
(《宝可梦 绿》,以善用毒著称的妙蛙花)
有用的预备知识
本文假定读者对位运算和内存结构有基本的了解。只需记住以下四点,就能顺畅地跟上正文内容。
1. 位与字节
位(bit)是只能取 0 和 1 两种值的最小信息单位。8 个位组成 1 个字节(byte),1 字节可以表示 2⁸ = 256 种值,即 0 到 255。
位数 | 可表示的值的范围 | 实际使用示例 |
|---|---|---|
1 位 | 0~1 | 开/关,有毒/无毒 |
2 位 | 0~3 | 4 个方向 |
3 位 | 0~7 | 睡眠回合数 |
4 位 | 0~15 | 剧毒累计次数 |
8 位 | 0~255 | 一个字符,一个小计数器 |
本文的核心问题是:「如何将这 8 位或 32 位的空间拆分,以存储多种信息」。例如,低 3 位用于睡眠回合数,接下来的 1 位表示中毒,再下一位表示灼伤,依此类推。
2. 位掩码与移位
既然把数据拆开存入了各个位,就需要再把它们取出来使用。这时用到的基本操作就是掩码(masking)和移位(shift)。
掩码操作的作用是只保留特定的位。将想要保留的位置为 1 的值称为掩码,将原始值与之进行 & 运算后,掩码中为 1 的位得以保留,其余位全部清零。
举个例子,假设一个名为 status1 的 32 位值中,第 8~11 位存放着剧毒计数器。提取这四个位的掩码是 0xF00。十六进制的 F 对应二进制的 1111,因此 0xF00 就是只有第 8~11 位为 1 的值。
status1 = 0x12345678;
mask = 0x00000F00;
counterBits = status1 & mask; // 0x00000600
经过这一操作,status1 中只有第 8~11 位被保留,其余位全部变为 0。
但此时得到的结果值 0x600 并不等于实际的数字 6,而是「6」这个值向左移了 8 位的状态,也就是说内部以 6 << 8 = 0x600 的形式存储着。
因此,要将其作为实际数字使用,还需要向右移 8 位。
counter = (status1 & 0xF00) >> 8; // 6本文中反复出现的模式如下(建议记住):
value = (packed & mask) >> shift;反过来,写入值时,需要先清除原有值,再将新值左移,最后用 | 运算合并。
status1 = (status1 & ~0xF00) | (newCounter << 8);也就是说,读取时以 & 和 >> 为基础,写入时以 << 和 | 为基础。
结构体填充(padding)
在 C 语言中,结构体在将成员布局到内存时,会进行对齐(alignment),使 CPU 能以最优方式访问。这个过程中,成员之间会产生空白区域,称为填充(padding)。
以下面这个结构体为例。
struct Example {
char c; // 1字节
int i; // 4字节
bool b; // 1字节
};
从表面上看,数据似乎只有 1 + 4 + 1 = 6字节,但在大多数环境中,int 需要对齐到 4 字节边界。因此,char 之后会插入 3 字节的填充,结构体末尾也可能追加填充以满足整体对齐要求。
最终,实际的结构体大小可能达到 12 字节。
实际数据:1 + 4 + 1 = 6字节
padding:3 + 3 = 6字节
合计: 12字节bit field 是一种将多个小型标志位和计数器集中放入一个字(word)中,从而减少这类浪费的方法。
简单来说,可以把它理解为打包行李时把每一寸空间都塞得满满当当的方式。
4. 缓存行(cache line)
CPU 从内存读取数据时,并不会只取出所需的 1 个字节,而是一次性取来通常以 64 字节为单位的数据块,这个单位就称为缓存行(cache line)。
如果读取的数据不在缓存中,就必须前往主内存获取,这一延迟可能高达数十乃至数百个时钟周期;而已经加载到 L1/L2 缓存中的数据则可以快速访问。
因此,将频繁一起使用的数据集中存放在同一条缓存行中非常重要。数据分散时需要加载多条缓存行,而集中存放则可以通过一次缓存行加载同时取得所有所需的值。
在这里,只需把缓存行理解为一块比内存访问稍快的存储空间,就足以读懂下文了。
引言:内存明明充裕,为什么还要抠比特?
「内存都 32GB 了,为什么还要把这些布尔值塞进 bit field 里?」
这是每个现代软件工程师都曾思考过的问题。不管 padding 怎么浪费,用整整 1 个字节明明绰绰有余,可游戏引擎和 ECS 库至今仍将小值塞进同一个 word 里。
也许你会这样想:「AI 时代内存价格一路飙涨,不省着点用怎么行?」现实确实如此,AI 时代的内存价格已水涨船高,我自己的钱包也快撑不住换电脑了。
但也有人会反问:「硬件不断进步,这种复古技巧还能用多久?缓存越来越大,RAM 越来越快,最终不都会迎刃而解吗?」
然而,真正的答案在这两种说法里都找不到。那么多开源项目精打细算地抠比特,原因既不是 RAM 容量不够,也不是在逆硬件发展潮流而动,而是与一个更根本、更古老的问题紧密相连。
为了回答这个问题,让我们穿越回最能直观感受到这种需求的年代。
1996 年,Game Boy 的 8KB RAM。
宝可梦就是最典型的例子。睡眠回合数占 3 个 bit,中毒、灼伤、冰冻、麻痹各占 1 个 bit,全部挤进 1 个字节。剧毒每回合伤害递增,需要单独的计数器来追踪累计次数,1 字节状态字节里已无处安放,只好在战斗中拆出去另用一块独立内存存储。
而到了 GBA(2002 年),RAM 扩大到 256KB,整整翻了 32 倍,STATUS1 字段也扩展到了 32 位。尽管如此,剧毒计数器并没有被拆分成一个独立的整数字段。
这里产生了一个疑问:容量问题既然已经解决,为什么还要这样做?
而回到现代,疑问就更大了。时隔 30 年,游戏引擎至今仍在拆分比特位。
本文就是追寻这个疑问的过程。从 1996 年的 8KB 出发,到 2026 年的 64 字节 cache line,按照空间、设计、带宽的顺序逐一审视。
1. 空间的制约:Game Boy 的 1 字节(1996)
初代宝可梦运行的 Game Boy,工作 RAM 只有 8KiB。
8,192 字节。
如今保存这篇文章的一个文本文件就要几十 KB,而 Game Boy 却必须在不到其一半的空间里跑起整个游戏状态。
6 只队伍精灵的种族值、个体值、技能、HP、异常状态,战斗中两只精灵的全部状态,再加上屏幕显示缓冲区,这一切都要塞进 8KiB 之内。分配给单只精灵异常状态的空间只有区区 1 字节,8 个 bit 就是全部。
那么,过去的程序员究竟是如何做到这一切的?代码来自下面的 Git 地址。
查看 pret 的 Game Boy 反汇编项目 pokered 中的 constants/battle_constants.asm,可以看出当年程序员的聪明才智,那 1 字节是这样划分的。
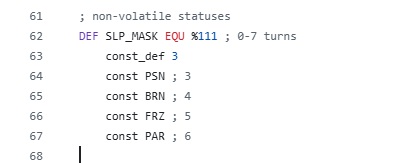
DEF SLP_MASK EQU %111 ; 비트 0-2, 수면 턴수
const PSN ; 비트 3, 독
const BRN ; 비트 4, 화상
const FRZ ; 비트 5, 얼음
const PAR ; 비트 6, 마비
细心的读者可能已经注意到,bit 0~2 与其他 bit 有所不同。
中毒、灼伤、冰冻、麻痹的逻辑很简单,只需知道是否处于该状态,因此各占 1 bit 就够了。一个 bit 只能表示 0 或 1,正好可以用来表示"是否中毒""是否灼伤"这类二元状态。
但睡眠状态不同。睡眠不只是简单的"正在睡觉",还需要记录"还要再睡几回合"。也就是说,需要的不是开/关标志,而是一个数值。若要表示最多 7 回合,就必须能存下 0~7,而 0~7 恰好可以用 3 个 bit 来表示。
1位 = 0~1
2位 = 0~3
3位 = 0~7因此,初代宝可梦异常状态的 1 字节中,bit 0~2 分配给睡眠回合数,其后的各 bit 依次对应中毒、灼伤、冰冻和麻痹。
归根结底,决定 bit 宽度的是所需表示的值的范围。像中毒这种真/假状态只需 1 bit,像睡眠这种需要 0~7 的数值则需要 3 bit。不过熟悉宝可梦的读者可能会说:

"没有剧毒?"
剧毒是什么?它是一种毒,但随着回合数的增加,伤害会不断增强的毒。
剧毒与普通中毒不同。普通中毒每回合受到固定伤害,而剧毒随着回合推进伤害会逐渐增大。普通中毒只需知道"是否中毒",因此一个 PSN bit 就足够了。但剧毒不仅要判断"是否为剧毒",还需要单独记录"当前是第几个剧毒回合"。也就是说,剧毒并非简单的 1 bit 状态,而是同时需要一个标志位和一个计数器的复合状态。
初代宝可梦的基础状态异常字节中,已经塞入了睡眠的 3 bit、以及毒/灼伤/冰冻/麻痹标志位。再放入剧毒计数器的空间已经没有了。因此,剧毒并没有被强行塞进存档用的状态字节,而是被拆分为仅在战斗中使用的独立标志位和计数器。
实际代码也是如此划分的。BADLY_POISONED 并非定义在基本状态异常字节中,而是作为 wPlayerBattleStatus3 或 wEnemyBattleStatus3 的 bit 标志位来定义的。
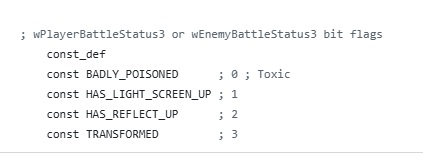
; wPlayerBattleStatus3 or wEnemyBattleStatus3 bit flags
const_def
const BADLY_POISONED ; 0 ; Toxic
const HAS_LIGHT_SCREEN_UP ; 1
const HAS_REFLECT_UP ; 2
const TRANSFORMED ; 3这个 bit 用于标记"当前这个中毒是否为剧毒?"。但仅凭这一点还不够。剧毒每回合造成的伤害会逐渐增加,因此还需要一个单独的计数器来记录当前是第几回合的剧毒状态。
该计数器出现在 pokered/engine/battle/core.asm 的战斗伤害处理代码中。玩家方使用 wPlayerToxicCounter,对手方使用 wEnemyToxicCounter。
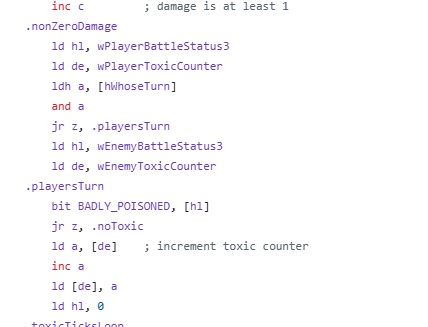
.nonZeroDamage
ld hl, wPlayerBattleStatus3
ld de, wPlayerToxicCounter
ldh a, [hWhoseTurn]
and a
jr z, .playersTurn
ld hl, wEnemyBattleStatus3
ld de, wEnemyToxicCounter
.playersTurn
bit BADLY_POISONED, [hl]
jr z, .noToxic
ld a, [de] ; increment toxic counter
inc a
ld [de], a
ld hl, 0按顺序来看会更清楚。那么,我们来整理一下顺序,方便理解。
1. PSN 位 - 位于存档用状态异常字节中 - 表示"中毒"
2. BADLY_POISONED 位 - 位于 BattleStatus3 中 - 表示"此毒为剧毒"
3. ToxicCounter - wPlayerToxicCounter / wEnemyToxicCounter - 存储"当前处于第几回合剧毒状态"
首先,基本状态异常字节中的 PSN 位标记"已中毒"这一事实。接着,BattleStatus3 中的 BADLY_POISONED 位标记"该毒不是普通毒,而是剧毒"。最后,wPlayerToxicCounter 或 wEnemyToxicCounter 计数"当前处于第几回合的剧毒状态"。
这是多么麻烦和繁琐啊。真的让人庆幸自己没有生活在那个年代,同时也对那个年代的前辈程序员们深感钦佩。
总之,这一阶段的位压缩不需要什么宏大的理由。Game Boy 的工作 RAM 只有 8 KiB,就连表示一个状态时,也必须不断计算"这个值用几位就够了"。这时的位压缩,不是为了炫技,而是为了生存。
2. 设计约束:即使有了32位,为何仍要拆分比特位
随后,宝可梦从 GB(Game Boy)过渡到了 GBC(Game Boy Color)。第二代金/银的工作 RAM 为 32KiB,是初代 Game Boy 的 8KiB 的 4 倍。
但基本状态异常字节几乎没有变化。睡眠仍然占用低3位,中毒、灼伤、冰冻、麻痹各占1位。剧毒也还未纳入这个字节中。普通中毒状态由 PSN 位标记,"这个毒是否为剧毒"由 SubStatus5 中的 SUBSTATUS_TOXIC 位标记,累计次数则由 wPlayerToxicCount 和 wEnemyToxicCount 这两个独立计数器记录。
; wPlayerSubStatus5 or wEnemySubStatus5 bit flags
const_def
const SUBSTATUS_TOXIC
const_skip
const_skip
const SUBSTATUS_TRANSFORMED
const SUBSTATUS_ENCORED
const SUBSTATUS_LOCK_ON
const SUBSTATUS_DESTINY_BOND
const SUBSTATUS_CANT_RUN
从第二代宝可梦的实际代码中可以印证这一点。
这里的关键问题是:「RAM 扩大了 4 倍,为什么还要这样做?」由于日本的宝可梦开发者从未公开说明,细节无从得知,但个人推测,这或许是因为引擎代码直接继承自上一代。此外,由于金/银等第二代与红/绿/蓝等第一代之间需要通过「时间胶囊」进行交换,数据格式越相近,后续实现就越便利。当然,第二代宝可梦或学会了第二代技能的宝可梦无法转移,因为只有第一代能够识别的数据才能通过。而一旦数据布局被固定下来,它实际上就成了「硬编码的 API 规范」。一旦修改布局,第一代的数据流入第二代时,整个系统就会崩溃。这正是我们在实际工作中遭遇的「遗留代码的泥沼」,也是过去的约束成为未来合约的时刻。而后,在 2002 年,GBA 版《红宝石/蓝宝石》正式发售。
查看 pret 的 pokeruby 项目中的 include/constants/battle.h,可以看到状态异常字段的定义如下。
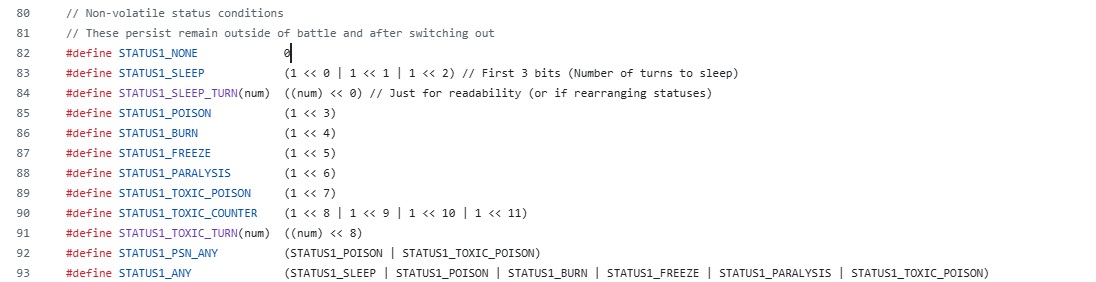
// Non-volatile status conditions
// These persist remain outside of battle and after switching out
#define STATUS1_NONE 0
#define STATUS1_SLEEP (1 << 0 | 1 << 1 | 1 << 2) // 睡眠剩余回合数
#define STATUS1_SLEEP_TURN(num) ((num) << 0) // Just for readability (or if rearranging statuses)
#define STATUS1_POISON (1 << 3)
#define STATUS1_BURN (1 << 4)
#define STATUS1_FREEZE (1 << 5)
#define STATUS1_PARALYSIS (1 << 6)
#define STATUS1_TOXIC_POISON (1 << 7)
#define STATUS1_TOXIC_COUNTER (1 << 8 | 1 << 9 | 1 << 10 | 1 << 11)
#define STATUS1_TOXIC_TURN(num) ((num) << 8)
GBA 的 STATUS1 是 32 位的,但低位的 bit 排列几乎原封不动地沿用了 Game Boy 那个 1 字节状态字节的布局。
bit 0 到 2 存放睡眠回合数,bit 3 到 6 分别表示中毒、灼伤、冰冻、麻痹。变化在于:bit 7 新增了「是否为剧毒」的标志,bit 8 到 11 则存放剧毒的累计计数器。
然而这个 status1 字段的类型是 u32。实际用到的只有 bit 0 到 11,也就是 12 个 bit,高位的 20 个 bit 全部空置。GBA 的 EWRAM 为 256KiB,是初代 Game Boy 8KiB 的 32 倍。也就是说,到了这个阶段,bit 压缩已经不能单纯用「要节省每一个字节」来解释。明明有足够的空间让 20 个 bit 闲置,状态信息却依然按 bit 为单位进行拆分。
至此,bit 压缩的性质发生了转变。如果说初代宝可梦的压缩是为了在 8KiB RAM 中塞入数据的生存技巧,那么《红宝石/蓝宝石》的压缩更接近于一种布局设计,目的是在单个字 (word) 内统一管理状态。睡眠回合数、中毒、灼伤、冰冻、麻痹、是否为剧毒、剧毒累计次数,全部收纳在 STATUS1 这一个字中。
从处理剧毒伤害的实际代码中,这一意图会更加清晰。在《红宝石/蓝宝石》的回合结束处理中,剧毒伤害的计算方式如下。以下是去掉完整原文、只保留核心逻辑的简化版本。

case ENDTURN_BAD_POISON: // toxic poison
if ((gBattleMons[gActiveBattler].status1 & STATUS1_TOXIC_POISON)
&& gBattleMons[gActiveBattler].hp != 0)
{
gBattleMoveDamage = gBattleMons[gActiveBattler].maxHP / 16;
if (gBattleMoveDamage == 0)
gBattleMoveDamage = 1;
if ((gBattleMons[gActiveBattler].status1 & STATUS1_TOXIC_COUNTER)
!= STATUS1_TOXIC_TURN(15)) // not 16 turns
gBattleMons[gActiveBattler].status1 += STATUS1_TOXIC_TURN(1);
gBattleMoveDamage *=
(gBattleMons[gActiveBattler].status1 & STATUS1_TOXIC_COUNTER) >> 8;
BattleScriptExecute(BattleScript_PoisonTurnDmg);
effect++;
}
gBattleStruct->turnEffectsTracker++;
break;gBattleMoveDamage = gBattleMons[gActiveBattler].maxHP / 16; 这行代码将剧毒的基础伤害设为最大 HP 的 1/16。接下来检查 STATUS1_TOXIC_COUNTER,该掩码仅保留第 8~11 位。若当前值不等于 STATUS1_TOXIC_TURN(15),即计数器尚未达到 15,则累加 STATUS1_TOXIC_TURN(1)。由于 STATUS1_TOXIC_TURN(n) 等价于 n << 8,实际上是将存储在第 8~11 位中的小整数加一。
最后一行正是这套 bit 布局的精髓所在。
(gBattleMons[gActiveBattler].status1 & STATUS1_TOXIC_COUNTER) >> 8 首先通过 & STATUS1_TOXIC_COUNTER 取出第 8~11 位,但此时该值仍向左偏移了 8 位,因此再通过 >> 8 向右移回,还原为实际的回合数,然后将其乘以最大 HP 的 1/16。第 1 回合造成 1/16,第 2 回合造成 2/16,第 3 回合造成 3/16。从这个过程中,可以推断出「为什么恰好是 4 位」的答案。
为什么偏偏是 4 位?剧毒的累计伤害不可能无限增长。分配 4 位的原因在于,0 到 15 的范围已经足够:若不进行回复,第 6 回合受到 6/16 伤害时累计已超过最大 HP(总计 21/16),即便考虑常规回复手段,15 回合也绰绰有余。代码也专门将计数器饱和 (Saturate) 在 15,防止其继续增大、溢出到高位 bit 造成错误。
归根结底,bit 的宽度由需要表示的值的范围 (Domain Range) 决定。真/假只需 1 位,0~15 的整数恰好需要 4 位。而 4 位,正好是足以让一只宝可梦中毒后被送进宝可梦中心的范围。
因此,这一阶段的约束并非空间约束,而是布局约束。曾经因 RAM 不足而催生的 bit 排布,在内存变得宽裕之后,以一种表达和访问状态的固有方式延续了下来。
布局一旦固化进直序列化格式和通信协议,就很难再更改。因为移动一个 bit 的位置,存档兼容性和通信兼容性便会随之破裂。由 8KiB 限制催生的布局,在约束消失之后,以技术债和契约的形式继续存活。现实中,我们也常常会因为「现有做法运转得足够好」而沿用旧有习惯,尽管本可以加以改进。有人或许称之为惯例的束缚,但笔者更愿意将其称为设计的约束。
3. 带宽的约束:为 cache line 而做的 bit 压缩(现代)
第三种约束是什么?内存已经足够充裕,但 CPU 与内存之间的速度差距成了瓶颈,而填补这一差距的正是缓存。
CPU 以 64 字节 cache line 为单位读取内存。若所需数据不在缓存中(cache miss),就必须访问主内存,这意味着数百个时钟周期的延迟。关于 cache line 的工作原理以及数据布局为何决定性能,Ulrich Drepper 的 "What Every Programmer Should Know About Memory" 已作出经典梳理。为避免过度展开,简而言之:CPU 获取数据时,数据越紧凑(密度越高),一次 cache line 加载所携带的有效信息就越多。反之,若数据稀疏分散,cache line 中便充斥着"无用空白",CPU 只能反复往返主内存,白白耗费数百个时钟周期。bit 压缩,正是决定 CPU 每次内存加载能传递多少有效数据的关键手段。
这个例子若能继续用宝可梦来说明会更好,但 Switch 世代(剑盾、朱紫)没有官方反编译版本,无从得知状态异常究竟仍以 bit field 字形式存储,还是已拆解为普通字段,因此不妨借助现代游戏引擎的演变来观察 bit 压缩技术的变化。
游戏与模拟领域的数据导向设计(DOP)和 ECS,出发点也是如此。
现代 C++ ECS 库 EnTT 并不将实体标识符拆分为两个字段,而是将 id 与 version 以 bit 的形式共同存入一个整数中。

[[nodiscard]] static constexpr value_type construct(
const entity_type entity,
const version_type version
) noexcept
{
if constexpr(Traits::version_mask == 0u) {
return value_type{entity & entity_mask};
} else {
return value_type{
(entity & entity_mask)
| (static_cast<entity_type>(version & version_mask) << length)
};
}
}这段代码与神奇宝贝的 STATUS1_TOXIC_COUNTER 采用相同的方式。通过 entity & entity_mask 保留 id 区域,再将 version & version_mask 左移 length 位,放入高位 bit。取出时同理:id 通过掩码取出,version 通过位移和掩码取出。
如果按照面向对象的惯常做法,将 isPoisoned、toxicTurnCount 等字段分散存储在每个对象中,每次访问都可能触发 cache miss。将多个状态标志和计数器打包进一个 word,便可通过一次 cache line 加载和 bit masking 来判断状态,在某些情况下还为 SIMD 等并行处理策略提供了空间。正如 Eric Raymond 在《The Lost Art of Structure Packing》中所指出的,将布尔值集中压缩为 1 bit 虽然会带来一些额外的访问开销,但这些开销会被减少的 cache miss 所抵消。Mike Acton 在 CppCon 2014 的演讲《Data-Oriented Design and C++》中展示了数据布局对游戏引擎性能的巨大影响。
总结如下:1996年的Game Boy为了将数据塞进8KiB RAM,对bit进行了压缩。而2002年的红宝石/蓝宝石则将那套状态表示折叠进了32位的STATUS1之中。现代游戏引擎与ECS则再度对bit进行压缩,目的是在cache line中装入更多有效信息。
技术手法一脉相承:mask、shift、小字段。审视这些编程技巧,总会发现拆解到最小单元后看似简单。然而,将其真正拆解到最小单元并加以现代化,始终是一件困难的事。
宝可梦的状态异常 bit field 与 EnTT 的实体标识符,分属完全不同的时代,也解决着截然不同的问题。然而,在接近机器语言的层面上,它们共享着同一种语法:将多个小值打包进一个 word,通过 mask 和 bit shift 取出使用。这样做并非因为内存空间不足,而是因为数据的存储方式决定了执行成本。这么说来,或许会让人以为只有过去开发者的做法才是正确的,但事实并非如此。

(一个流传已久的梗:以前的开发者牛得离谱,现在的开发者全是废物。)
因为在现代多核环境中,"高密度"有时反而会成为一种负担。
CPU缓存以64字节为单位,将数据整块管理为"cache line"。如果多个线程同时运行,而分别由不同核心修改的字段恰好都挤在同一条cache line中,会发生什么?尽管逻辑上它们是不同的字段,但只要某一方写入数据,整条cache line就会立即失效。这便是所谓的"伪共享(False Sharing)"现象。
bit packing在以读取为主的单线程遍历中能够提升"数据密度",从而发挥出压倒性的性能;但在多线程环境下,则需要截然相反的策略。此时应当将打包的数据拆开,利用alignas(64)等说明符将热点字段单独放置到不同的cache line中。
归根结底,"是否要在bit层面紧密压缩以提升cache命中率",还是"为了避免线程竞争而在cache line粒度上隔离数据",取决于数据以何种路径(Access Pattern)流动,是架构师需要精细权衡的判断领域。
结论
起初,一切源于空间的压力。在Game Boy仅有的8KiB RAM中,若要表达睡眠回合数与状态异常,就必须精打细算每一个字节里的每一个bit。毒状态用1bit就够了,但睡眠需要记录回合数,因此要占3bit。剧毒光靠是否中毒还不够,还需要一个独立的计数器来累计回合数。那个年代的bit packing,是一种求生的挣扎。
其次,问题变成了布局。进入金/银世代后RAM增加了,但基本的状态异常字节几乎原封不动地保留了初代的形式。到了红宝石/蓝宝石,STATUS1扩展为32位,剧毒标志和剧毒计数器也一并折叠进去。尽管高位20个bit空着,状态依然以bit为单位排列。这一阶段的packing已不再是纯粹的容量节省。有人或许称之为惯性,但从代码理解状态的方式来看,这本质上是一个布局问题。
而在现代,核心是带宽。内存变大了,但CPU与内存之间的距离依然代价高昂。现代游戏引擎和ECS每帧都要遍历大量实体,此时数据在cache line中排列得多紧密,直接决定了性能高低。EnTT将实体id与version打包进一个整数,也是同一类判断。把小的值塞进一个word,再用mask和bit shift取出来使用。
话虽如此,如果只是因为某个早已消失的约束而继续削减bit,那不过是cargo cult。若cache是瓶颈却把数据松散地散布各处,就是在白白浪费性能。若多个线程争用同一条cache line,却还把数据塞得更紧,则可能因false sharing而适得其反。
归根结底,设计应当因约束而异。我一直在思考:程序员的思维方式究竟是什么?写这篇文章的过程中,我也试着给出了自己的答案,毕竟文章总要有个结尾。在我看来,程序员的思维方式是这样的:搞清楚自己面临的约束是什么,然后在那个环境内拼命找出最优解。
也许,这就是程序员该有的姿态?
参考资料
Eric S. Raymond,《The Lost Art of Structure Packing》(catb.org/esr/structure-packing)——关于对齐、padding与bit field packing的事实标准参考。
Ulrich Drepper,"What Every Programmer Should Know About Memory"(LWN,2007;lwn.net/Articles/250967)——关于cache line工作原理及数据布局如何决定性能的经典之作,第5节缓存论点的理论依据。
Mike Acton, "Data-Oriented Design and C++", CppCon 2014 (youtube.com/watch?v=rX0ItVEVjHc) — 讲解如何将数据按cache line对齐布局,从而提升游戏引擎性能的DOP演讲。
宝可梦代码参考:pret的GitHub
github.com
pretpret has 30 repositories available. Follow their code on GitHub.
