似的方式拆解着各自的系统。这种模式需要一个统一的名称。
2011年5月,聚集在意大利威尼斯附近的软件架构师们分享了各自发展出的新架构模式,并开始将其称为"microservice"。7 此后,James Lewis于2012年在技术大会上正式发表了这一概念,并于2014年与Martin Fowler共同撰写的文章中,使这一概念最终确立为行业的标准术语。
由各个具有单一职责的小型服务组成的集合
通过进程隔离,并以HTTP API等轻量级机制进行通信
每个服务可独立部署
可以与其他服务使用不同的语言和不同的数据存储 (Polyglot)
相较于集中式编排,优先保障各服务的自治性
值得注意的是,这篇文章并非"发明"了MSA。Amazon、Netflix、eBay已经运营这一模式多年。Fowler与Lewis的贡献在于为行业提供了共同的语言。有了名称之后,社区随之形成,模式也迅速扩散开来。

同样是在2011年,Heroku的Adam Wiggins发布了12-Factor App8方法论,提出了在云环境中构建SaaS时应遵循的12条原则。
代码库、依赖项、配置、后端服务、无状态进程等,这些原则明确规定了MSA实际运作所需的运营基础。
6. 容器革命——基础设施跟上了步伐
将MSA作为概念理解与实际运营之间存在巨大差距。部署、隔离和版本管理数百个服务,对于传统基础设施来说过于复杂且成本高昂。
2013年,Docker解决了这个问题。
"Hey everyone... I'm Solomon, I work at dotCloud[00:08]... we've been working on open sourcing that [Linux containers] and we haven't shown it to anyone[02:06]... this is actually the first time we show anything outside of the dotCloud office so it's probably going to blow up on me.[02:11]" - Solomon Hykes,
"The future of Linux Containers" (PyCon 2013 Lightning Talk)9
大家好……我是在 dotCloud 工作的 Solomon[00:08]……我们一直在做将 Linux 容器开源的工作……还从未向任何人展示过[02:06]……这是第一次在 dotCloud 办公室以外的地方进行演示,所以可能会当场翻车。[02:11]
Solomon Hykes
Solomon Hykes在PyCon 2013上用一个5分钟的演示介绍了Docker,当时很多人的反应是"不知道这是什么,但感觉很重要"。容器这个概念本身并不新鲜,Linux的cgroups和namespaces早已存在。Docker的创新在于,它将容器变成了开发者真正能用得上的工具。
Docker出现之后,将MSA的每个服务打包为独立容器成为可能。依赖项被隔离在镜像内部,同一镜像可以在开发环境和生产环境中以完全一致的方式运行。
随之而来的是下一个问题:如何管理数以百计的容器?
2014年,Google发布了Kubernetes。
We present a summary of the Borg system architecture and features, important design decisions, a quantitative analysis of some of its policy decisions, and a qualitative examination of lessons learned from a decade of operational experience with it.
我们对Borg系统架构与特性、重要设计决策、部分策略决策的定量分析,以及十年运营经验所得教训的定性考察进行了总结。
参考文献:Large-scale cluster management at Google with Borg (2015)10
事实上,Google早在十余年前就已在内部运行着一套名为 'Borg(博格)' 的系统,每周负责调度和管理数十亿个容器。
Kubernetes正是Borg的精神传承。
Docker与Kubernetes的组合,使MSA真正成为可落地的方案。那些此前只有拥有Netflix级别基础设施团队才能实现的事情,如今小型团队也可以做到了。
题外话:名称中隐藏的隐喻与英语世界的文字游戏
Kubernetes这个词本身在古希腊语中意为"舵手(Helmsman)"或"船长"。其中蕴含着Google宏大的世界观与隐喻。
Docker的Logo让人联想到"载着集装箱在海上游弋的鲸鱼(船舶)"。而Kubernetes的寓意,则是让漂浮在这片海洋上成百上千个集装箱(Docker)不相互缠绕、顺利抵达正确目的地,扮演指挥整个船队的舵手角色。(实际上,其官方Logo也正是蓝色的"船舵(Steering Wheel)"造型。)
Kubernetes通常也被称为"k8s",这是因为"K"与"s"之间恰好有8个字母(u-b-e-r-n-e-t-e),所以将其缩写为k8s。在英语环境中,通常发音为"K-eights"。
事实上,这种缩写方式是IT行业由来已久的惯例,称为"数字缩略词(Numeronym)"。由于每次都要输入长单词太过麻烦,便只保留首尾字母,中间用数字代替。
i18n:internationalization(国际化)→ i + 18个字母 + n
a11y:accessibility(可访问性)→ a + 11个字母 + y
o11y:observability(可观测性)→ o + 11个字母 + y
不过,广泛用于轻量级本地/边缘场景的 K3s 并非缩写。最初创建 K3s 的 Rancher Labs(现为 SUSE)的开发者们设定了这样一个目标:"打造一个将 Kubernetes 的内存占用和二进制文件大小精确缩减为原来一半的版本!"
Kubernetes 共10个字母,其一半是5个字母,按照前面提到的数字缩写规则压缩这5个字母,就得到了 K + 3个字母 + s = k3s 这一神奇的逻辑。
这就是为什么非英语母语的开发者学习开发会如此艰难。
7. 现状与下一个挑战
随着MSA的普及,新的问题逐渐浮出水面。
可观测性(Observability)。 当一个请求经过10个服务处理时,如何判断延迟发生在哪个服务。在单一进程中,一个栈追踪就能看清全貌,而在MSA中,痕迹会在每个服务边界处中断。分布式追踪(Jaeger、Zipkin、OpenTelemetry)正是为解决这一问题而生的工具。
服务网格(Service Mesh)。 当服务数量增多时,在每个服务中分别实现服务间通信策略(加密、重试、超时、熔断器)会非常低效。Istio、Envoy、Linkerd 将这些逻辑抽离为 Sidecar 代理,在服务代码之外统一处理。
分布式单体(Distributed Monolith)。 这是MSA最常见的陷阱。将服务拆分成多个之后,如果这些服务以同步方式形成长链调用,即A调用B、B调用C、C调用D,实际上一个请求会串行地穿越所有服务。一旦某个服务变慢,整条链路就会阻塞。这不过是把Monolith搬到了分布式环境中,耦合度丝毫没有降低。
这个陷阱之所以重要,是因为MSA的核心目标「独立部署」与「独立扩缩容」都取决于服务边界是否划分正确。边界划错了,只会得到分布式带来的复杂性,却享受不到任何好处。
这里有一点很重要:不能把MSA简单地看作「更好的架构」。从Monolith到SOA再到MSA的演进,并不是一个寻找更优解的过程,而是在每个阶段选择不同类型复杂性的过程。编程的本质,是缩小可选的状态空间;架构亦然。每写下一行代码,都是在限制自由度,而编程正是不断施加这种限制、并衡量它与我们需求契合程度的过程。Monolith放弃了部署与扩缩容的自由度,换来了简单性;SOA尝试拆分服务,却选择了集中化控制;MSA放弃了集中化,代价是承担运维复杂性。也就是说,MSA并非「更好的结构」,而是选择了另一种约束的结果。
结语:从历史中读出的规律
如果用一句话概括MSA的历史,那就是:
从Monolith的耦合问题出发,规避了SOA过度集中化的弊端,最终在云与容器基础设施之上以实用的形态落地的架构。
从历史中可以读出一种规律。
时代 | 核心技术 | 解决的问题 | 引入的问题 |
|---|---|---|---|
2000年代初 | Monolith | 简单性、快速开发 | Deployment coupling / Scaling coupling / Team coupling |
2002~2008 | SOA + ESB | 服务拆分尝试 | ESB 中心化,SOAP 复杂性 |
2009~2013 | MSA 早期(Netflix、Amazon) | 实现真正的独立部署与扩缩容 | 运维复杂性,可观测性缺失 |
2013~2015 | Docker + Kubernetes | 基于容器的基础设施标准化 | 编排学习成本 |
2016~至今 | Service Mesh、Observability | 服务间通信策略 + 可见性 | 复杂性增加 |
每一层都在解决上一层问题的同时,创造了新的问题。技术演进始终以这种方式推进。
因此,如果有人问"我们也应该转向MSA吗?",这个问题本身就问错了。架构领域不存在无条件的正确答案,也没有所谓的银弹(Silver Bullet)。
正确的问题应该是这样的:"我们当前的业务规模和组织结构,是否迫切需要在部署与扩展上获得更大的自由度,以至于值得为MSA所要求的巨大'运营复杂性'买单?"
如果马厩里一头牛都没有,Monolith的简洁性就是正确答案。但如果流量与开发团队爆炸式增长,已经到达无法承受原有耦合度的临界点,那时就必须主动选择容器与分布式系统的复杂性。
归根结底,设计系统架构并不是寻找完美结构的旅程,而只是明智地选择当前组织能够承受、或者必须承受的"痛苦类型"。
但人类总是在不断重复错误的选择。
在没有问题的情况下,却因为"看起来更先进"而引入MSA;在问题已经明确的情况下,却因为"习以为常"而坚守Monolith。技术是一个选择的问题,但大多数失败并非源于选择本身,而是源于判断失误。
脚注
- Building Microservices: Designing Fine-Grained Systems [2 ed.] Fig1.2 ↩
- [1] James Lewis, Martin Fowler, "Microservices", 2014 https://martinfowler.com/articles/microservices.html ↩
- https://gist.github.com/chitchcock/1281611 ↩
- https://about.netflix.com/en/news/completing-the-netflix-cloud-migration ↩
- https://www.wired.com/2012/07/netflix-4/ ↩
- https://netflixtechblog.com/introducing-hystrix-for-resilience-engineering-13531c1ab362 ↩
- [1] Nicola Dragoni et al., "Microservices: yesterday, today, and tomorrow", 2017. ↩
- Adam Wiggins, "The Twelve-Factor App" https://12factor.net/ ↩
- https://www.youtube.com/watch?v=wW9CAH9nSLs ↩
- https://research.google/pubs/large-scale-cluster-management-at-google-with-borg/ ↩